提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
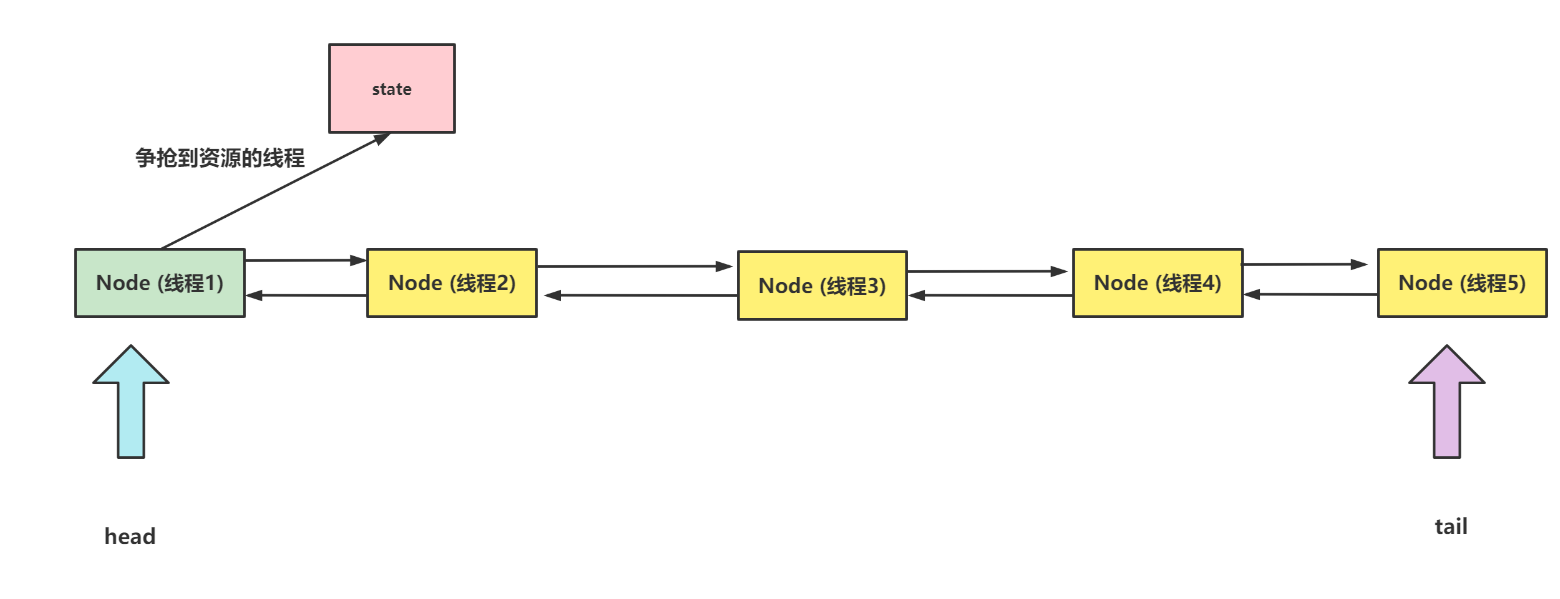
来聊聊AQS源码
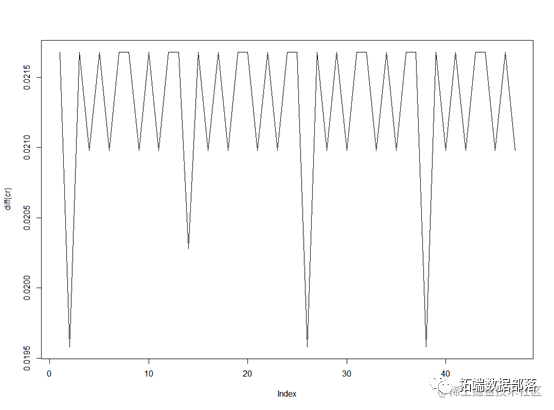
R语言用CPV模型的房地产信贷信用风险的度量和预测
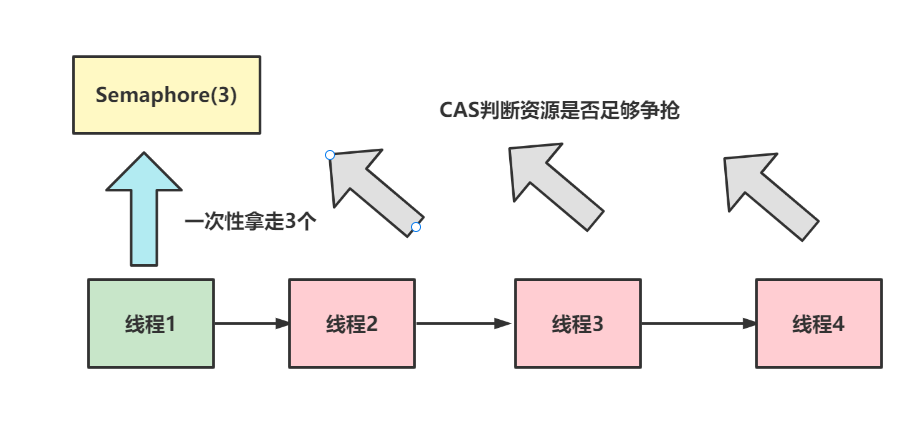
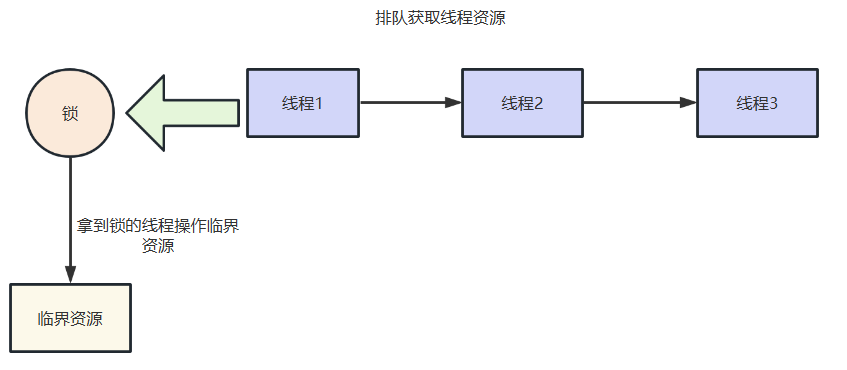
JUC常见并发流程工具总结
