热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
RabbitMQ中的交换机
❤Nodejs 第十二章(图片存储接口-本地)
SpringBoot实现RabbitMQ的WorkQueue(SpringAMQP 实现WorkQueue)
微服务学习 | Spring Cloud 中使用 Sentinel 实现服务限流
Java编程:深入探索其原理、特性与实战代码
SpringBoot实现RabbitMQ的简单队列(SpringAMQP 实现简单队列)
Java编程语言入门指南
Golang数据库编程详解 | 深入浅出Go语言原生数据库编程
单片机原理与应用:探索微型计算机世界
Redis 搭建哨兵集群
vue3+ts+element home页面侧边栏+头部组件+路由组件组合页面教程
单片机:探索其原理、应用与编程实践
2024年了,还有必要搭建企业网站吗?
Python:编程的艺术与科学的完美交融
探索Gin框架:Golang Gin框架请求参数的获取
Python:简洁之美与强大之力的完美融合
阿里云备案流程和操作步骤详解(图文教程)
人工智能:重塑未来的力量之源
Go语言Gin框架安全加固:全面解析SQL注入、XSS与CSRF的解决方案
Vue3中的组件间通信:多种方法解析
聚力同行,阿里云与合作伙伴这一年
Java vs. Go:并发之争
“超越摩尔定律”,存内计算走在爆发的边缘
云端防御战线:构建云计算环境下的网络安全体系
Java与Go的生产者消费者模型比较
人工智能:探索未来,编写智慧
【SSM】如何查看生产上的错误日志
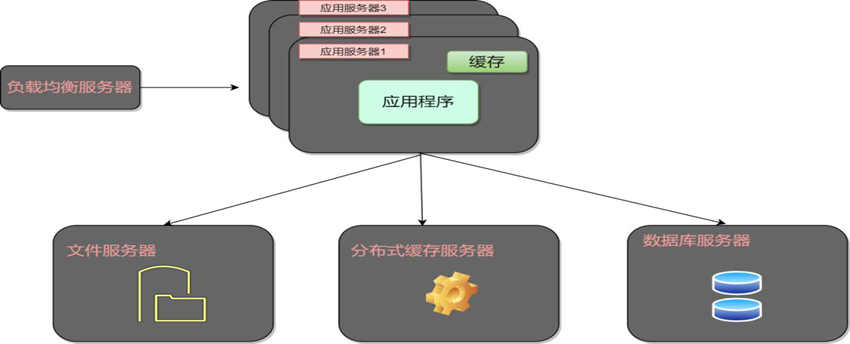
后端架构设计与优化:打造高性能应用后端
【git】如何删除git远程仓库上的文件
使用Python实现简单的Web服务器
阿里云亮相金蝶集团生态合作伙伴大会
【Activiti7】什么是工作流?
探索Gin框架:Golang使用Gin完成文件上传
后端开发:构建稳定高效的应用后端
vue3+ts白屏问题解决
响应式设计的原理与实践
Golang语言异常机制解析:错误策略与优雅处理
【SpringBoot】整合Mybatis
程序员缓解工作压力小技巧
Web前端开发:探索技术与艺术的交融
阿里云域名购买与域名解析使用教程(图文教程)
阿里云联合伙伴发起“物流智能联盟”
【SpringBoot】如何使用策略模式+抽象工厂+反射
探索Viper-适用于GoLang的完整配置解决方案
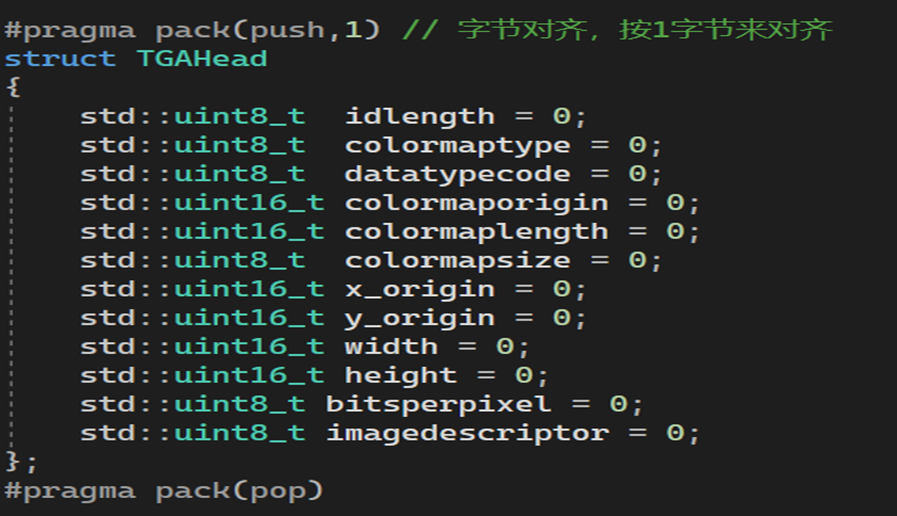
C++:深度解析与实战应用
【vue】v-if和v-show的区别