背景
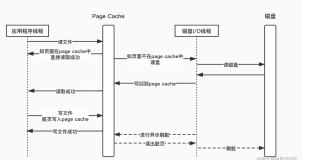
虽然同为LSM-tree架构,X-Engine的设计哲学与传统基于LSM-tree架构的Rocksdb等引擎并不完全一致,如下图所示:

设计关键点1:X-Engine磁盘上的数据,在常态下只有两层(L1/L2),L0层是MemTable在compaction来不及的情况下暂存到磁盘上缓解内存压力时才启用的,正常情况下被冻结的MemTable可以直接和磁盘上的L1合并。
设计关键点2:在L1/L2之间的compaction合并过程中,X-Engine的冷热合并算法倾向于将热点数据保留在L1层(基于访问频度),将访问较少的数据下刷到L2层并进行压缩存储。这是一个对数据在物理上进行冷热分离的过程, 其结果是L1存储的都是热点数据,L2存储的都是冷数据。对L1进行缓存时会有更高的内存利用率。
按照设计初衷,X-Engine正常运行时,Memtable中缓存了最近写入还未刷盘的数据,L1中保存了磁盘访问频度最高的数据,也大部分被内存缓存,分层之后X-Engine的读性能优化被分解为两个独立子问题:
- 内存MemTable部分和L1层数据读操作是CPU bound的,手段主要是优化CPU指令的执行效率和访问主存的速度。
- L2层的读性能依赖于磁盘的随机读能力,对此部分的优化手段是更精准的冷热识别,其目标是最大化IOPS利用率。
考虑到Memtable部分数据量较少,在冷热识别算法精准并且内存足够缓存热点数据的前提下,X-Engine的性能整体上取决于对L1部分数据的内存查找效率,这也是今天这篇文章探讨的主题: 如何最大化命中内存时的读取性能。
读取路径存在的问题
在数据集小于可用内存时,X-Engine的读性能受限于CPU资源。分析一个CPU bound程序的性能问题时,我们需要看CPU在哪些地方繁忙。按照CPU使用率的定义,CPU在执行指令时或者在等待数据时(stall) 都会处于busy状态,存储引擎的读性能优化最后都会落到两个点上:
- 提升CPU Cache命中率,主要靠执行线程在时间上和空间上访存的局部性。
- 提升CPU指令的执行效率,这一方面需要精简实现代码,减少不必要的执行路径,另一方面需要减少不同线程之间的状态同步,保证指令流水线顺畅执行。
L1层数据组织和读取过程:X-Engine将数据划分成2MB大小的Extent,Extent内部会记录编码成16KB的Block,每个Extent内部包含一个IndexBlock以辅助定位DataBlock。整体看X-Engine中L1/L2层的数据组织是一个类似B+树的索引结构。如果所有操作都能命中内存,在Extent中读取一条key=X的记录,操作会按如下四个步骤执行:
- ExtentMeta数组是这棵B+树的根节点,在其中二分查找定位出X所属的Extent.
- Extent可以理解为一棵子树,首先需要通过一次Hash查找(查询缓存)获取到该Extent的IndexBlock。
- 从IndexBlock中定位出X所属的DataBlock的Key, 并通过一次Hash查找定位到X所属的DataBlock。
- 在内存中的DataBlock中查找到该记录的实际内容,并返回对应的Value.
