如何用好数据库,调校数据库使其发挥最优的性能?
如何快速诊断和应对各种原因导致的突发数据库性能问题?
如何以最低资源成本满足业务需求?
......
这些复杂的运维难题最优解到底是什么?
今天(4月22日)15:00
数据库自治服务DAS重磅发布会
现场为你揭晓答案!
数据库自动驾驶时代一触即发
点击这里
即可预约直播
今天提前为大家揭秘数据库自治服务DAS的一个创新功能 —— AutoScale,基于数据库实例的实时性能数据作为输入,由DAS完成流量异常发现、合理数据库规格建议和合理磁盘容量建议,使数据库服务具备自动扩展存储和计算资源的能力。
01背 景
为业务应用选择一个合适的数据库规格,是每个数据库运维同学都会经常面临的一个问题。若规格选的过大,会产生资源浪费;若规格选的过小,计算性能不足会影响业务。
通常情况下,运维同学会采用业务平稳运行状态下,CPU可处于合理水位(例如50%以下)的一个规格(如4核CPU配8G内存)并配一个相对富余的磁盘规格(如200G)。
然而在数据库应用运维同学的日常生活里,线上应用流量突增导致数据库资源打满的情况时有发生,而引发这类问题的场景可能多种多样:
- 1、新业务上线,对业务流量预估不足,导致资源打满,如新上线的应用接入了大量的引流,或基础流量比较大的平台上线了一个新特性功能。
- 2、不可预知的流量,如突发的舆论热点带来的临时流量,或某个网红引发的限时抢购、即兴话题等。
- 3、一些平时运行频次不高,但又偶发集中式访问,如每日一次的上班打卡场景,或每周执行几次的财务核算业务。这类业务场景平时业务压力不高,虽已知会存在访问高峰,但为节省资源而通常不会分配较高的规格。
当上述业务场景突发计算资源不足状况时,通常会让运维同学措手不及,严重影响业务,如何应对“数据库资源打满”是运维同学常常被挑战的问题之一。
在数据库场景下,资源打满可分为计算资源和存储资源两大类,其主要表现:
- 1、计算资源打满,主要表现为CPU资源利用率达到100%,当前规格下的计算能力不足以应对;
- 2、存储资源打满,主要表现为磁盘空间使用率达到100%,数据库写入的数据量达到当前规格下的磁盘空间限制,导致业务无法写入新数据;
针对上述两类问题,数据库自治服务 DAS 进行了服务创新,使数据库服务具备自动扩展存储和计算资源的技术能力,应对上述的问题。
DAS AutoScale基于数据库实例的实时性能数据作为输入,由DAS完成流量异常发现、合理数据库规格建议和合理磁盘容量建议,使数据库服务具备自动扩展存储和计算资源的能力。
接下来,本文将对DAS AutoScale服务的架构进行详细的介绍,包括技术挑战、解决方案和关键技术。
02技术挑战
计算节点规格调整是数据库优化的一种常用手段,尽管计算资源规格只涉及到CPU和内存,但在生产环境进行规格变配的影响还是不容忽视,将涉及数据迁移、HA切换、Proxy切换等操作,对业务也会产生影响。
业务有突发流量时,计算资源通常会变得紧张甚至出现CPU达到100%的情况。通常情况下,这种情况会通过扩容数据库规格的方式来解决问题,同时DBA在准备扩容方案时会至少思考如下三个问题:
- 1.扩容是否能解决资源不足的问题?
- 2.何时应该进行扩容?
- 3.如何扩容,规格该如何选择?
解决这三个问题,DAS同样面临如下三个方面挑战:
2.1. 挑战一:如何判别扩容是否能够解决问题?
在数据库场景下,CPU打满只是一个计算资源不足的表征,导致这个现象的根因多样,解法也同样各异。例如业务流量激增,当前规格的资源确实不能够满足计算需求,在合适的时机点,弹性扩容是一个好的选择,再如出现了大量的慢SQL,慢SQL堵塞任务队列,且占用了大量的计算资源等,此时资深的数据库管理员首先想到的是紧急SQL限流,而不是扩容。在感知到实例资源不足时,DAS同样需要从错综复杂的问题中抽丝剥茧定位根因,基于根因做出明智的决策,是限流,是扩容,还是其它。
2.2. 挑战二:如何选择合适的扩容时机和扩容方式?
对于应急扩容时机,选择的好坏与紧急情况的判断准确与否密切相关。“紧急”告警发出过于频繁,会导致实例频繁的高规格扩容,产生不必要的费用支出;“紧急”告警发出稍晚,业务受到突发情况影响的时间就会相对较长,对业务会产生影响,甚至引发业务故障。在实时监控的场景下,当我们面临一个突发的异常点时,很难预判下一时刻是否还会异常。因此,是否需要应急告警变得比较难以决断。
对于扩容方式,通常有两种方式,分别是通过增加只读节点的水平扩容,以及通过改变实例自身规格的垂直扩容。
其中,水平扩容适用于读流量较多,而写流量较少的场景,但传统数据库需要搬迁数据来搭建只读节点,而搬迁过程中主节点新产生的数据还存在增量同步更新的问题,会导致创建新节点比较慢。
垂直扩容则是在现有规格基础上进行升级,其一般流程为先对备库做升级,然后主备切换,再对新备库做规格升级,通过这样的流程来降低对业务的影响,但是备库升级后切换主库时依然存在数据同步和数据延迟的问题。因此,在什么条件下选择哪种扩容方式也需要依据当前实例的具体流量来进行确定。
2.3. 挑战三:如何选择合适的计算规格?
