什么是时序数据?
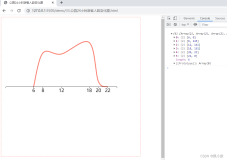
时序数据也就是我们平时经常说到的时间序列数据。时间序列数据是统一指标按时间顺序记录的数据列。数据分析的目的一般是通过找出样本内时间序列的统计特性和发展规律性,构建时间序列模型,进行样本外预测。时序数据在数据分析中也是非常常见的。当然有了可靠的时序数据,可视化是不可少的。
场景分析
现在我们想要通过访问量趋势的时序数据来做一个可视化的分析。需要解决的问题主要有以下几个:
1.通过访问趋势,针对一些突变的数据做一些异常点的标注
2.访问趋势预测
3.访问量包含PV和UV,两者数据量差距较大,如何更好的展示
4.时序数据可能中间会有缺失
进行时序数据的可视化之前,我们首先需要了解“时间”所具有的特征:
1.有序性:时间都是有序的,事件之间有先后顺序。
2.周期性:许多自然或商业现象都具有循环规律,如季节等周期性的循环。
3.结构性:时间的尺度可以按照年、季度、月、日、小时、分钟、秒等去切割。
日志服务提供一站式的数据采集可视化分析能力,下面我们来看看怎么基于日志服务提供的可视化功能做时序数据的分析。
前提条件
成功开通并接入日志服务,这里以nginx访问日志为例
查询分析
日志服务提供大规模日志实时查询与分析能力。我们先通过输入SQL,将实时的时序数据查询出来。我们以小时作为粒度,查询相对4小时
* | select date_format(from_unixtime(__time__ - __time__% 3600), '%Y-%m-%d %H:%i:%S') as hour, count(1) as pv group by hour order by hour asc limit 100
可视化分析
可以看到我们的时间格式为:%Y-%m-%d %H:%M:%S(含义参考:时间函数)
这里只查询了最近4个小时,年月日的显示就略显多余了,但是我们需要分析周趋势和月趋势,所以查询的结果里的年月日就需要保留。理想的显示状态是,查询区间为1天内,显示小时分钟秒级别,查询区间超过1天,显示完整的时间。
时间序列
1.首先选择“线图”,然后点击属性配置,我们能看到详细的配置
2.在下面找到“时间序列”,选中我们当前数据列中为时间的字段,右侧可以看到解析出来的时间格式(注意:这里的时间列数据必须是完整的时间,即可以转换成时间戳的数据)。
3.我们扩大查询时间范围,选择相对时间”一周“,这里看到X轴的时间格式也会跟着发生变化
4.选择”添加仪表盘“,将我们的图表保存下来。再进入我们创建好的仪表盘,就能看到我们创建好的图表了。
5.
异常点
对于一些数据的突变,想要通过更明显的方式标注出来,我们这里可以使用异常点标注的功能
1.在仪表盘右上角点击”编辑“,进入编辑模式。
2.然后在图表的右上角选择”编辑“,编辑当前图表的属性配置
3.首先,选择”异常点所在维度“,这里直接选择”pv“列。然后输入”异常点下界“或”异常点上界“的实际值。这里在异常点上界输入150000
访问趋势预测
预测在时序数据分析场景中非常重要,我们这里通过简单的配置就能实现时序数据的预测。
1.同样,还是编辑图表,找到属性配置“机器学习”,开启后并点击“确认”进行保存
2.在图表右上角可以找到“机器学习”的图标,选中左键点击,出现机器学习分析的窗口
3.选择“数据所在列“为pv,点击开始分析,可以看到我们异常检测的结果,蓝线为实际曲线,红色为预测曲线,绿色区域为预测区间
4.同样,我们还可以进行时序预测,分析类型选择”时序预测“,点击开始分析。其中蓝色曲线为实际值,红色曲线为预测值
多个数值列
如果存在多维度的数值列,我们这里新增一列UV的趋势,看一下效果
由于UV的数值明显比PV的数值低,这样几乎看不清UV的趋势是什么样子,当然我们也可以通过点击图例来调整UV的显示。不过这样人工操作体验会较差。这里的线图配置,提供了两个Y轴维度:左Y轴和右Y轴。我们选择”右Y轴“为UV。为了更好区分,在”为柱列“里选择UV(”为柱列“即显示柱状的数据列)。
现在我们就可以一眼看出PV趋势和UV趋势的对比图了
时序数据补点
在很多特殊场景下,时序数据并不是一个连续的数据。可能由于各种原因,导致中间有些数据丢失,在可视化显示的时候,如果不去显示这些丢失的数据,用户通过可视化图表很难去发现这些数据丢失了。如果进行补点的话,这个数值的大小定义就成了一个问题。这里我们就可以用到线图的”补点“功能来解决这个问题。
1.同样还是选择编辑刚刚配置好的图表,在属性配置中找到”自动补点“
2.这里有四个选项可以选择:零值,平均值,最大值,最小值。如果想要标注这些缺失点,建议选择零值。如果只想要看时序数据整体趋势建议选择平均值。当然视具体情况而定。
写在最后
这里关于时序数据的可视化实践,是日志服务可视化中很小一部分功能。目前日志服务支持的可视化组件类型有30+,覆盖了绝大部分数据可视化场景。日志服务可视化目前经历了大量场景的锤炼,在集团内部得到了广泛使用。如果您有更好的想法或者建议,欢迎加入钉钉群进行讨论。