又重新搭了个个人博客
R语言Apriori关联规则、kmeans聚类、决策树挖掘研究京东商城网络购物用户行为数据可视化
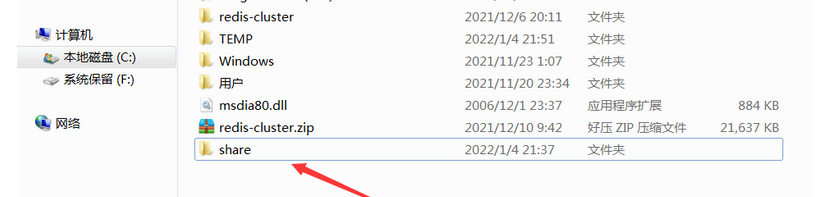
win环境下共享文件夹配置
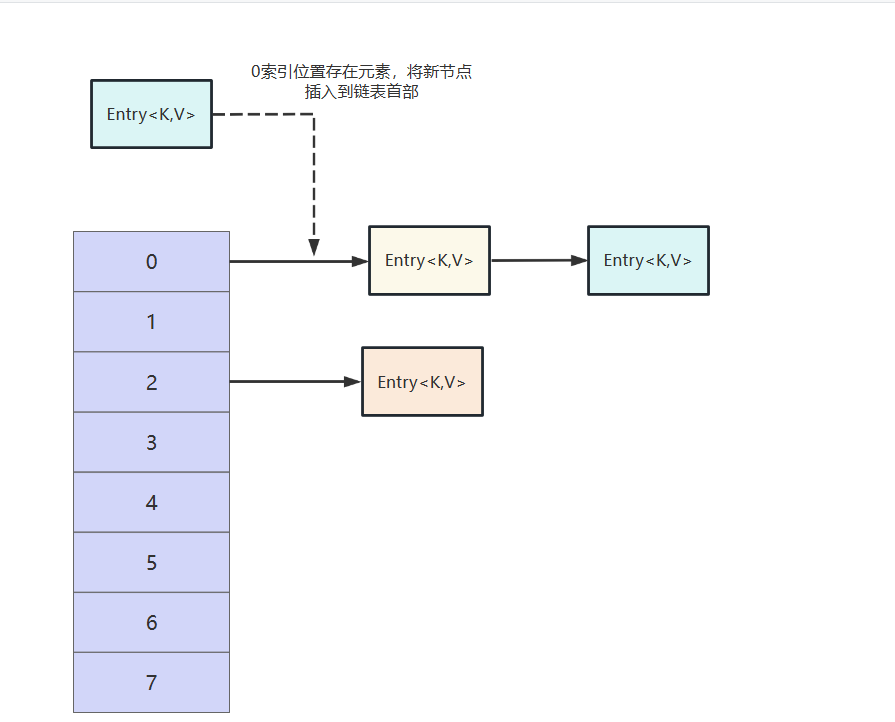
Java并发容器总结(下)
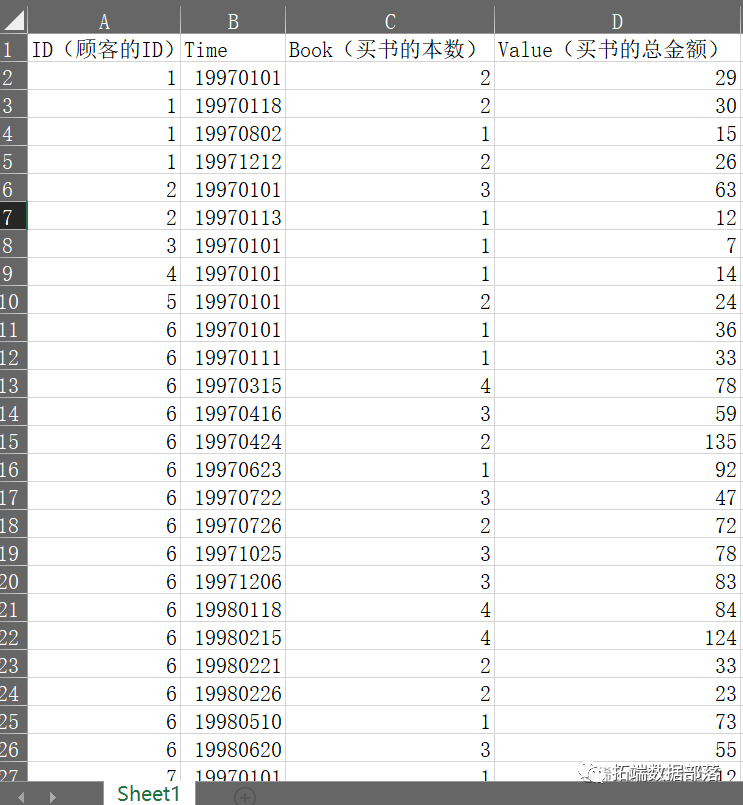
数据分享|R语言用RFM、决策树模型顾客购书行为的数据预测
Java并发容器总结(上)
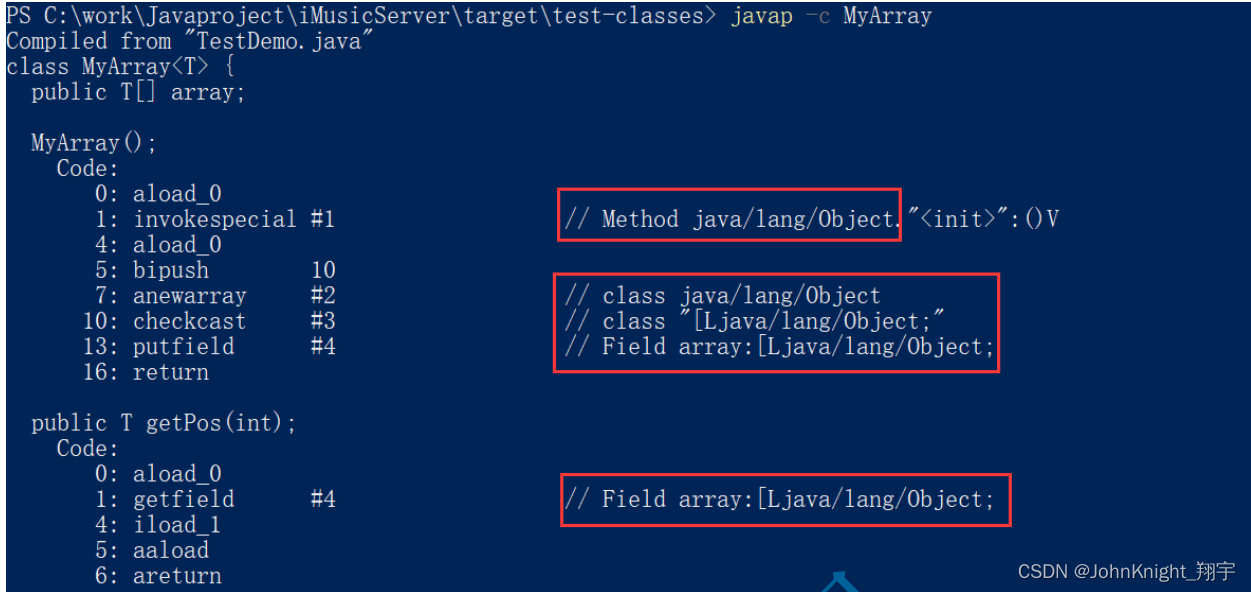
泛型的理解
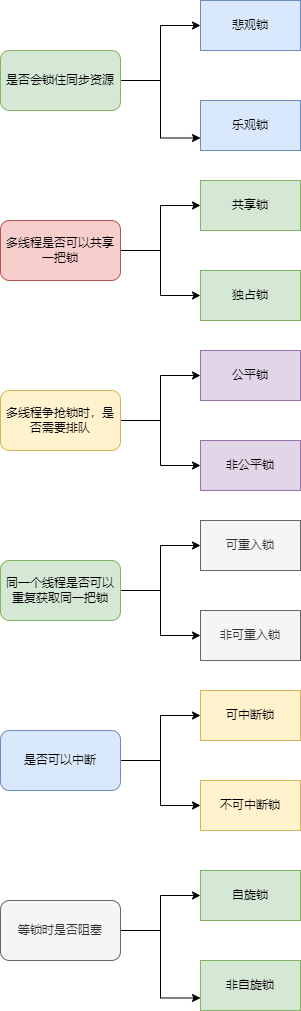
JUC包下各种锁使用详解(下)
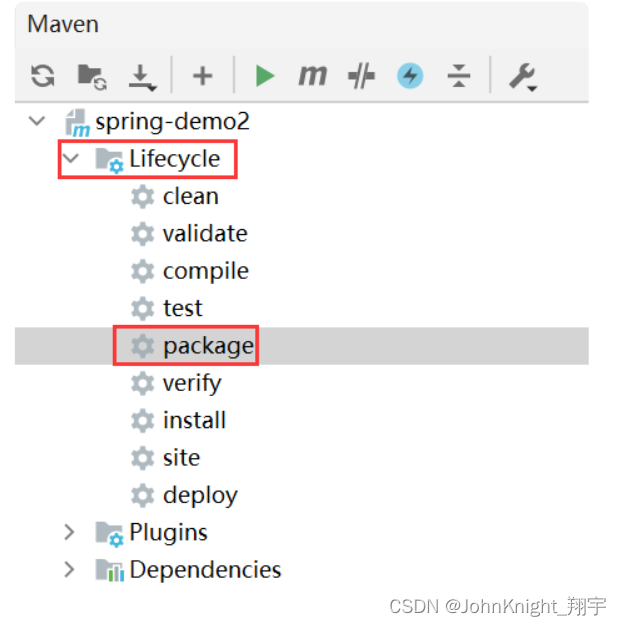
部署和发布
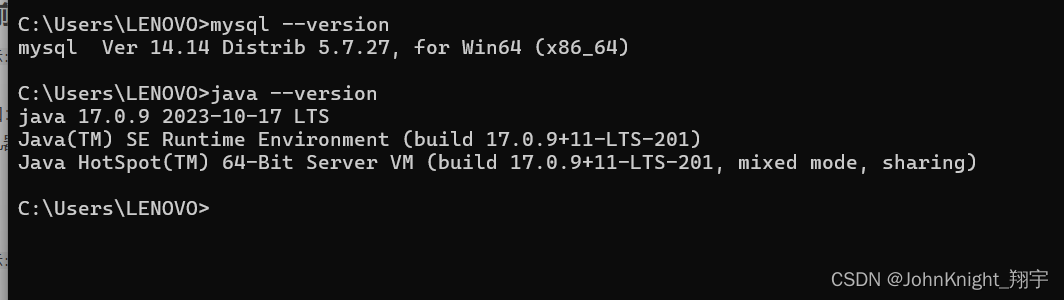
一些常见的Windows命令
JUC包下各种锁使用详解(上)
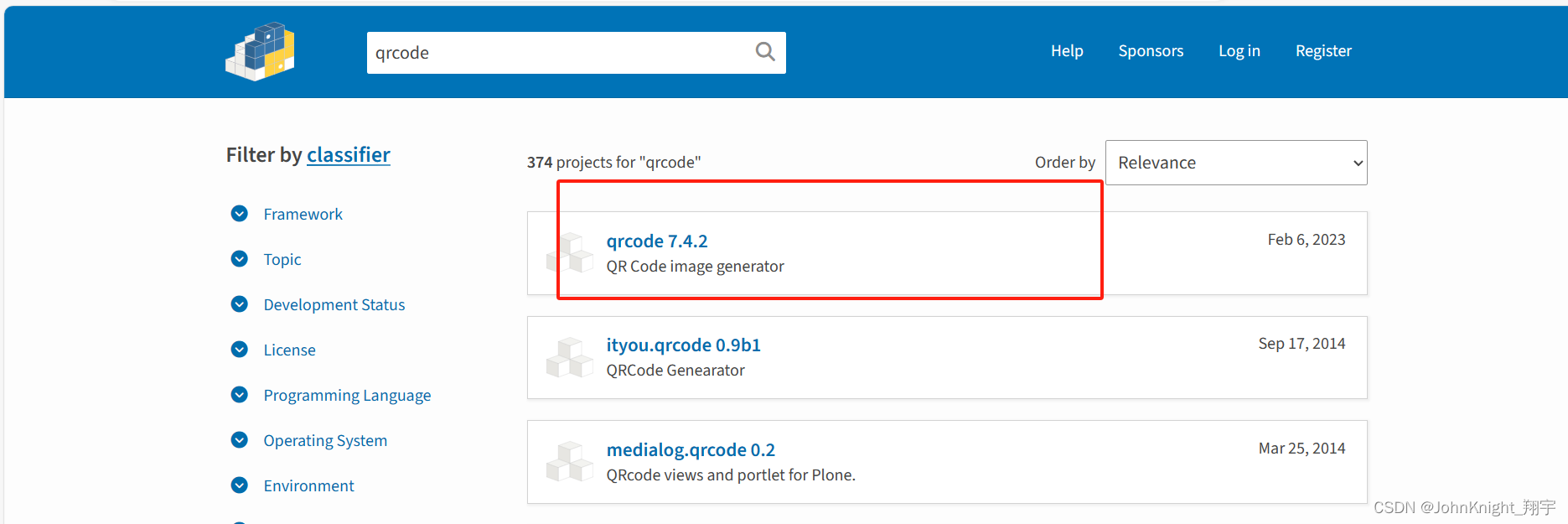
