
作者:
苏昆辉,花名抚月,阿里巴巴计算平台事业部 EMR 高级工程师, Apache HDFS committer. 目前从事开源大数据存储和优化方面的工作。
[JindoFS](https://help.aliyun.com/document_detail/164207.html) 是阿里云E-MapReduce团队开发的基于云上对象存储的文件系统(缓存系统)。[JindoFS SDK](https://github.com/aliyun/aliyun-emapreduce-datasources/blob/main/docs/jindofs_sdk_how_to.md)作为JindoFS的客户端,提供了三大能力:1. 面向Hadoop/Spark生态提供访问OSS对象存储的封装;2. 访问JindoFS OSS缓存加速服务;3. 访问JindoFS块模式文件系统。本文主要介绍如何使用JindoFS SDK来访问OSS对象存储,以及使用它来提升我们操作OSS文件的性能。值得一提的是,此前JindoFS SDK 仅限于E-MapReduce产品内部使用,此次全方位面向整个阿里云OSS用户放开,并提供官方维护和支持技术,欢迎广大用户集成和使用。
大数据和OSS
传统大数据领域,我们经常使用HDFS作为底层存储,然后在上面跑MapReduce、SQL on Hadoop的作业。随着云上大数据技术的发展,以及年代悠久的HDFS越发凸显出来的瓶颈问题,越来越多的用户开始将HDFS的数据迁移到对象存储系统上(比如阿里云OSS)然后直接在OSS上跑MapReduce、SQL作业。同时,客户习惯将机器学习的数据集也放在OSS上,同时进行相关机器学习作业。用户逐步依托OSS搭建他们的数据仓库、数据湖,此时OSS操作的速度将成为影响作业的执行效率的重大因素。
OSS SDK
[官方SDK](https://help.aliyun.com/document_detail/52834.html)是阿里云OSS团队开发的官方SDK,提供了Bucket管理、文件管理、文件上传下载、版本管理、授权访问、图片处理等API接口。官方SDK提供了Java、Python、C++等版本,它们都是对Restful API的封装。官方SDK提供了对OSS资源全方位管理的接口,这些接口非常全面,也比较底层。
Hadoop-OSS-SDK
[Hadoop-OSS-SDK](https://hadoop.apache.org/docs/stable/hadoop-aliyun/tools/hadoop-aliyun/index.html)是基于官方SDK(Java版)进行封装,提供了Hadoop FileSystem接口的抽象层。大数据生态的系统如Hive、Spark无法直接使用官方SDK,但是它们可以直接操作FileSystem接口进行OSS文件的读写操作。Hadoop-OSS-SDK是Hadoop大数据生态和OSS之间的粘合剂。FileSystem接口主要关注OSS的文件管理、文件上传下载功能,它对官方SDK的Bucket管理、图片处理等并不关心,它不是官方SDK的一个替代。使用FileSystem接口,用户不需要关心什么时候使用简单上传、什么时候使用分片上传,因为FileSystem接口替用户考虑了这些事情。而如果使用官方SDK就必须考虑这些问题,使用起来比较复杂。
JindoFS SDK
[JindoFS SDK](https://github.com/aliyun/aliyun-emapreduce-datasources/blob/main/docs/jindofs_sdk_how_to.md)是一个简单易用的 JindoFS 客户端,目前主要用在E-Mapreduce集群内,提供JindoFS集群访问能力和操作OSS文件的能力。相比于Hadoop-OSS-SDK做了很多的性能优化。现在,JindoFS SDK对外开放使用,我们可以使用该SDK来获得访问OSS的能力,并获得更好的性能。
JindoFS SDK的作用等价于Hadoop-OSS-SDK,可以直接替代Hadoop-OSS-SDK。与Hadoop-OSS-SDK不同的是,JindoFS SDK直接基于OSS Restful API进行实现,而不是基于Java版SDK进行封装。JindoFS SDK也同样提供了Hadoop FileSystem接口,并且JindoFS SDK对文件管理、文件上传下载进行了一系列的性能优化。
JindoFS SDK兼容性如何?
Hadoop开源版本(截止到写这篇文章的时候,Hadoop的最新稳定版是3.2.1)基于OSS SDK 3.4.1版本,其实现了create、open、list、mkdir等FileSystem接口,从而支持Hive、Spark等程序访问OSS。Hadoop-OSS-SDK中实现的接口,在JindoFS SDK中也全面支持。使用方式完全相同,除了一些配置项的key不一样,使用上非常方便,只要用户将JindoFS SDK的jar包放入hadoop的lib目录下,再配上oss的accessKey即可。 JindoFS SDK对Hadoop3的兼容性做了增强,比如支持对OSS的随机读(pread接口),支持ByteBuffer读等等。
使用JindoFS SDK性能提升多少?