结合上述读路径的实现逻辑,同时对X-Engine全内存命中读过程进行Perf分析之后。我们在如下三个方面进行改进尝试(1)数据页的编码及查找指令优化 (2) 降低BufferPool的管理开销(3)优化多核上的多线程运行的Cache冲刷问题,最终获得了整体124%的读性能提升。
接下来我们将详述这三个问题的根源以及我们的优化方法,最后通过实验对每一步优化手段的收益进行了评估。考虑到这三个问题在数据库存储引擎中的普遍性,这些优化方法对于InnoDB, Rocksdb等引擎也是适用的。
Block编码及SIMD
数据页编码及其问题
与Rockdb/InnoDB数据页格式类似,X-Engine索引页和数据页具有相同的格式。每个Block顺序存储KV pairs,并对key进行分段前缀压缩(每个段称为restart interval),KV pairs之后有一个restart array,存储每个restart interval在Block中的offset。搜索时首先会在restart array中进行二分查找,定位到可能包含target key的最小的restart interval(下图1、2、3、4),再从这个restart interval开始顺序比较(下图5),如下图所示:
查找过程本质上就是指针数组中的二分查找,restart array中存储的restart interval的offset可以理解为指向restart interval的指针,perf分析显示,该过程存在如下两点问题:
1.内存访问在前面的KVs和restart array之间跳跃。restart array中仅存储restart interval的offset,在查找时需要根据offset访问BlockContent的相应位置获得key,这样跳跃的内存访问没有规律(每次restart array和实际key的距离随机)且间隔多个cache line,无法充分利用CPU cache,带来一定的访存开销。
2.前后两次比较无法利用CPU cache。除了最后一次比较之外,每次比较的index key和前一次比较的index key间隔都可能超过一个cache line,因此无法利用前一次的CPU cache,导致访存开销很大。
Cache友好的Block编码
针对指针数组中二分查找CPU cache不友好的问题,尝试将频繁访问的数据页转换成CPU cache友好的两层B+树结构,将访问时序上前后相邻的记录在物理空间上聚簇在一起,其逻辑存储形式如下:
物理存储形式如下:
构建时按物理存储形式顺序构建每个node,查找时使用类似B+树的查找方式。CPU cache友好的两层B+树从三个角度提升CPU cache利用效率:
- 使内存组织的空间局部性和访问顺序的时间局部性一致。使用B+树作为索引结构,直接在B+树中存储kv的内容,并在节点内采用顺序查找。B+树中访问顺序相邻的节点存储在同一个node中,kv内容直接存储在node中避免了访存地址跳跃的问题,顺序查找进一步保证了时间局部性和空间局部性的一致,并且访问顺序和prefetch的顺序一致,尽可能地保证了prefetch在恰当的时机进行。计算开销方面,B+树查找算法的时间复杂度和二分查找相同,因为node内key的数量较少,顺序查找和二分查找计算开销接近。
- 提升cache size与数据量的比值:压缩存储元信息。例如使用2Byte存储offset而不是存储leaf node的指针。
- 选择合适的B+树层数:B+树层数为2,fanout为N开根号。每层节点至少会产生一次cache miss,过多的层数会带来更多的cache miss,而1层的B+树node过大,计算开销和CPU cache效率实际上和restart array差不多,当层数为2时,CPU cache对in-flight的load请求和prefetch的支持可以让每层node访问仅产生1-2次cache miss,是CPU cache效率最佳的选择。
这种编码格式对range查询也能完好的支持,对range查询的第一次seek操作,能起到和点查类似的加速效果,而对于后续的scan迭代,也无负面影响。此部分优化更详细的新可以参见公众号前一篇文章:数据库存储引擎如何利用好CPU缓存
SIMD指令加速长Key比较
解决了数据页中记录查找的cache访问问题之后,继续往下perf分析,会发现查找路径中的compare比较函数消耗了较多的CPU cycle数,在查找长key场景时,计算开销的问题会更加明显。考虑到我们新的数据页编码结构中,每次读取会将多个需要先后比较的index key同时load进CPU cache, 引入SIMD指令集可以实现在一个CPU cycle内并行检索完在cache中的多个index key。
为了使用SIMD指令集,我们需要对X-Engine的数据页编码继续进行调整,如下图所示:
对key进行lossy compression:由于SIMD寄存器的处理单位segment最长为64bit(AVX-512指令集),简单地分段并行比较长key会因为额外逻辑抹去并行计算带来的性能提升。因此这里将key拆分为common prefix+significant Nbits+suffix,避免了分段并行比较在prefix上的多余操作,而significant Nbits(N取决于SIMD寄存器的segment大小)逻辑上具有很高的区分度,在大多数情况下都仅需要一次SIMD比较就能得到结果,如果出现相等的情况,也只需要顺序比较一部分的index key的suffix。
选择固定的fanout并使用padding补齐:SIMD指令的处理带宽(即SIMD寄存器中segment的数量)均为2的指数,如果fanout仍然是N开根号,prepare过程会增加很多额外的操作。同时考虑对CPU cache友好的node长度和对SIMD指令处理带宽的适配,以及DataBlock中restart key的数量的范围,leaf node的fanout固定为8,root node的fanout固定为16,实际key的数量不足node的fanout,则用node中最大的key padding补齐,这样可以直接在代码中将SIMD指令写死,减少分支预测开销。
对索引页和数据页进行重新编码再配合SIMD指令加速,在不同行长下测试最大能提升20%左右的点查性能。在TP系统中,单个请求读写的数据量非常少,在我们的测试场景一次只操作一条记录,因此数据页编码和SIMD指令优化一起对端到端的性能提升达到20%,已经非常可观.
