作者:祝威廉,资深数据架构,11年研发经验。同时维护和开发多个开源项目。擅长大数据/AI领域的一些思路和工具。现专注于构建集大数据和机器学习于一体的综合性平台,降低AI落地成本相关工作上。
什么是Ray
之前花了大概两到三天把Ray相关的论文,官网文档看了一遍,同时特意去找了一些中文资料看Ray当前在国内的发展情况(以及目前国内大部分人对Ray的认知程度)。
先来简单介绍下我对Ray的认知。
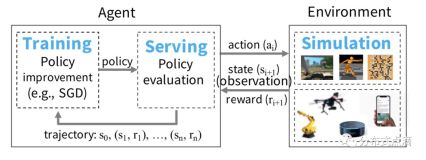
首先基因很重要,所以我们先需要探查下Ray最初是为了解决什么问题而产生的。Ray的论文显示,它最早是为了解决增强学习的挑战而设计的。增强学习的难点在于它是一个需要边学习,边做实时做预测的应用场景,这意味会有不同类型的tasks同时运行,并且他们之间存在复杂的依赖关系,tasks会在运行时动态产生产生新的tasks,现有的一些计算模型肯定是没办法解决的。如果Ray只是为了解决RL事情可能没有那么复杂,但是作者希望它不仅仅能跑增强学习相关的,希望是一个通用的分布式机器学习框架,这就意味着Ray必然要进行分层抽象了,也就是至少要分成系统层和应用层。
系统层面,既然是分布式的应用,那么肯定需要有一个应用内的resource/task调度和管理。首先是Yarn,K8s等资源调度框架是应用程序级别的的调度,Ray作为一个为了解决具体业务问题的应用,应该要跑在他们上面而不是取代他们,而像Spark/Flink虽然也是基于task级别的资源调度框架,但是因为他们在设计的时候是为了解决一个比较具体的抽象问题,所以系统对task/资源都做了比较高的封装,一般用户是面向业务编程,很难直接操控task以及对应的resource。我们以Spark为例,用户定义好了数据处理逻辑,至于如何将这些逻辑分成多少个Job,Stage,Task,最后占用多少Resource (CPU,GPU,Memory,Disk)等等,都是由框架自行决定,而用户无法染指。这也是我一直诟病Spark的地方。所以Ray在系统层面,是一个通用的以task为调度级别的,同时可以针对每个task控制资源粒度的一个通用的分布式task执行系统。记住,在Ray里,你需要明确定义Task以及Task的依赖,并且为每个task指定合适(数量,资源类型)的资源。比如你需要用三个task处理一份数据,那么你就需要自己启动三个task,并且指定这些task需要的资源(GPU,CPU)以及数量(可以是小数或者整数)。而在Spark,Flink里这是不大可能的。Ray为了让我们做这些事情,默认提供了Python的语言接口,你可以像使用Numpy那样去使用Ray。实际上,也已经有基于Ray做Backend的numpy实现了,当然它属于应用层面的东西了。Ray系统层面很简单,也是典型的master-worker模式。类似spark的driver-executor模式,不同的是,Ray的worker类似yarn的worker,是负责Resource管理的,具体任务它会启动Python worker去执行你的代码,而spark的executor虽然也会启动Python worker执行python代码,但是对应的executor也执行业务逻辑,和python worker有数据交换和传输。
应用层面,你可以基于Ray的系统进行编程,因为Ray默认提供了Python的编程接口,所以你可以自己实现增强学习库(RLLib),也可以整合已有的算法框架,比如tensorflow,让tensorflow成为Ray上的一个应用,并且轻松实现分布式。我记得知乎上有人说Ray其实就是一个Python的分布式RPC框架,这么说是对的,但是显然会有误导,因为这很可能让人以为他只是“Python分布式RPC框架”。
如何和Spark协作
根据前面我讲述的,我们是可以完全基于Ray实现Spark的大部分API的,只是是Ray backend而非Spark core backend。实际上Ray目前正在做流相关的功能,他们现在要做的就是要兼容Flink的API。虽然官方宣称Ray是一个新一代的机器学习分布式框架,但是他完全可以cover住当前大数据和AI领域的大部分事情,但是任重道远,还需要大量的事情。所以对我而言,我看中的是它良好的Python支持,以及系统层面对资源和task的控制,这使得:
1.我们可以轻易的把我们的单机Python算法库在Ray里跑起来(虽然算法自身不是分布式的),但是我们可以很好的利用Ray的资源管理和调度功能,从而解决AI平台的资源管理问题。
2.Ray官方提供了大量的机器学习算法的实现,以及对当前机器学习框架如Tensorflow,Pytorch的整合,而分布式能力则比这些库原生提供的模式更靠谱和易用。毕竟对于这些框架而言,支持他们分布式运行的那些辅助库(比如TensorFlow提供parameter servers)相当简陋。
