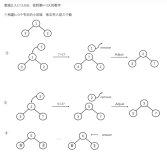
一、前言
排序算法大家都很熟悉了,解法多种多样。
有一个问题和排序算法很相近,TopK问题:从N个数中选出最大的K个数,N通常远大于K。
总结了一些解法,供大家参考。
二、冒泡
private static float[] pickTopKByBubbleSort(float[] a, int k) {
int n = a.length;
for (int i = 0; i < k; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (a[j] > a[j + 1]) {
float t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
}
}
}
float[] r = new float[k];
for (int i = 0; i < k; i++) {
r[i] = a[n - i - 1];
}
return r;
}冒泡排序的要义在于:外循环为排序趟数,内循环为每趟比较的次数,每趟得到一个最大的数,放到这一趟的末端。
如果是全数组排序的话,复杂度为O(n^2), 如果只选TopK的话,复杂度为O(n*k)。
三、堆
private static float[] pickTopKByHeapSort(float a[], int k) {
int n = a.length;
PriorityQueue<Float> queue = new PriorityQueue<>(n);
for (int i = 0; i < k; i++) {
queue.offer(a[i]);
}
for (int i = k; i < n; i++) {
if (a[i] > queue.peek()) {
queue.poll();
queue.offer(a[i]);
}
}
float[] r = new float[k];
for (int i = k - 1; i >= 0; i--) {
r[i] = queue.poll();
}
return r;
}堆的实现,在JDK中对应的是PriorityQueue,默认情况下是最小堆。
元素插入和删除的时间复杂度都是O(logn)。
堆可以用于排序:将所有元素插入堆中,在依次取出,即可得到有序排列的元素,时间复杂度为O(nlogn)。
如果按照上面冒泡排序的做法,将所有元素插入,再取出K个:
插入时间复杂度为O(nlogn), 取出的时间复杂度为O(klogn), 总体时间复杂度还是O(nlogn)。
当然,虽然复杂度都是O(nlogn),但是比全体元素排序快一点(不用取尽n个元素)。
堆在TopK问题上更优的解法是:
1、只放k个元素到堆中,然后遍历剩下的元素,和堆顶的元素(堆中最小的值)比较,
2、若大于堆顶,则取出堆顶的元素,插入当前元素;若小于等于堆顶,直接跳过;
3、最后依次取出堆中元素。
平均时间复杂度为O(nlogk);
最快的情况下是O(n),如果数组本身已经有序且是逆序的话。
四、快排
先来看下快排的实现:
private static int partition(float[] a, int left, int right) {
int i = left;
int j = right;
float key = a[left];
while (i < j) {
while (i < j && a[j] <= key) {
j--;
}
a[i] = a[j];
while (i < j && a[i] >= key) {
i++;
}
a[j] = a[i];
}
a[i] = key;
return i;
}
private static void sort(float[] a, int left, int right) {
if (left >= right) {
return;
}
int index = partition(a, left, right);
sort(a, left, index - 1);
sort(a, index + 1, right);
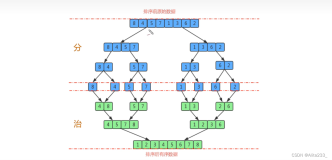
}快排的基本思想是:
1、通过一趟排序将要数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的数据都要小;
2、然后再按此方法对这两部分数据分别进行第1步的操作(递归),以此达到整个数据变成有序序列。
在TopK问题上,可以借鉴以上第1点,以及第2点的一部分:递归。
不同之处在于,求解TopK不需要对整个数据排序,只需要最大的K个数移动到数组的第K个位置的前面即可。
代码如下:
private static void sort(float[] a, int left, int right, int k) {
if (left >= right) {
return;
}
int index = partition(a, left, right);
int len = index - left + 1;
if (k < len) {
sort(a, left, index - 1, k);
} else if (k > len) {
