热门
万字长文:一文彻底搞懂Elasticsearch中Geo数据类型查询、聚合、排序
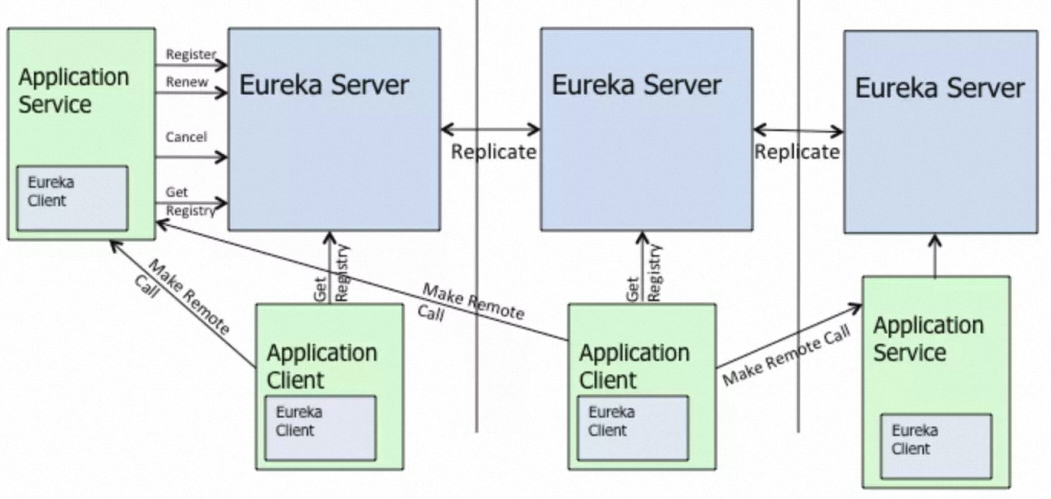
上一任留下的 Eureka,我该如何提升她的性能和稳定性(含数据比对)?
蚂蚁流场景状态演进和优化
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
NumPy数组基础:创建与访问详解
js绑定事件的方法
js和jquery的区别
JavaScript如何判断一个对象是否为数组?
ajax框架格式,每个属性的作用
创建对象的方法有哪些
不了解冒泡排序的原理?
JavaScript的math对象是什么? 有什么用
js字符串的相关方法
js遍历数组和对象的常用方法
JavaScript的数据类型
js控制浏览器前进、后退、页面跳转
js改变元素的内容、属性、样式
js中null和undefined的区别是什么
js中如何判断 NaN
jquery的书写格式,简单的使用方法
js实现走马灯效果
js怎么删除html元素
js中常见的几种事件
js如何获得浏览器的宽高
【PolarDB-X从入门到精通】 第五讲:PolarDB集中式版安装部署(源码编译部署)
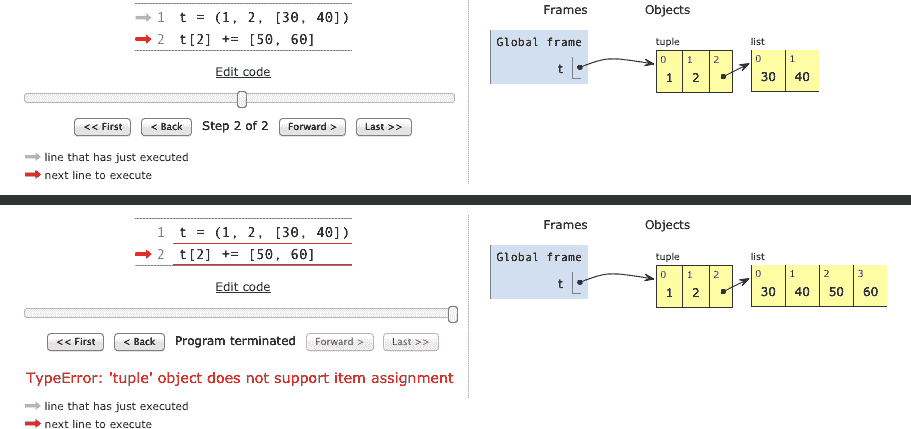
