以下为精彩视频内容整理:
实时计算概述
实时计算
阿里云实时计算(Alibaba Cloud Realtime Compute)是一套基于Apache Flink构建的一站式、高性能实时大数据处理平台,广泛适应于流式数据处理、离线数据处理等场景,最重要的一点是免运维,可以为企业节省了大量的成本。
产品模式
阿里云的实时计算产品模式有Flink云原生版和独享模式。目前Flink云原生版支持部署于容器服务ACK提供的Kubernetes。独享模式是指在阿里云ECS上单独为用户创建的独立计算集群。单个用户独享计算集群的物理资源(网络、磁盘、CPU或内存等),与其它用户的资源完全独立。独享模式分为包年包月和按量付费两种方式。
Flink简介
Flink是开源的流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。它的特点是支持高吞吐、低延迟、高性能的流处理,支持带有事件时间的窗口(Window)操作,支持有状态计算的Exactly-once语义,支持基于轻量级分布式快照(Snapshot)实现的容错,同时支持Batch on Streaming处理和Streaming处理,Flink在JVM内部实现了自己的内存管理,支持迭代计算,支持程序自动优化,避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存。
Flink架构图

阿里云的程序提交主要从客户端进行提交。其中,JobClient负责接收程序、解析程序的执行计划、优化程序的执行计划,然后提交执行计划到JobManager。JobManager主要负责申请资源,协调以及控制整个job的执行过程。TaskManager的主要作用是接收并执行JobManager发送的task,并且与JobManager通信,反馈任务状态信息。Slot是TaskManager资源粒度的划分,每个Slot都有自己独立的内存。所有Slot平均分配TaskManger的内存,比如TaskManager分配给Solt的内存为8G,两个Slot,每个Slot的内存为4G,并且Slot仅划分内存,不涉及cpu的划分。
Flink编程模型

在Flink编程模型中最低级的抽象仅提供状态流(stateful streaming),向上一层为DataStream API(数据流接口,有界/无界流)和DataSet API(数据集接口,有界数据集)。再向上为表接口(Table API),是以表为中心的声明性DSL,可以动态地改变表(当展示流的时候)。Flink提供的最高级抽象是SQL。阿里云的实时计算暂时不提供批处理。
Flink计算模型

Flink计算模型主要分为三部分,第一部分为Source,第二部分为Transformation,第三部分为Sink。每一个数据流起始于一个或多个Source,经过Transformation操作,对一个或多个输入Stream进行计算处理并终止于一个或多个Sink。
Flink的容错机制

Flink容错的核心机制是checkpoint,可以定期地将各个Operator处理的数据进行快照存储(Snapshot)。如果Flink程序出现宕机,可以重新从这些快照中恢复数据。Flink的checkpoint原理是Flink定期的向流应用中发送barrier,当算子收到barrier会暂停处理会将state制成快照,然后向下游广播barrier,直到Sink算子收到barrier,快照制作完成。阿里云的barrier是不参与计算的,并且是非常轻量的。
Spark Streaming与实时计算的对比
生态集成对比

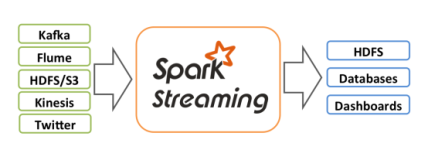
Spark Streaming数据源支持KafKa、Flume、HDFS/S3、Kinesis以及Twitter数据源,同样Flink也支持这些数据源。在数据计算中分为数据源表、数据结果表和数据维表。数据源表支持DataHub、消息队列MQ,KafKa、MaxCompute、表格存储TableStore。数据结果表支持分析型数据库MySQL版2.0、据总线DataHub、日志服务LOG结果表、消息队列MQ结果表、表格存储TableStore、云数据库RDS版、MaxCompute、云数据库HBase版、Elastic Search、Kafka、HybridDB for MySQL、自定义、云数据库MongoDB版、云数据库Redis版、云数据库RDS SQL Server版、分析型数据库MySQL版3.0结果表。数据维表支持表格存储TableStore、云数据库RDS版、云数据库HBase版、MaxCompute(ODPS)、ElasticSearch。
API对比
Spark Streaming支持底层的API是RDD,而Flink支持底层的API是Process Function。Spark Streaming核心API是DataFrame/DataSet/Structured Streaming,而Flink的核心API是DataStream/DataSet。Spark Streaming支持的SQL是Spark SQL,而Flink支持的SQL是Table API和 SQL。相同的是,Spark Streaming和Flink都支持机器学习,Spark Streaming支持MLlib,而Flink支持FlinkML。Spark Streaming支持的图计算是GraphX,而Flink支持Gelly。但阿里云的Flink在流计算方面更成熟一些。
数据处理模式对比

上图所示为Spark Streaming,是基于Spark高效的批处理能力,对流数据划分为多个小批数据,再分别对这些数据进行处理,即微批处理模式,运行的时候需要指定批处理的时间,每次运行作业时处理一个批次的数据。并不是真正的流计算,而是进行微批处理的。
上图所示为阿里云的Flink,是基于事件驱动的,事件可以理解为消息,即源源不断没有边界的数据,并且数据的状态可以改变,对于批处理则认为是有边界的流进行处理。
时间机制对比

