presto资源管理介绍
oomKiller
presto会监控sql整个生命周期资源的使用(mem,cpu),worker也会周期性汇报自身mem使用状况,当worker的free memory降为0及以下时,触发集群oom逻辑。
- 正常场景下,ClusterMemoryManger也会周期性检查query 内存使用量,如果超过2TB,直接杀死。
- oom场景下,lowMemoryKiller 会选择内存使用量最大的query,然后将其杀死。
资源组(resource-group)
可按用户划分资源组,可简化模型,一个组管理一个用户所有查询。 每个 Group 可以自定义了三项数据
- CpuQuota:使用cpu时间片配额,分软硬限
- MemoryQuota:使用内存配额,仅有硬限。
- query并发数:一个组可以并发执行查询个数。
从三个维度限制一个 Group 的最大资源使用量, 同时可以配置一系列的选择器, 每个选择器可以根据请求上下文比如用户名, 来源,客户端tag等信息唯一确定归属于某个 Group, 因此该框架其实是具备提供多租户隔离的能力的.
示例配置
https://prestodb.io/docs/current/admin/resource-groups.html
执行主要流程:
- 先判断query属于哪个资源组
- 看看当前组有没有quota执行该query,有直接运行,没有则塞入队列,等待资源。
- 执行的query周期性汇报资源使用情况,资源组更新quota,减去已使用部分。当quota减为0了,新进入的查询只能进入等待队列,等待有quota了,被manager调度执行。该资源组处于封禁状态,等待query执行完解禁。
- mananger轮询有quota的组,调度组里面处于队列中的query。
公平调度
sql调度层面
默认情况下manager采用round-robin公平调度group,当然你也可以配置权重,让一些group得到更多的调度机会。group内部采用fifo方式调度query。group资源如果超阈了,短时间会封禁,不再继续发起query执行,直到先前query执行完。
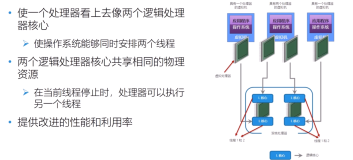
task执行层面
Presto在每个Worker节点上调度许多并发任务,以实现多租户,并且使用了一个协作的多任务处理模型。任意给定的split只能在一个线程上最多运行1秒钟,之后必须放弃该线程并返回队列中。当输出缓存已满(下游阶段无法足够快地消耗数据),输入缓存为空(上游阶段可能无法足够快地生成数据),或系统内存不足时,本地调度器会在当前任务CPU运行时间(指运行1秒中)到达之前切换到另一个任务。这样释放了那些正在处理split的线程,帮助Presto最大限度的利用CPU,从而适应不同的查询。
当一个split放弃当前的线程时,查询引擎会确定一下个要被执行的task(与一个或多个split相关联)。Presto并没有提前预测完成一个新的查询所需的资源,而只是使用任务的总CPU时间,将一个多级优先队列划分成五个层级。随着task累积的CPU时间越来越多,它将被划分到更高的级别。每个级别都指定了一个可配置的CPU时间。在实际应用中,要在任意负载下公平的协调多任务的处理是相当有挑战性的。不同的split使用的IO和CPU的差异性相当的大,即便在相同的任务中也是如此,而复杂的函数(如正则表达式)相对于其他的split可能会消耗更多的线程时间。而某些Connector不提供异步的API,因此有的工作线程会被保留数分钟。
在处理这些约束条件时,调度程序必须是自适应的。系统提供了低成本的信号量,因此在一个operator中可以暂停长时间的运算。如果operator中的停止时间超过特定的值,调度器会将实际的线程时间计入当前task,并且会暂时调低这个任务将来的执行频率。这种自适应的特性允许我们在Interactive Analytics 以及Batch ETL的案例中处理不同类型的查询,其中presto可以为消耗最低资源的查询提供更高的优先级。我们也可以这样来理解,用户只希望低成本的查询可以被快速执行,而不必担心高成本的查询的运转时间。同时运行更多的查询,即使以牺牲更多上下文切换为代价,也可以减少总的排队时间,因为低成本的查询会被快速的执行并退出。
资源隔离
无资源隔离,worker上的TaskExecutor线程被每个task共享使用。从task视角,底层线程都是共用的,做不到物理意义上的隔离。
结论及潜在问题
资源管理三个核心问题
-
避免过度分配:
- presto没有cbo,无法预估一个查询资源使用情况,没法避免过度分配
-
资源隔离:一个worker上的任务可能会争夺资源并而相互干扰。如何相互间互不干扰至关重要。
- presto共享任务线程模式,无法真正意义上做到资源隔离
-
调度不同的负载:不同用户对DLA使用情况不尽相同,query有大有小,如何让不同负载用户查询得到公平调度。
- 使用一个用户一个资源组模式,query能得到公平调度,基本不存在大查询饿死小查询问题
- 当大家共用一个全局资源组,查询是fifo方式调度,查询多的用户是会饿死小用户。
潜在问题
-
presto的资源组管理是一个前置quota检查,执行前无法判断其资源使用情况。放行后,可能是大query,资源不够,这属于过度分配问题。
- 只在请求提交阶段做了隔离, 且没有预估请求的资源使用量. 即只考虑请求所属 Group 当前的资源占用量是否超限, 未超限则放行, 不考虑放行后未来执行过程中资源使用是否会超限
- cpu使用是延时反馈, 是在请求结束后再反馈 CPU 使用, 但增加 CPU 资源是实时的
-
集群资源使用率问题
- 一个用户对应资源组quota是硬配,不可动态调整,容易导致集群资源使用率低。
- 如果每个资源组quota配额都很高,超出集群负载,超频调度SQL执行,导致oomkiller频繁杀大sql。