Python写个二维码
探索 DTD 在 XML 中的作用及解析:深入理解文档类型定义
@AllArgsConstructor,@NoArgsConstructor,@Data
写一篇关于captcha项目的代码
Java线程池详解(下)
SpringBoot:SpringMVC(下)
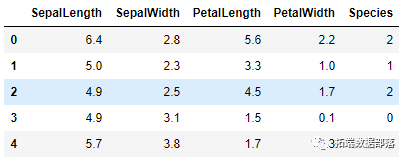
TensorFlow、Keras 和 Python 构建神经网络分析鸢尾花iris数据集|代码数据分享
Julia 语言环境安装
head 和body
Julia 教程
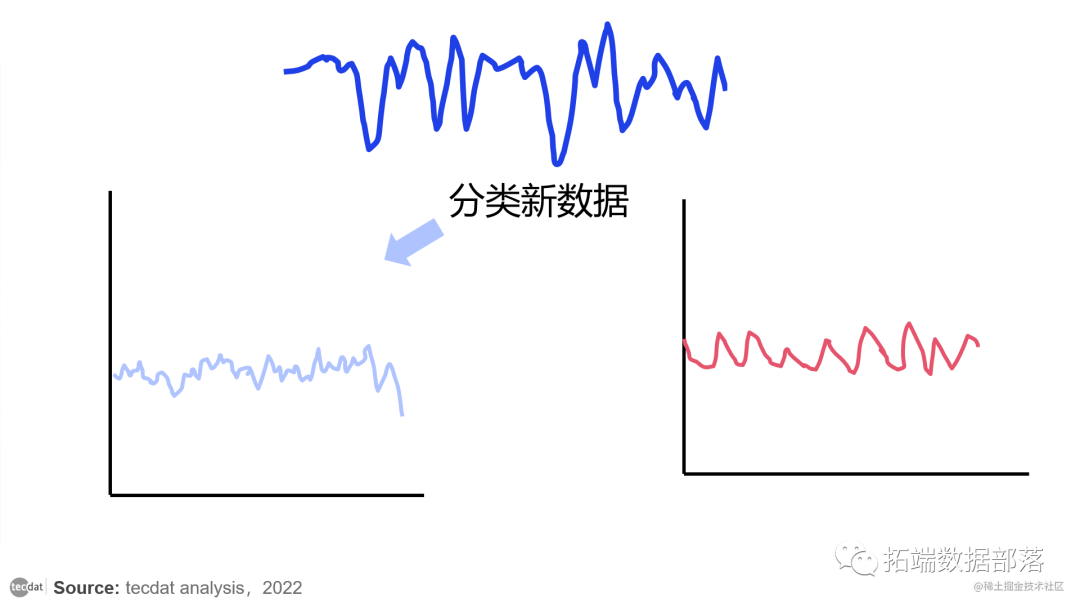
【视频】时间序列分类方法:动态时间规整算法DTW和R语言实现
{二分模板}
斐波那契(快速矩阵幂)
Java线程池详解(上)
Windows 10明年退役
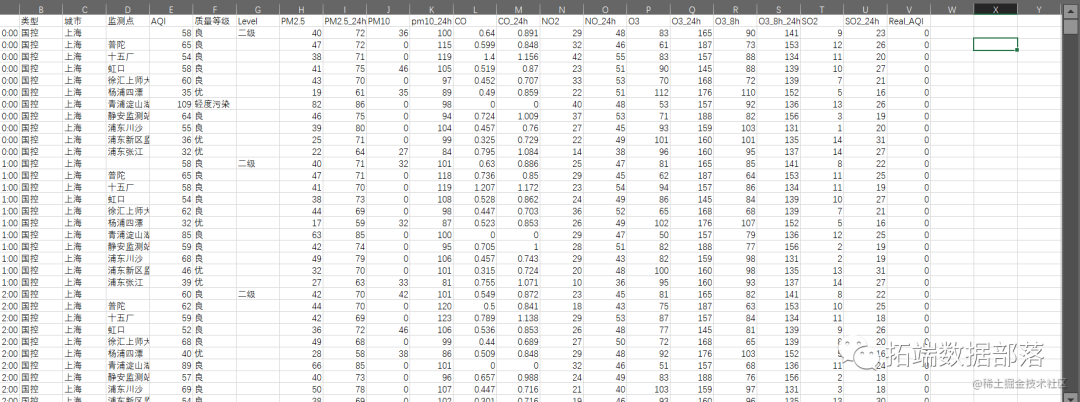
数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法
背包问题四种类型
来聊聊Java为什么只有值传递