BP的代价及PointSwizzling
BufferPool管理成本
面向全内存的数据库和面向磁盘的数据库具有不同的设计原则。一个典型的差异是:当访问一个数据页时,全内存数据库倾向于使用指针直接访问,而面向磁盘的数据库一般则通过PageID在一个数据结构中间接地获得该数据页的内存地址(当该数据页没有被缓存时需要先读盘), 然后才能访问到该数据页。这样的间接访问会带来额外的查找开销,已有研究显示在数据集能够完全装载进内存时,BufferPool管理结构会消耗超过30%的CPU资源。
由于OS的虚拟内存地址空间相对于DB的数据集大小来讲是足够的,一个可能的解决办法是对面向磁盘的数据库引擎也使用指针直接访问,当内存空间不足时,则依靠OS的Swap机制来进行内存页的汰换,这样在数据集小于可用内存时,由于消除了PageID映射查找的开销,存储引擎会具有与In-Memory数据库一样的性能。
但这种方法有一个缺陷,在数据集大于系统可用物理内存时,由于OS的的Swap机制不能准确的感知DB中的数据访问特征,它有可能将一个非常关键的内存对象Swap到到磁盘上,导致性能波动。
X-Engine是一个通用存储引擎,其装载的数据集大部分时候都超出了可用内存的大小,因此也必须引入一个BufferPool来管理对数据页的访问。但是在我们的设计中,冷热分离精准且用户负载存在明显的局部性特征时,大部分访问都是命中内存的,这个时候BP的30%的CPU资源消耗显得非常浪费,需要找到办法消除。
X-Engine中的Extent信息/索引页/数据页都是通过BufferPool的Cache管理。其中的Cache使用哈希表和双向链表管理数据,通过哈希查找获取数据,命中后还要维护LRU链表的顺序信息。开销主要来源于三个方面:
- 哈希查找算法本身的计算开销:包括计算hash值和在hashtable中的某个slot进行链表的顺序查找,链表的顺序查找具有CPU cache不友好的问题。
- 维护LRU信息的计算开销:命中后需要调整entry在双向链表中的位置,还可能需要维护old pool和high priority pool的指针。
- 锁竞争的开销:Cache除了用于查找之外,还需要Insert和Evict,因此查找和维护LRU信息时需要对分片加锁,当并发度很高、访问流量很大时,锁的竞争非常激烈。
PointSwizzling
优化BufferPool的间接引用导致的CPU资源开销有一个方法,叫做PointSwizzling,即使用直接指针代替使用PageID+HashMap查找的方法,针对X-Engine中Cache中哈希查找计算开销大的问题,我们引入直连指针进行数据访问,Cache仅用于数据管理,具体方案如下:
目标索引页/数据页/ExtentMeta在第一次装载进内存之后,我们增加一个直连指针指向目标对象(PointSwizzling), 这样可在下一次访问使用直连指针,而不必通过一次HashMap的计算。
目标内存对象并发访问和回收:多线程访问时,可能出现一个线程正在使用一个内存对象,而另一个线程触发了Cache淘汰,需要淘汰这个内存对象并回收这个内存对象的空间。这个问题有两种解决方案:基于Epoch的内存回收或者基于引用计数的内存回收,我们对两种方案都进行了测试,结论是基于Epoch的方式优于基于引用计数的方式(基于Epoch的具体实现见附录)。原因是引用计数虽然是一个原子变量,但是多核环境下计数器的高频更新和读取依然存在因cache一致性导致的cache失效问题,导致性能不佳。
通过PointSwzzling,X-Engine在内存部分的数据访问形态就和全内存数据库一样具有非常高的CPU使用效率。而当存在数据汰换时,可以继续使用BufferPool保持内存数据的命中率。PointSwizzling引入之后,X-Engine在KV接口上全内存命中场景的点查性能提升了近60%。
多核CPU上的Cache访问
数据页编码以及PointSwizzling都是着眼于单线程运行过程中的优化方法,其中数据页的新编码提升了CPU 的Cache命中率,而SIMD和PointSwizzling都是提升了CPU指令的执行效率,即提升了程序的IPC。
分析X-Engine的整体执行框架,我们发现另一个导致CPU Cache利用率低问题:
多线程并发问题
X-Engine作为RDS MySQL以及PolarDB MySQL中的一个存储引擎,其执行框架与MySQL类似,使用One-thread-per-client或者采用线程池模式。特点就是任何线程均可以访问所有表中的数据,在现今动辄32/64/128core的服务器上,执行线程的高度并发导致如下一些问题:
- CPU cache的低效率。例如在128core的服务器上,我们并发访问1000张表,则同一内存数据会同时在多个CPU core的L1/L2 cache中被加载,导致cache利用率较低。同时如果存在更新,在多核上的cache一致性也会带来较大的开销。线程在不同的core上调度发生context switch,同样会造成CPU cache频繁大量的失效。
- 线程同步的开销较大。内存数据都是共享的,访问和修改(例如上面提到的Cache查找、插入和淘汰)需要锁的保护,锁竞争的开销很大。对于使用原子操作进行的线程同步,原子变量在多个CPU core的L1/L2中同步状态需要进行数据传输和跨核通信,开销也很大。
针对此类问题,业界先驱如H-Store,VoltDB给出了一条可供参考的优化方法
多核Shared-nothing架构
我们对X-Engine的执行框架做如下改造:
限制读数据的执行线程数为可用CPU core数目,并进行绑core处理,特定线程只能在特定的core上执行,避免频繁的线程调度。
对X-Engine中的所有Subtable进行分表,特定的分表只能在被特定Core上执行的线程所访问到,避免Cache中出现同一数据的多个副本以及同一数据在不同core的cache间传输。
这样Per-core-level Shared-nothing的架构有如下优势:
CPU cache效率高:同一份数据只可能缓存在一个CPU core的L1/L2 cache中,也避免了实现cache一致性的开销。线程不会发生context switch而导致Cache失效。
大大减少线程同步的开销:数据在前台线程间不共享,不需要锁或原子操作等进行线程间同步,例如Cache的锁竞争和pointer swizzling的swizzle/unswizzle以及内存回收都同时可以解决。
目前该方法对只读性能的提升达到30%左右。此项优化工作还未完全完成,进一步的我们需要优化对热点Subtable的访问问题, 另一方面在事务引擎中,跨表访问是非常常见的,如果一个线程执行一个需要访问到多张表的事务,则如何调度该事务是一个很有挑战性的问题。
实验验证
测试环境
64threads,2Socket.
L1-Cache:32KB Data Cache / 32KB Instruction Cache
L2 Cache:256KB
L3 Cache:32MB
RAM:512GB,使用numactl --interleave=all关闭NUMA
测试场景
key 16Byte,value 8Byte,32张表,每张表2000W条记录,写入数据之后下压到L1层,执行一轮预读预热到缓存中,然后执行readrandom测试。
测试结果
我们以X-Engine原始架构的随机读性能做baseline,然后依次叠加上前述的优化手段。
第一步增加了新的数据页编码方法以及数据页上的SIMD指令查找算法,获得了13.8%的性能提升。
第二步,我们在代码中增加了PointSwizzling优化,性能提升相比BaseLine达到了90%。最后我们重构了X-Engine的执行框架,引入多核无共享执行架构。
最终整体性能相对比BaseLine的提升达到了123%. 测试中也分析了这测试过程中CPU L1 Data Cache miss率的变化以及程序运行的IPC的变化。
为了确定我们的优化手段在哪些路径上产生了最关键的作用,我们对每一步优化手段产生的性能提升进行了breakdown测试并制作了如下的表格. 从这里可以看出对性能提升最大的一步是对DataBlock的间接应用改Direct引用,考虑到DataBlock的数目较多,其原始实现中的Hash查找表比较大,Cache效率较低,产生这样的效果在预期之中。而Index和ExentMeta对象相对数目较少(大概为DataBlock的1/128), 本身具有较好的查找效率,因此对性能的影响也较小。