sort(a, index + 1, right, k - len);
}
}
private static float[] pickTopKByQuickSort(float a[], int k) {
sort(a, 0, a.length - 1, k);
float[] r = new float[k];
for (int i = 0; i < k; i++) {
r[i] = a[i];
}
// 执行以上操作之后,r[]数组确实包含了top k的元素,但是不一定有序
// 如果仅仅是要求TopK而不需要有序,则不需要执行下面的排序函数
sort(r, 0, k - 1);
return r;
}最坏的情况下,时间复杂度和快排一样: O(n^2)。
平均情况下,快排的时间复杂度为O(nlogn),求解TopK时间复杂度为O(n)。
五、桶排序
冒泡排序,堆排序,快速排序等都是基于比较的排序,时间复杂度下限为O(nlogn)。
而有一些排序的时间复杂度可以是O(n), 比如桶排序和基数排序。
但是这类排序有较为苛刻的限制条件:元素须是数值类型。
同时,如果是桶排序的话,范围不能太大,否则需要的桶太多,空间复杂度无法接受。
桶排序的元素不一定要是整数,有时候浮点数也可以。
比如,如果数据取值范围在[0, 100.0], 并且只有两位小数, 可以这么解:
private static float[] pickTopKByBucketSort(float[] a, int k) {
int[] bucket = new int[10000];
for (int i = 0; i < a.length; i++) {
int index = Math.round(a[i] * 100f);
bucket[index]++;
}
float[] r = new float[k];
int p = 0;
for (int i = bucket.length - 1; i >= 0 && p < k; i--) {
int c = bucket[i];
while (c > 0 && p < k) {
r[p++] = i / 100f;
c--;
}
}
return r;
}取一万个桶,将每个元素乘以100,四舍五入为整数(有一些小数在计算机二进制中无法精确表示,同时直接强转成int的话是向下取整),
放到对应的桶中;
然后从最大的桶开始检索,收集100个元素。
时间复杂度跟数据量和桶数量(取决于数据的大小范围)有关。
在数据量远大于桶数量时,时间复杂度为O(n)。
六、测试
集成测试的代码如下:
public static void main(String[] args) {
int n = 100000;
int k = 100;
boolean success = true;
Random r = new Random();
for (int j = 0; j < 100; j++) {
float[] a = new float[n];
for (int i = 0; i < n; i++) {
float t = r.nextFloat() * 100f;
t = (int) (t * 100) / 100f;
a[i] = t;
}
float[] tmp = Arrays.copyOf(a, n);
float[] top1 = pickTopKByBubbleSort(tmp, k);
tmp = Arrays.copyOf(a, n);
float[] top2 = pickTopKByHeapSort(tmp, k);
tmp = Arrays.copyOf(a, n);
float[] top3 = pickTopKByQuickSort(tmp, k);
tmp = Arrays.copyOf(a, n);
float[] top4 = pickTopKByBucketSort(tmp, k);
if (!Arrays.equals(top1, top2)
|| !Arrays.equals(top1, top3)
|| !Arrays.equals(top1, top4)) {
success = false;
break;
}
}
if (success) {
System.out.println("success");
} else {
System.out.println("failed");
}
}七、总结
这么多种方案,那种方案比较好呢?这个要看情况。
- 冒泡的方法看起来时间复杂度是最高的,但是假如K很小,比如极端情况 , K=1,这时候冒泡的方法反而是最快的;
- 平均情况下,如果可以用的上桶排序(数据取值范围较小),那桶排序是最快的;
- 如果数值取值范围较小,而N很大(比方说100000),K又比较小(比方说100)时,运行发现堆的方法比快排的方法快。
原因猜测:范围小,数据多,应该有很多数值是重复的; 用堆的方法,堆会很快攒到Top的数值(即使还不是TopK),检索到那些小的数值的时候就不需要插入,从而检索后面的元素时,操作就只剩简单的遍历了。
跳脱排序算法和TopK问题本身,最主要的还是思想。
例如,日常项目中,堆(优先队列)就不时会遇到,这前提是脑海中知道有优先队列这个东西,知道它的特性。
有的知识就是这样的,专门去学的时候不知道有什么用,但或许某一天碰到了,就会想起它了。