Python安装TensorFlow 2、tf.keras和深度学习模型的定义
数据库模式(Schema)
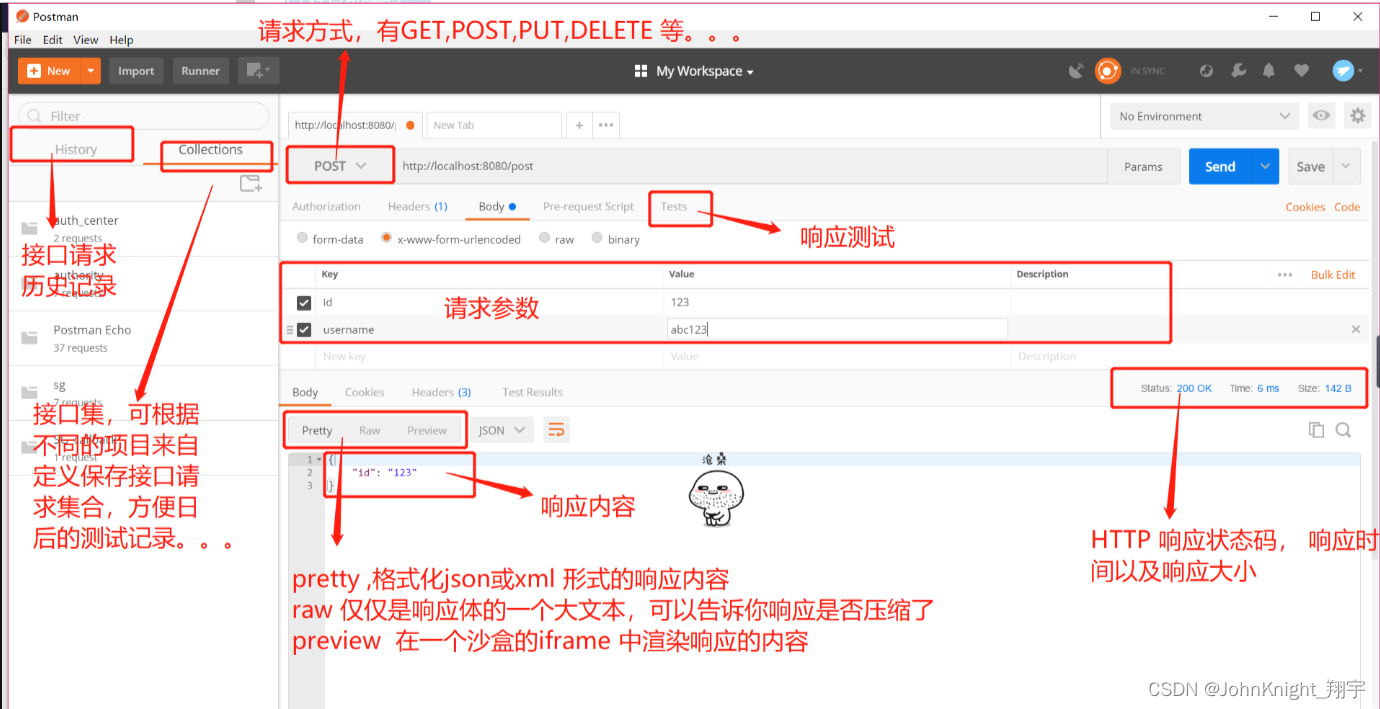
postman用法
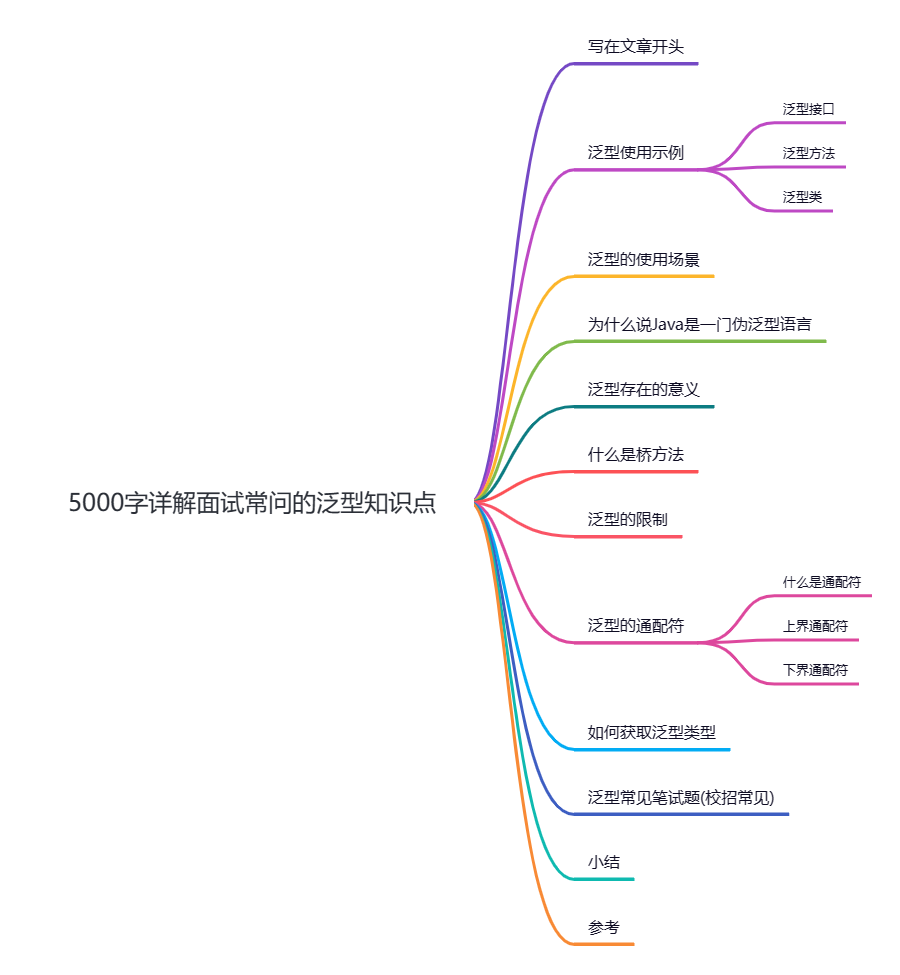
5000字详解面试常问的泛型知识点
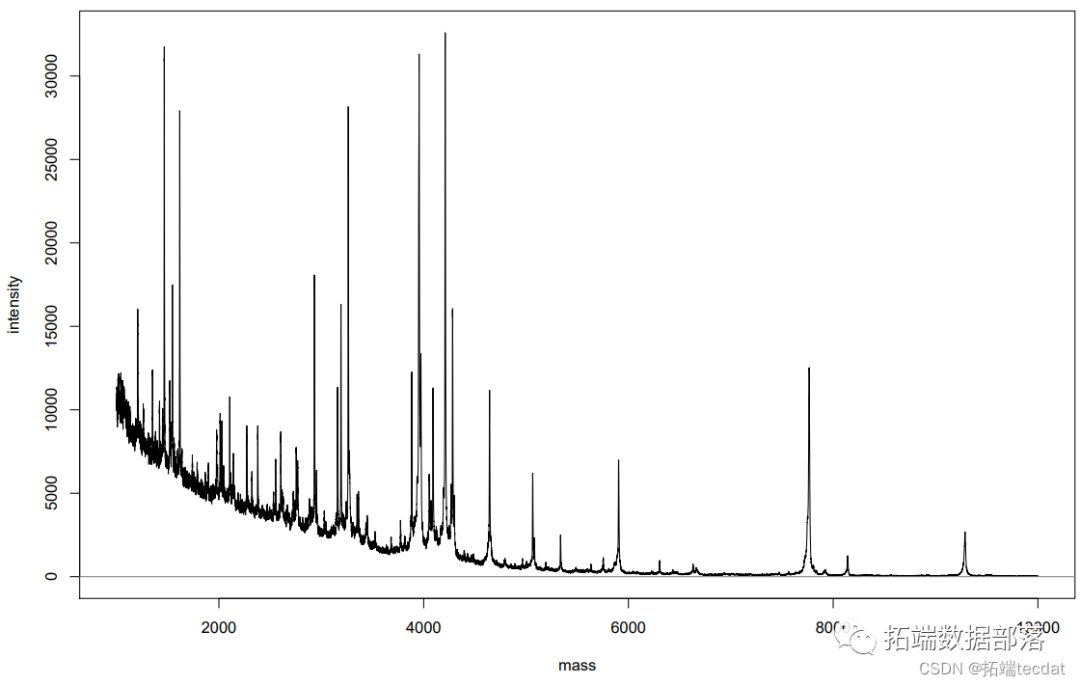
R语言分析蛋白质组学数据:飞行时间质谱(MALDI-TOF)法、峰值检测、多光谱比较
禁用Cookie后Session还能用吗?
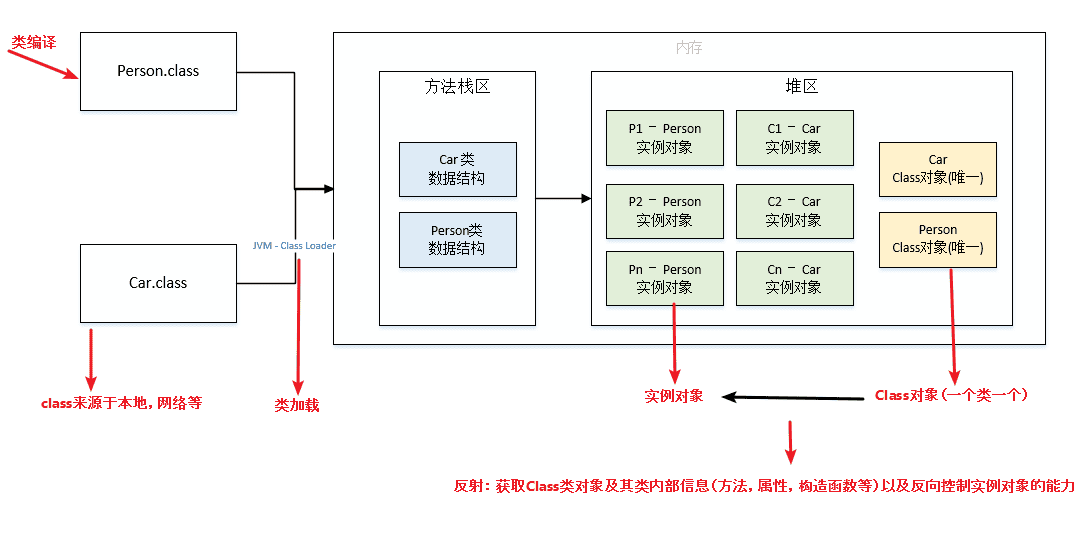
来聊聊Java的反射机制(下)
Cookie和Session
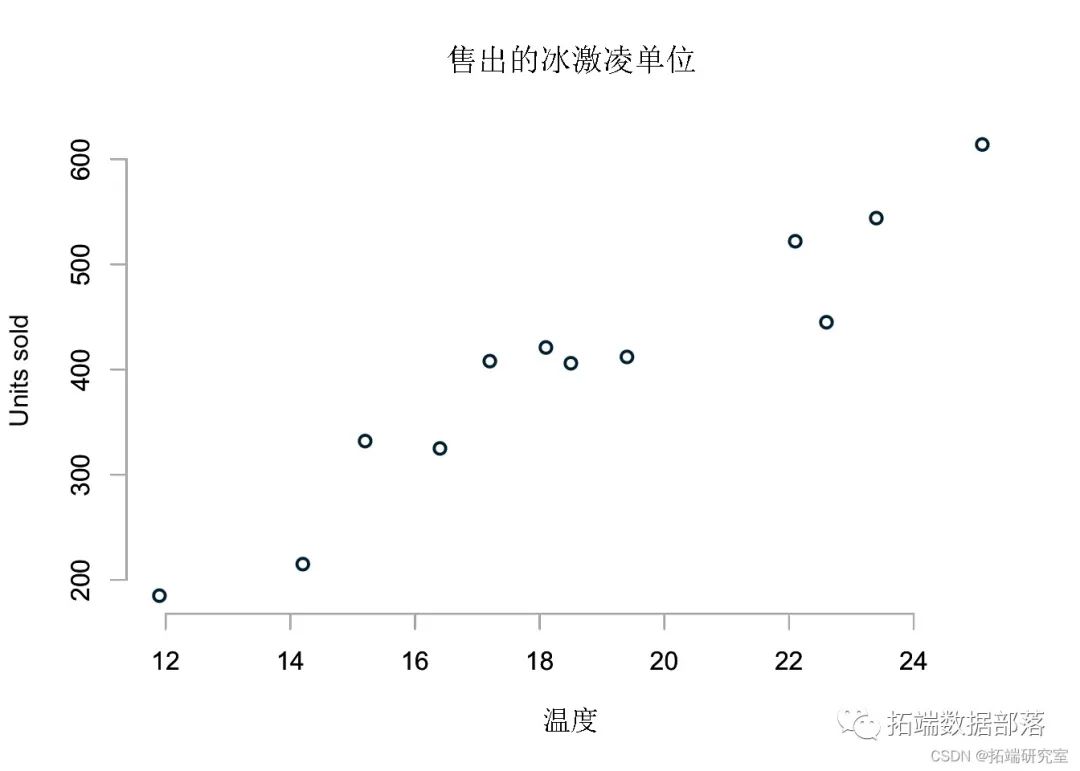
数据分享|R语言广义线性模型GLM:线性最小二乘、对数变换、泊松、二项式逻辑回归分析冰淇淋销售时间序列数据和模拟
来聊聊Java的反射机制(上)
Linux普通玩家,熟悉这些高频命令
R语言SIR模型(Susceptible Infected Recovered Model)代码sir模型实例
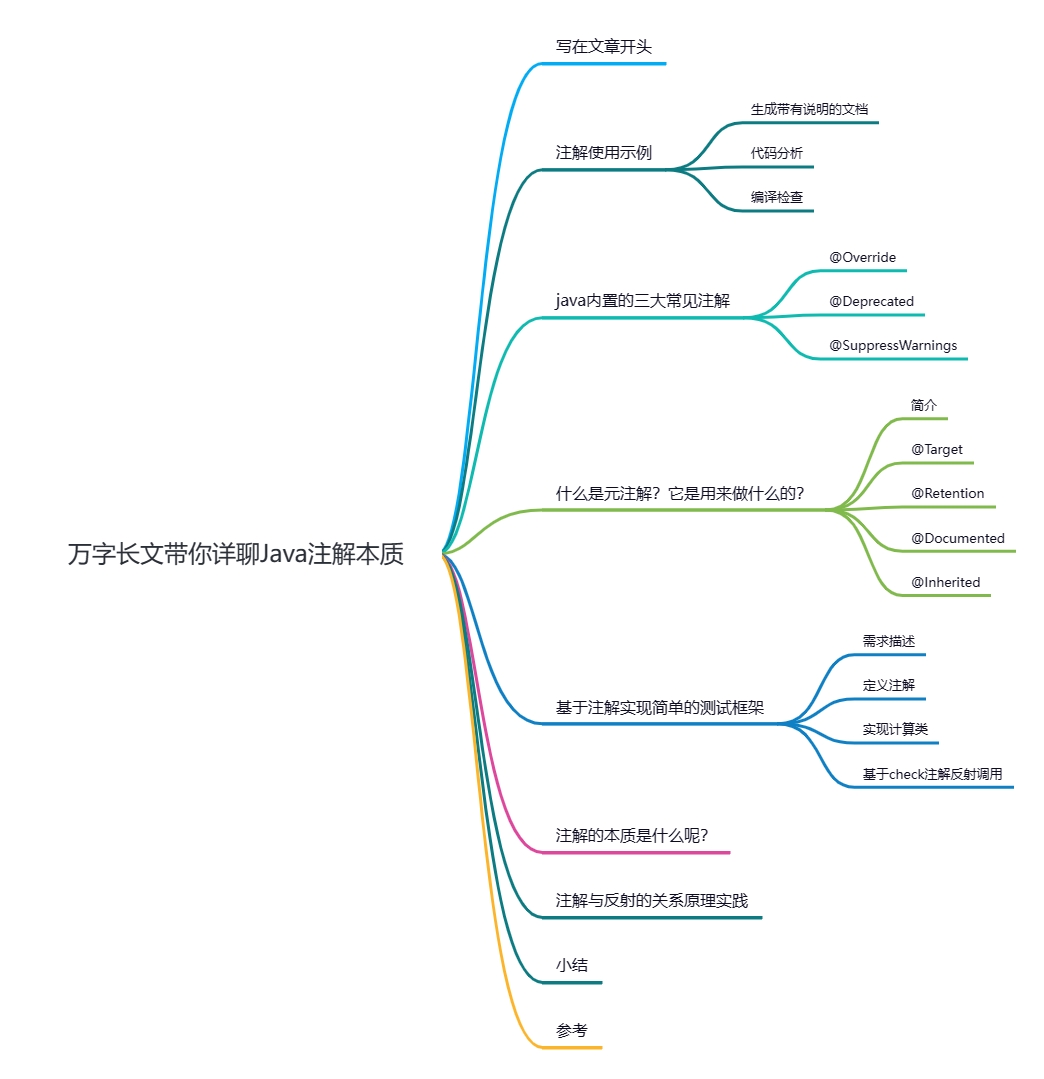
万字长文带你详聊Java注解本质
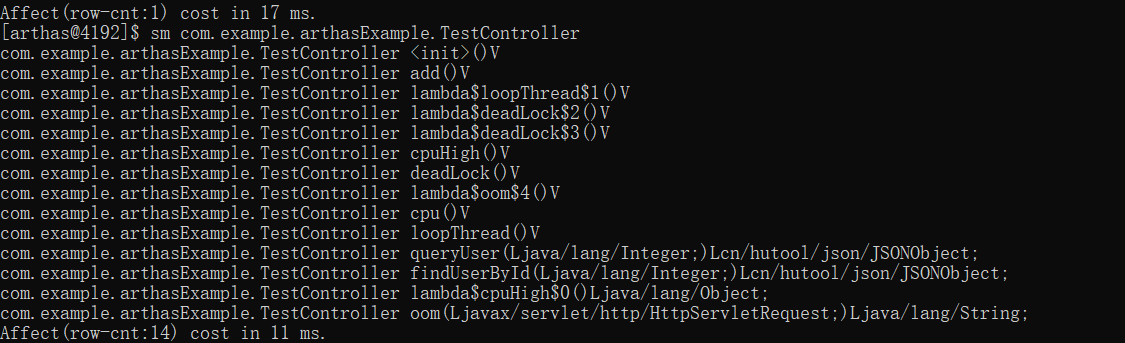
Arthas使用小结(下)