但是,我们知道,数据处理它自身有一个很大的生态,比如你的用户画像数据都在数据湖里,你需要把这些数据进行非常复杂的计算才能作为特征喂给你的机器学习算法。而如果这个时候,你还要面向资源编程(或者使用一个还不够成熟的上层应用)而不是面向“业务”编程,这就显得很难受了,比如我就想用SQL处理数据,我只关注处理的业务逻辑,这个当前Ray以及之上的应用显然还是做不到如Spark那么便利的(毕竟Spark就是为了数据处理而生的),所以最好的方式是,数据的获取和加工依然是在Spark之上,但是数据准备好了就应该丢给用户基于Ray写的代码处理了。Ray可以通过Arrow项目读取HDFS上Spark已经处理好的数据,然后进行训练,然后将模型保存为HDFS。当然对于预测,Ray可以自己消化掉或者丢给其他系统完成。我们知道Spark 在整合Python生态方面做出了非常多的努力,比如他和Ray一样,也提供了python 编程接口,所以spark也较为容易的整合譬如Tensorflow等框架,但是没办法很好的管控资源(比如GPU),而且,spark 的executor 会在他所在的服务器上启动python worker,而spark一般而言是跑在yarn上的,这就对yarn造成了很大的管理麻烦,而且通常yarn 和hdfs之类的都是在一起的,python环境还有资源(CPU/GPU)除了管理难度大以外,还有一个很大的问题是可能会对yarn的集群造成比较大的稳定性风险。
所以最好的模式是按如下步骤开发一个机器学习应用:
写一个python脚本,
在数据处理部分,使用pyspark,
在程序的算法训练部分,使用ray,
spark 运行在yarn(k8s)上,
ray运行在k8s里好处显而易见:用户完全无感知他的应用其实是跑在两个集群里的,对他来说就是一个普通python脚本。
从架构角度来讲,复杂的python环境管理问题都可以丢给ray集群来完成,spark只要能跑基本的pyspark相关功能即可,数据衔接通过数据湖里的表(其实就是一堆parquet文件)即可。当然,如果最后结果数据不大,也可以直接通过client完成pyspark到ray的交互。
Spark和Ray的架构和部署
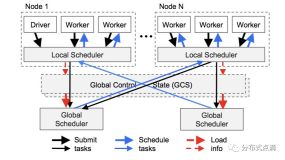
现在我们来思考一个比较好的部署模式,架构图大概类似这样:
首先,大家可以理解为k8s已经解决一切了,我们spark,ray都跑在K8s上。但是,如果我们希望一个spark 是实例多进程跑的时候,我们并不希望是像传统的那种方式,所有的节点都跑在K8s上,而是将executor部分放到yarn cluster. 在我们的架构里,spark driver 是一个应用,我们可以启动多个pod从而获得多个spark driver实例,对外提供负载均衡,roll upgrade/restart 等功能。也就是k8s应该是面向应用的。但是复杂的计算,我们依然希望留给Yarn,尤其是还涉及到数据本地性,计算和存储放到一起(yarn和HDFS通常是在一起的),避免k8s和HDFS有大量数据交换。
因为Yarn对Java/Scala友好,但是对Python并不友好,尤其是在yarn里涉及到Python环境问题会非常难搞(主要是Yarn对docker的支持还是不够优秀,对GPU支持也不好),而机器学习其实一定重度依赖Python以及非常复杂的本地库以及Python环境,并且对资源调度也有比较高的依赖,因为算法是很消耗机器资源的,必须也有资源池,所以我们希望机器学习部分能跑在K8s里。但是我们希望整个数据处理和训练过程是一体的,算法的同学应该无法感知到k8s/yarn的区别。为了达到这个目标,用户依然使用pyspark来完成计算,然后在pyspark里使用ray的API做模型训练和预测,数据处理部分自动在yarn中完成,而模型训练部分则自动被分发到k8s中完成。并且因为ray自身的优势,算法可以很好的控制自己需要的资源,比如这次训练需要多少GPU/CPU/内存,支持所有的算法库,在做到对算法最少干扰的情况下,算法的同学们有最好的资源调度可以用。
下面展示一段MLSQL代码片段展示如何利用上面的架构:
-- python 训练模型的代码
set py_train='''
import ray
ray.init()
@ray.remote(num_cpus=2, num_gpus=1)
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))
''';
load script.`py_train` as py_train;
-- 设置需要的python环境描述
set py_env='''
''';
load script.`py_env` as py_env;
-- 加载hive的表
load hive.`db1.table1` as table1;
-- 对Hive做处理,比如做一些特征工程
select features,label from table1 as data;
-- 提交Python代码到Ray里,此时是运行在k8s里的
train data as PythonAlg.`/tmp/tf/model`
where scripts="py_train"
and entryPoint="py_train"