Flink提供了3种时间模型:EventTime、ProcessingTime、IngestionTime,在实时计算中支持EventTime、ProcessingTime,而Spark Streaming仅支持ProcessingTime。其中,EventTime指事件生成时的时间,在进入Flink之前就已经存在,可以从event的字段中抽取。IngestionTime指事件进入Flink的时间,即在source里获取的当前系统的时间,后续操作统一使用该时间。ProcessingTime指执行操作的机器的当前系统时间(每个算子都不一样)。阿里云的Flink也提供了WaterMark用来处理时间乱序,Watermark是一个对Event Time的标识,这里的乱序是指有事件迟到了,对于迟到的元素,不可能无限期的等下去,必须要有一种机制来保证一个特定的时间后,必须触发window进行计算。比如计算一个10:00到10:10分的窗口,watermark设置延迟3s,当一条数据的watermark到达10:10:03,这个窗口才会触发,表示这个窗口的数据已经全部到了,然后进行计算并释放相关被占用的资源。
容错机制对比
Spark Streaming容错机制是利用Spark自身的容错设计、存储级别和RDD抽象设计,能够处理集群中任何worker节点的故障。Driver端利用checkpoint机制。对于接收的数据使用预写日志的形式。Flink的容错机制主要是基于checkpoint。定期地将各个Operator处理的数据进行快照存储(Snapshot)。
如何使用阿里云实时计算

上图所示为一个购买界面,分为master型号和slave型号。地域选择为当时所在的地方,master主要负责管理整个集群的资源和slave之间的交互,但不能用于计算。Slave主要负责计算。
创建项目

创建完集群之后,来到集群的控制台中,点击集群列表,找到对应的集群创建项目,填写项目名称和备注,其中CU指集群还剩余多少CU。1CU为1核4G,简单业务时,1CU每秒可以处理10000条数据。例如,单流过滤、字符串变换等操作。复杂业务时,1CU每秒可以处理1000到5000条数据。例如,JOIN、WINDOW、GROUP BY等操作。
作业开发

然后点击对应的项目,点击开发进入到开发界面,通过新建作业和文件夹的方式编写自己的DDL语句。对于资源引用,阿里云的Flink SQL支持UDF、DataStream。 再编写一个以DataHub为数据源,数据维表在RDS数据库中,结果表输出到RDS数据库中新建一个DatahubData文件夹,新建一个DatahubData作业。
数据存储

数据存储支持明文方式和存储注册方式。明文方式是通过在作业的DDL语句WITH参数中配置accessId和accessKey的方法。存储注册方式是将上下游存储资源预先注册至实时计算开发平台,然后通过实时计算控制台的数据存储管理功能,对上下游存储资源进行引用,可以对数据进行预览。阿里云采用存储注册的方式注册DataHub。填写对应的endpoint和项目的名称,单机作为输入表引用,就会在作业开发界面生成DDL语句。
注册数据结果表和维表

由于RDS数据库存在白名单限制,连接RDS需要添加白名单,独享模式的IP地址在集群列表页面,单击名称字段下目标集群名称,在集群信息窗口,查看集群的ENI信息。
编写自己SQL

从数据源表中过滤出place是北京的数据。Sql中使用了计算列,计算列的语法为column_name AS computed_column_expression,计算列可以使用其它列的数据,计算出其所属列的数值。如果您的数据源表中没有TIMESTAMP类型的列,可以使用计算列方法从其它类型的字段进行转换。
查看运维界面

Failover曲线显示当前作业出现Failover(错误或者异常)的频率。计算方法为当前Failover时间点的前1分钟内出现Failover的累计次数除以60(例如,最近1分钟Failover了一次,Failover的值为1/60=0.01667)。延迟分为业务延时、数据滞留时间及数据间隔时间。其中业务延迟指当前数据时间减去最后一条数据的时间,数据滞留时间指数据实时计算的时间减去eventime,数据间隔时间指业务延时减去数据滞留时间。Source的TPS数据是指直接读取数据源的数据,Source的RPS是指读取TPS解析后的数据。
本地调试

需要从本地上传对应的数据。
实时计算的使用限制
针对区域的限制,独享模式仅支持华东1(杭州)、华东2(上海)、华南1(深圳)、华北2(北京)地区。针对CU的处理能力,实时计算当前在内部压测场景下,一个CU的处理能力大约为:简单业务时,例如,单流过滤、字符串变换等操作,1CU每秒可以处理10000条数据。复杂业务时,例如,JOIN、WINDOW、GROUP BY等操作,1CU每秒可以处理1000到5000条数据。针对作业、任务数量限制,单个项目下允许最多创建业务的个数为100。单个项目下允许最多的文件夹的个数为50,层数最大不超过5层,单个项目下允许最多的UDX或JAR的个数为50,单个项目下允许最多注册数据存储的个数为50,单个作业允许最多的历史保存版本数为20。