在数据库场景下,实例变更一次规格涉及多项管控运维操作。以物理机部署的数据库变更规格为例,一次规格变更操作通常会涉及数据文件搬迁、cgroup隔离重新分配、流量代理节点切换、主备节点切换等操作步骤;而基于Docker部署的数据库规格变更则更为复杂,会额外增加Docker镜像生成、Ecs机器选择、规格库存等微服务相关的流程。因此,选择合适的规格可有效地避免规格变更的次数,为业务节省宝贵的时间。
当CPU已经是100%的时候,升配一个规格将会面临两种情况:第一种是升配之后,计算资源负载下降并且业务流量平稳;第二种是升配之后,CPU依然是100%,并且流量因为规格提升后计算能力增强而提升。
第一种情况,是比较理想的情况,也是预期扩容后应该出现的效果,但是第二种情况也是非常常见的情形,由于升配之后的规格依然不能承载当前的业务流量容量,而导致资源依然不足,并且仍在影响业务。如何利用数据库运行时的信息选择一个合适的高配规格是将直接影响升配的有效性。
03解决方案
针对上述提到的三项技术挑战,下面从DAS AutoScale服务的产品能力、解决方案、核心技术这三个方面进行解读,其中涉及RDS和PolarDB两种数据库服务,以及存储自动扩容和规格自动变更两个功能,最后以一个案例进一步具体说明。
3.1. 能力介绍
在产品能力上,目前DAS AutoScale服务针对阿里云RDS数据库和PolarDB数据提供存储自动扩容服务和规格自动变配服务。
其中,针对即将达到用户已购买规格上限的实例,DAS存储自动扩容服务可以进行磁盘空间预扩容,避免出现因数据库磁盘满而影响用户业务的发生。在该服务中,用户可自主配置扩容的阈值比例,也可以采用DAS服务预先提供的90%规格上界的阈值配置,当触发磁盘空间自动扩容事件后,DAS会对该实例的磁盘进行扩容;
针对需要变更实例规格的数据库实例,DAS规格自动变配服务可进行计算资源的调整,用更符合用户业务负载的计算资源来处理应用请求,在该服务中,用户可自主配置业务负载流量的突发程度和持续时间,并可以指定规格变配的最大配置以及变配之后是否回缩到原始规格。
在用户交互层面,DAS AutoScale主要采用消息通知的方式展示具体的进度以及任务状态,其中主要包括异常触发事件、规格建议和管控任务状态三部分。异常触发事件用于通知用户触发变配任务,规格建议将针对存储扩容和规格变配的原始规格和目标值进行说明,而管控任务状态则将反馈AutoScale任务的具体进展和执行状态。
3.2. 方案介绍
为了实现上面介绍的具体能力,DAS AutoScale实现了一套完整的数据闭环,如图1:
图1 DAS AutoScale数据闭环
在该闭环中,包含性能采集模块、决策中心、算法模型、规格建议模块、管控执行模块和任务跟踪模块,各模块的具体功能如下:
- 性能采集模块负责对实例进行实时性能数据采集,涉及数据库的多项性能指标信息、规格配置信息、实例运行会话信息等;
- 决策中心模块则会根据当前性能数据、实例会话列表数据等信息进行全局判断,以解决挑战一的问题。例如可通过SQL限流来解决当前计算资源不足的问题则会采取限流处理;若确实为突增的业务流量,则会继续进行AutoScale服务流程;
- 算法模型是整个DAS AutoScale服务的核心模块,负责对数据库实例的业务负载异常检测和容量规格模型推荐进行计算,进而解决挑战二和挑战三的具体问题;
- 规格建议校验模块将产出具体建议,并针对数据库实例的部署类型和实际运行环境进行适配,并与当前区域的可售卖规格进行二次校验,确保的建议能够顺利在管控侧进行执行;
- 管控模块负责按照产出的规格建议进行分发执行;
- 状态跟踪模块则用于衡量和跟踪规格变更前后数据库实例上的性能变化情况;
接下来,将分别针对DAS AutoScale支持的存储扩容和规格变配两个业务场景进行展开介绍。
图2 存储扩容方案
存储扩容的方案见图2,主要有两类触发方式,分别是用户自定义触发和算法预测触发。其中,算法将根据数据库实例过去一段时间内的磁盘使用值结合时序序列预测算法,预测出未来一段时间内的磁盘使用量,若短时间内磁盘使用量将超过用户实例的磁盘规格,则进行自动扩容。每次磁盘扩容将最少扩大5G,最多扩大原实例规格的15%,以确保数据库实例的磁盘空间充足。
目前在磁盘AutoScale的时机方面,主要采用的是阈值和预测相结合的方式。当用户的磁盘数据缓慢增长达到既定阈值(90%)时,将触发扩容操作;如果用户的磁盘数据快速增长,算法预测到其短时间内将会可用空间不足时,也会给出磁盘扩容建议及相应的扩容原因说明。