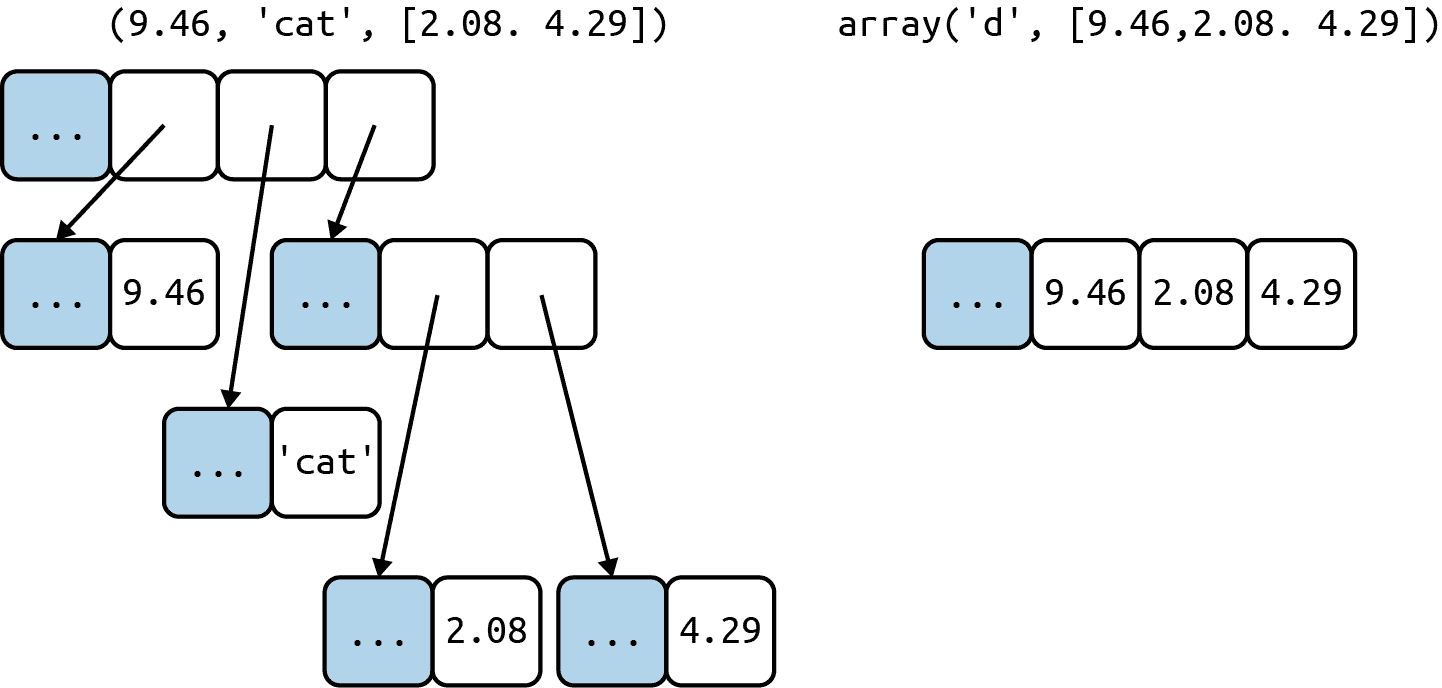
流畅的 Python 第二版(GPT 重译)(一)
性能提升30%!中国电信进一步开源12B星辰大模型TeleChat-12B!魔搭社区最佳实践来啦!
探索Elasticsearch在Java环境下的全文检索应用实践
Python中的装饰器:提升代码可读性与灵活性
探秘Java虚拟机(JVM)性能调优:技术要点与实战策略
现代化软件开发中的微服务架构设计与实践
高性能 MySQL 第四版(GPT 重译)(四)(4)
高性能 MySQL 第四版(GPT 重译)(四)(3)
高性能 MySQL 第四版(GPT 重译)(四)(2)
高性能 MySQL 第四版(GPT 重译)(四)(1)
优化前端性能:提升网页加载速度的10个技巧
Java Character 类
深度探索:使用Apache Kafka构建高效Java消息队列处理系统
高性能 MySQL 第四版(GPT 重译)(三)(4)
高性能 MySQL 第四版(GPT 重译)(三)(3)
高性能 MySQL 第四版(GPT 重译)(三)(2)
高性能 MySQL 第四版(GPT 重译)(三)(1)
Hadoop冗余数据存储
Python中的装饰器:提升代码灵活性与可维护性
什么是数组,什么是对象,并说出他们的区别
js的入口函数,入口函数的作用