and condaFile="py_env"
and keepVersion="true"
and fitParam.0.fileFormat="json" -- 还可以是parquet
and `fitParam.0.psNum`="1";下面是PySpark的示例代码:
from pyspark.ml.linalg import Vectors, SparseVector
from pyspark.sql import SparkSession
import logging
import ray
from pyspark.sql.types import StructField, StructType, BinaryType, StringType, ArrayType, ByteType
from sklearn.naive_bayes import GaussianNB
import os
from sklearn.externals import joblib
import pickle
import scipy.sparse as sp
from sklearn.svm import SVC
import io
import codecs
os.environ["PYSPARK_PYTHON"] = "/Users/allwefantasy/deepavlovpy3/bin/python3"
logger = logging.getLogger(__name__)
base_dir = "/Users/allwefantasy/CSDNWorkSpace/spark-deep-learning_latest"
spark = SparkSession.builder.master("local[*]").appName("example").getOrCreate()
data = spark.read.format("libsvm").load(base_dir + "/data/mllib/sample_libsvm_data.txt")
## 广播数据
dataBr = spark.sparkContext.broadcast(data.collect())
## 训练模型 这部分代码会在spark executor里的python worker执行
def train(row):
import ray
ray.init()
train_data_id = ray.put(dataBr.value)
## 这个函数的python代码会在K8s里的Ray里执行
@ray.remote
def ray_train(x):
X = []
y = []
for i in ray.get(train_data_id):
X.append(i["features"])
y.append(i["label"])
if row["model"] == "SVC":
gnb = GaussianNB()
model = gnb.fit(X, y)
# 为什么还需要encode一下?
pickled = codecs.encode(pickle.dumps(model), "base64").decode()
return [row["model"], pickled]
if row["model"] == "BAYES":
svc = SVC()
model = svc.fit(X, y)
pickled = codecs.encode(pickle.dumps(model), "base64").decode()
return [row["model"], pickled]
result = ray_train.remote(row)
ray.get(result)
##训练模型 将模型结果保存到HDFS上
rdd = spark.createDataFrame([["SVC"], ["BAYES"]], ["model"]).rdd.map(train)
spark.createDataFrame(rdd, schema=StructType([StructField(name="modelType", dataType=StringType()),
StructField(name="modelBinary", dataType=StringType())])).write. \
format("parquet"). \
mode("overwrite").save("/tmp/wow")这是一个标准的Python程序,只是使用了pyspark/ray的API,我们就完成了上面所有的工作,同时训练两个模型,并且数据处理的工作在spark中,模型训练的在ray中。
完美结合!最重要的是解决了资源管理的问题!
对开源大数据和感兴趣的同学可以加小编微信(图一二维码,备注进群)进入技术交流微信群。也可钉钉扫码加入社区的钉钉群

阿里巴巴开源大数据技术团队成立Apache Spark中国技术社区,定期推送精彩案例,技术专家直播,问答区数个Spark技术同学每日在线答疑,只为营造纯粹的Spark氛围,欢迎钉钉扫码加入!