我们做了一个[JindoFS SDK 和Hadoop-OSS-SDK 性能对比测试](https://github.com/aliyun/aliyun-emapreduce-datasources/blob/main/docs/jindofs_sdk_vs_hadoop_sdk.md),这个测试中我们准备了3组数据集,从不同的角度进行测试,需要覆盖读、写、移动、删除等一些操作,并且需要分别测试大文件、小文件下的性能。这个测试覆盖了平时用户作业中的大部分场景。 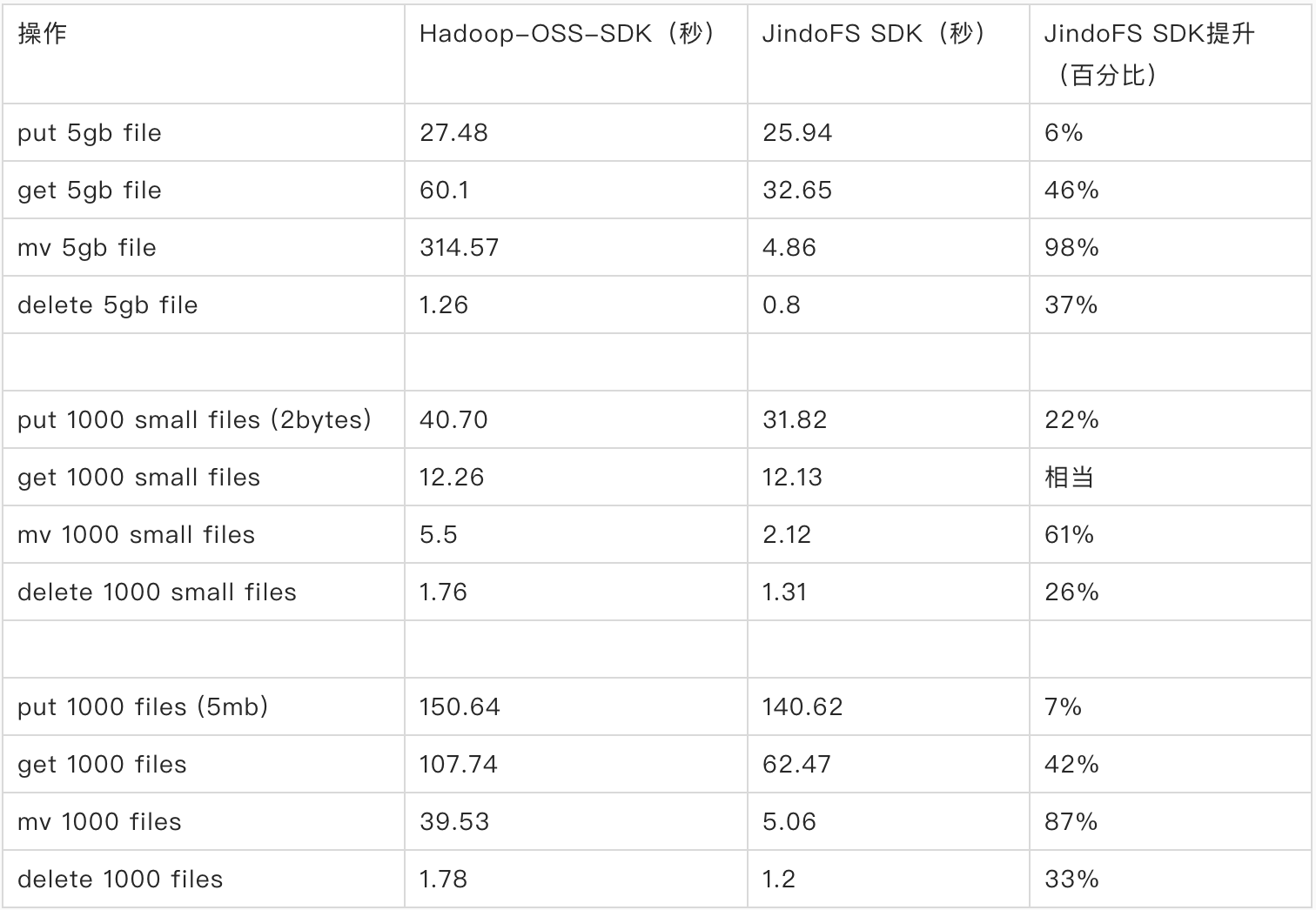 从这个测试中可以看出,JindoFS SDK在put、get、mv、delete操作上性能均显著好于Hadoop-OSS-SDK。
安装SDK
1. 安装jar包
我们去[github repo](https://github.com/aliyun/aliyun-emapreduce-datasources/blob/main/docs/jindofs_sdk_how_to.md)下载最新的jar包 jindofs-sdk-x.x.x.jar ,将sdk包安装到hadoop的classpath下
cp ./jindofs-sdk-*.jar hadoop-2.8.5/share/hadoop/hdfs/lib/jindofs-sdk.jar
注意: 目前SDK只支持Linux、MacOS操作系统,因为SDK底层采用了native代码。
2. 创建客户端配置文件
将下面环境变量添加到/etc/profile文件中 export B2SDK_CONF_DIR=/etc/jindofs-sdk-conf 创建文件 /etc/jindofs-sdk-conf/bigboot.cfg 包含以下主要内容 ``` [bigboot] logger.dir = /tmp/bigboot-log [bigboot-client] client.oss.retry=5 client.oss.upload.threads=4 client.oss.upload.queue.size=5 client.oss.upload.max.parallelism=16 client.oss.timeout.millisecond=30000 client.oss.connection.timeout.millisecond=3000 ``` 我们可以将oss的ak、secret、endpoint预先配置在 hadoop-2.8.5/etc/hadoop/core-site.xml ,避免每次使用时临时填写ak。 ``` fs.AbstractFileSystem.oss.implcom.aliyun.emr.fs.oss.OSSfs.oss.implcom.aliyun.emr.fs.oss.JindoOssFileSystemfs.jfs.cache.oss-accessKeyIdxxxfs.jfs.cache.oss-accessKeySecretxxxfs.jfs.cache.oss-endpointoss-cn-xxx.aliyuncs.com ``` 至此安装就完成了,非常的方便。
另外,我们推荐配置[免密功能](https://help.aliyun.com/document_detail/156418.html),避免明文保存accessKey,提高安全性。
使用场景:用Hadoop Shell访问OSS
我们试一下用hadoop shell去访问oss,我们可以使用以下命令,访问一个临时的oss bucket
``` hadoop fs -ls oss://:@./ ```在生产上不推荐使用此方式,因为这种方式accessKey会作为path的一部分落在日志里面。
如果我们已经事先在core-site.xml配置好了accessKey,或者配置了免密功能,那么我们可以直接使用以下命令 ``` hadoop fs -ls oss:/// ```
使用场景:将Hive表存放在OSS
默认hive使用HDFS作为底层存储,我们可以将hive的底层存储替换成OSS,只需要在hive-site.xml里面修改以下配置 ``` hive.metastore.warehouse.diross://bucket/user/hive/warehouse ``` 然后,我们通过hive建的表,就会直接存放在OSS上。后续通过hive的查询就会查询OSS的数据。
CREATE TABLE pokes_jfs (foo INT, bar STRING);
如果不希望将整个hive的warehouse都放到OSS上,也可以对单表指定location到OSS。
CREATE TABLE pokes_jfs (foo INT, bar STRING) LOCATION 'oss://bucket/warehouse/pokes_jfs.db';
使用场景:用Spark查询OSS表
spark使用自带的hadoop client包,因此我们需要把JindoFS SDK也复制到spark目录。
cp ./jindofs-sdk-*.jar spark-2.4.6/jars/
然后执行spark-sql去查询Hive的OSS表
bin/spark-sql
select * from pokes_jfs;
更多场景
除了上面提到的MapReduce、Hive、Spark引擎,下面这些场景也可以受益于JindoFS SDK: - Presto读写OSS - Impala读写OSS - 使用OSS作为Hbase的底层存储 JindoFS SDK还在日益完善,后续会在实时计算、机器学习等更多领域提供支持。欢迎大家下载使用JindoFS SDK,如果遇到任何问题,请随时联系阿里云E-Mapreduce团队,或者在github上提交issue,我们将尽快为您解答。 ---- 相关阅读推荐: [JindoFS - 分层存储](https://developer.aliyun.com/article/766586?spm=a2c6h.12873581.0.0.750b47b4Lg12jS&groupCode=aliyunemr) [JindoFS概述:云原生的大数据计算存储分离方案](https://developer.aliyun.com/article/720081?spm=a2c6h.12873639.0.0.1c4f75a8CKYiUR) [JindoFS解析 - 云上大数据高性能数据湖存储方案](https://developer.aliyun.com/article/720312?spm=a2c6h.12873639.0.0.5cc875a8jQttes) ---- 后续我们也会在云栖社区和钉钉群分享更多的 Jindo 技术干货,欢迎有兴趣的同学加入 【阿里云EMR钉钉群】进行交流和技术分享。