图3 规格变配方案
规格变配的方案见图3,其具体流程为:首先,异常检测模块将针对业务突发流量从多个维度(qps、tps、active session、iops等指标)进行突发异常识别,经决策中心判别是否需要AutoScale变配规格,然后由规格建议模块产生高规格建议,再由管控组件进行规格变配执行。
待应用的异常流量结束之后,异常检测模块将识别出流量已回归正常,然后再由管控组件根据元数据中存储的原规格信息进行规格回缩。在整个变配流程结束之后,将有效果跟踪模块产出变配期间的性能变化趋势和效果评估。
目前规格的AutoScale触发时机方面,主要是采取对实例的多种性能指标(包括cpu利用率、磁盘iops、实例Logic read等)进行异常检测之后,结合用户设定的观测窗口期长度来实现有效的规格AutoScale触发。
触发AutoScale之后,规格推荐算法模块将基于训练好的模型并结合当前性能数据、规格、历史性能数据进行计算,产出更适合当前流量的实例规格。此外,回缩原始规格的触发时机也是需要结合用户的静默期配置窗口长度和实例的性能数据进行判断,当符合回缩原始规格条件后,将进行原始规格的回缩。
3.3. 核心技术支撑
DAS AutoScale服务依赖的是阿里云数据库数据链路团队、管控团队和内核团队技术的综合实力,其中主要依赖了如下几项关键技术:
- 1.全网数据库实例的秒级数据监控技术,目前监控采集链路实现了全网所有数据库实例的秒级采集、监控、展现、诊断,可每秒实时处理超过1000万项监控指标,为数据库服务智能化打下了坚实的数据基础;
- 2.全网统一的RDS管控任务流技术,目前该管控任务流承担了阿里云全网实例的运维操作执行,为AutoScale技术的具体执行落地提供了可靠的保障;
- 3.基于预测和机器学习的时序异常检测算法,目前的时序异常检测算法可提供周期性检测、转折点判定和连续异常区间识别等功能,目前对线上10w+的数据库实例进行1天后数据预测,误差小于5%的实例占比稳定在99%以上, 并且预测14天之后的误差小于5%的实例占比在94%以上;
- 4.基于DeepLearning的数据库RT预测模型,该算法可基于数据库实例的CPU使用情况、逻辑读、物理读和iops等多项数据指标预测出实例运行时的rt值,用于指导数据库对BufferPool内存的缩减,为阿里巴巴数据库节省超27T内存,占比总内存约17%;
- 5.基于云计算架构的下一代关系型数据库PolarDB,PolarDB是阿里云数据库团队为云计算时代定制的数据库,其中它的具备计算节点与存储节点分离特性对AutoScale提供了强有力的技术保障,能够避免拷贝数据存储带来的额外开销,大幅提升AutoScale的体验
。
在上述多项技术的加持下,DAS AutoScale目前提供对RDS规格推荐建议、RDS存储AutoScale以及PolarDB的规格和存储AutoScale能力,并能够保证AutoScale期间的数据一致性和完整性,能够在不影响业务稳定性的情况下实现AutoScale,为业务保驾护航!
3.4. 具体案例

图4 变配任务示例
接下来,以某实例上的AutoScale过程进行说明,如图4。
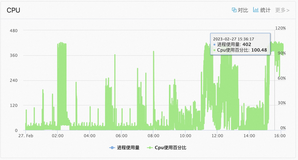
该业务在19:43分突然出现异常流量,导致CPU和活跃会话飙升,CPU资源从原10%左右升至70%以上,资源相对紧张。
在该实例上,用户配置了15分钟的观测窗口以及CPU超过70%的触发条件,用于避免过于频繁的AutoScale触发。异常流量持续到19:58时,已经具备了触发AutoScale的条件。经过7分钟的管控任务,在20:05完成主节点的规格变配。对比升配前后的资源使用情况,可看出,初始阶段该实例的CPU、IOPS相对较高,再升到高配规格之后,CPU、IOPS的使用量均有明显下降。
04如何使用
您可以在阿里云数据库自治服务 DAS 上免费使用该功能,扫描下方二维码,即可立即申请体验。

05相关阅读
业务异常只能看着数据库崩溃?看看应急处理利器——自动SQL限流
耗时又繁重的SQL优化,以后就都交给TA吧!
陷入人肉SQL优化的恶性循环怎么办?是时候跟它们说再见了
因“智”而治,数据库即将迈入自动驾驶时代
直播预告
因“智”而治,数据库即将迈入自动驾驶时代
4月22日 15:00 — 16:30
期待与你一同见证精彩蜕变
点击这里
立即预约观看DAS发布会直播