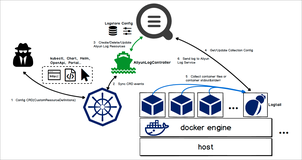
作为采集 agent,logtail 所采集的日志可能会就被用于对应用程序进行监控/告警,所以保证它自身处于正常状态对整个系统的稳定显得尤为重要。在之前的《全方位 Logtail 状态监控》中,我们曾介绍了关于监控 Logtail 各类状态的方法,包括基本的链路状态、资源使用情况等。
在本文中,我们将详细展开通过外围巡检获取 SLS 提供的状态信息来实现对 logtail 心跳状态的监控和告警,并提供可供直接使用的代码。
外围巡检
顾名思义,外围巡检即不访问实际运行 logtail 的机器,仅通过一些外部访问可获得的状态信息来进行巡检。因为是巡检,自然会受到监控规模的限制,因此,此方法适用于 logtail 实例数量较少(比如少于 500 台)或是对发现异常的实时性要求较低(比如半小时内发现)的场景。
SLS 提供的状态信息
在实践中,我们可以通过以下两项 SLS 提供的信息来进行巡检:
- ListMachines API:在日志服务中,正在采集日志的 logtail 实例在逻辑上会属于至少一个机器组,因此,通过此 API 查询指定机器组,即可得到该组内 logtail 实例在 SLS 服务端的状态,辅助我们进行巡检判断。
- 服务日志中的 logtail 状态日志:在正常情况下,logtail 会在每分钟上报一条状态日志至 SLS 服务端,通过开通服务日志(不开通操作日志的情况下完全免费),我们即可获取到这些状态日志,进而判断 logtail 实例的状态日志上报是否依旧正常。
巡检流程
假定监控对象为单个 project,实时性要求为 15 分钟,我们推荐按照如下流程来组合上述的两项信息以实现外围巡检:
- 对于 project 下的每个机器组,调用 ListMachines API 来获取该机器组内所有机器的状态,其中有个 lastHeartbeatTime 表示对应机器上 logtail 实例在服务端的最近心跳时间。通过对比当前时间,配合上特定阈值(比如 10 分钟),即可筛选出潜在的异常机器(现阶段,ListMachines 返回的心跳时间可能会有延时,因此只是潜在机器)。
2.借助 logtail 状态日志来做进一步地确认。因为服务日志也存储在 SLS 的 logstore 中,所以可以通过 API 在对应 logstore 中查询相关内容,根据结果来进行确认。比如使用如下语句来查询特定 logtail 实例最近 10 分钟内的状态日志数量,如果少于 8 条,认为它是异常。
# 单个查询
__topic__: logtail_status and ip: "192.168.1.1" | select count(*) as c
# 为了提高效率,可以批量查询多个 IP(不超过 25 个)
__topic__: logtail_status and (ip:"192.168.1.1" or ip:"192.168.1.2") | select ip, count(*) as c group by ip巡检结果告警
在通过巡检得到异常结果后,我们可以直接将此信息写入到特定 logstore,然后利用 SLS 的告警功能来进行通知。目前,告警功能支持短信、邮件、钉钉、WebHook 等多种通知方式。
实践示例
代码及其使用方法
巡检脚本的代码已托管至 Github,欢迎 PR。脚本的使用方式如下:
- 选择周期性运行的环境:任意可访问 SLS 服务端的机器或是托管到相同区域内的函数计算服务。
-
配置 heartbeat_monitor.py 脚本中的参数,主要是以下参数:
- project_name: 需要监控的 SLS 项目,默认为监控该 project 下的所有机器组;
- endpoint:SLS 项目对应的 endpoint,比如 cn-hangzhou.log.aliyuncs.com;
- logtail_status_project_name:SLS 项目的服务日志的存放位置,一般为 log-service--<区域名>,比如 log-service-123232323-cn-hangzhou;
- report_logstore:用于上报巡检异常结果的 logstore(默认为相同 project),需手动创建,如未指定,异常信息仅会输出在本地。
- 配置周期执行该脚本,比如在机器上创建一个 crontab 任务,每 5 分钟执行一次。
# 假设脚本部署在 HOME 目录下
(crontab -l 2>/dev/null; echo "*/5 * * * * python ~/heartbeat_monitor.py > ~/heartbeat_monitor.log") | crontab -告警配置
因为只有在发生异常的时候,巡检脚本才会向 report_logstore 中写入异常信息,所以我们可以直接监控该 logstore 中是否有日志,有的话就进行告警。
查询语句如下:
* | select count(*) as c告警配置(每 3 分钟执行一次):

可根据需要配置合适的告警通知方式,如下为钉钉机器人告警的示例: