/1 前言/
今天我们来说说python的pip换源吧,这个换源,相对来说,还是比较重要的,能让自己少生好几次气的,哈哈哈!礼拜一的时候,小编发布了手把手教你进行pip换源,让你的Python库下载嗖嗖的(系列一),没有来得及上车的小伙伴,可以戳进去看看。
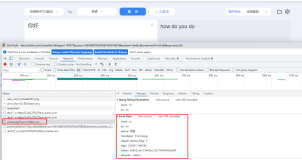
在上篇文章的留言处,我看到了一位名为hxw的大侠慷慨留言,详情如下图所示。
怀着学习之心,小编自己亲自去尝试,发现其提供的方法行之有效,现在整理出来分享给大家。hxw如果看到这篇文章的话,可以后台获取小编的微信,小编将给予一个红包聊表谢意。
/2 为什么要换源/
我相信小伙伴们一定也遇到跟我这样的问题,如下图所示。
没错,就是我们在pip安装东西的时候,有时候容易飘黄飘红,而且大多时候还慢。这个是因为我们去获取的包,是直接从国外拿的。
虽然有墙,但是为了我们的学习,仍然还是要留出一些正儿八经的网站的,但是仍然还是慢,毕竟太远了,咋办呢?国内的大神早都在国内搭建好了站点,和原网站的内容一模一样,我们只需要将我们的pip源指向国内就好了,我也是后悔知道的晚啊,害,踩了那么多的坑。那咱们废话不说,就直接开始吧~
/3 换源流程/
1)国内源列表
首先先列举一下国内那些站点,能用一般5个可用,其他我也没试过。
2)如何换源
网上很多关于换源的教程,大部分都是通过在C盘下的某个文件夹新建个什么文件,然后在复制一些东西进入。但是我感觉,还是有点麻烦,我们大Python要求的就是简洁,方便。这里使用了读者留言的方法,十分的简洁,详情如下。
我们只需要一个最简单的命令 ↓
pip config set global.index-url 源链接
就拿清华源来说,我们只需要执行 ↓
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
再来看看我们的速度,如下图所示:
源地址都变了,速度也杠杠的,怎么样,舒服吧?
/4 小结/
本文主要涉及两个点,其一是介绍了国内源列表,主要有5个,详情见正文;其二是例证了永久换源命令:
pip config set global.index-url 源链接
清华源示例
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
我们只需要记住这些,就OK了,各位要多多尝试噢!谢谢观看,谢谢支持!