前言
本文将介绍在Blink实时计算平台建立以Tablestore作为流计算的源表以及结果表作业的流程。
表格存储通道服务
表格存储通道服务是基于表格存储(Tablestore)数据接口之上的全增量一体化服务,它通过一组Tunnel Service API和SDK为用户提供了增量、全量和增量加全量三种类型的分布式数据实时消费通道。通过为数据表建立Tunnel Service数据通道,用户可以通过流式计算的方式对表中历史存量和新增的数据进行消费处理。
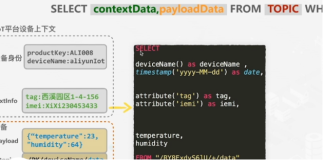
流计算能将Tunnel Service数据通道作为流式数据的输入,每条数据类似一个JSON格式,如下所示:
{
"OtsRecordType": "PUT", // 数据操作类型,包括PUT、UPDATE、DELETE
"OtsRecordTimestamp": 1506416585740836, //数据写入时间(微秒),全量数据时为0
"PrimaryKey": [
{
"ColumnName": "pk_1", //第一主键列
"Value": 1506416585881590900
},
{
"ColumnName": "pk_2", //第二主键列
"Value": "string_pk_value"
}
],
"Columns": [
{
"OtsColumnType": "Put", // 列操作类型,包括PUT、DELETE_ONE_VERSION、DELETE_ALL_VERSION
"ColumnName": "attr_0",
"Value": "hello_table_store",
},
{
"OtsColumnType": "DELETE_ONE_VERSION", // DELETE操作没有Value字段
"ColumnName": "attr_1"
}
]
}其中,数据的各个主键和属性列值均可以在BLINK DDL以列名以及相应的类型映射读取,例如上述实例,我们需要定义的DDL如下所示:
create table tablestore_stream(
pk_1 BIGINT,
pk_2 VARCHAR,
attr_0 VARCHAR,
attr_1 DOUBLE,
primary key(pk_1, pk_2)
) with (
type ='ots',
endPoint ='http://blink-demo.cn-hangzhou.vpc.tablestore.aliyuncs.com',
instanceName = "blink-demo",
tableName ='demo_table',
tunnelName = 'blink-demo-stream',
accessId ='xxxxxxxxxxx',
accessKey ='xxxxxxxxxxxxxxxxxxxxxxxxxxxx',
ignoreDelete = 'false' //是否忽略delete操作的数据
);如果字段名称有前缀,需要使用反撇,例:OTS字段名称为TEST.test,BLINK DDL定义为TEST.test。而OtsRecordType、OtsRecordTimestamp字段以及每个Column的OtsColumnType字段都会支持通过属性字段的方式读取:
| 字段名 | 说明 |
|---|---|
| OtsRecordType | 数据操作类型 |
| OtsRecordTimestamp | 数据操作时间(全量数据时为0) |
| 列名_OtsColumnType | 以具体列名和_"_____OtsColumnType__"_拼接,某列的操作类型 |
需要OtsRecordType和某些Column的OtsColumnType字段时,Blink提供了 HEADER 关键字用于获取源表中的属性字段,具体DDL:
create table tablestore_stream(
OtsRecordType VARCHAR HEADER,
OtsRecordTimestamp BIGINT HEADER,
pk_1 BIGINT,
pk_2 VARCHAR,
attr_0 VARCHAR,
attr_1 DOUBLE,
attr_1_OtsColumnType VARCHAR HEADER,
primary key(pk_1, pk_2)
) with (
...
);WITH参数
| 参数 | 注释说明 | 备注 |
|---|---|---|
| endPoint | 表格存储的实例访问地址 | endPoint |
| instanceName | 表格存储的实例名称 | instanceName |
| tableName | 表格存储的数据表名 | tableName |
| tunnelName | 表格存储数据表的数据通道名 | tunnelName |
| accessId | 表格存储读取的accessKey | accessId |
| accessKey | 表格存储读取的秘钥 | |
| ignoreDelete | 是否忽略DELETE操作类型的实时数据 | 可选,默认为false |
SQL示例
数据同步,ots sink会以update的方式写入结果表:
create table otsSource (
pkstr VARCHAR,
pklong BIGINT,
col0 VARCHAR,
primary key(pkstr, pklong)
) WITH (
type ='ots',
endPoint ='http://blink-demo.cn-hangzhou.ots.aliyuncs.com',
instanceName = "blink-demo",
tableName ='demo_table',
tunnelName = 'blink-demo-stream',
accessId ='xxxxxxxxxxx',
accessKey ='xxxxxxxxxxxxxxxxxxxxxxxxxxxx',
ignoreDelete = 'true'
);
CREATE TABLE otsSink (
pkstr VARCHAR,
pklong BIGINT,
col0 VARCHAR,
primary key(pkstr, pklong)
) WITH (
type='ots',
instanceName='blink-target',
tableName='demo_table',
accessId ='xxxxxxxxxxx',
accessKey ='xxxxxxxxxxxxxxxxxxxxxxxxxxxx',
endPoint='https://blink-target.cn-hangzhou.ots.aliyuncs.com',
valueColumns='col0'
);
INSERT INTO otsSink
SELECT t.pkstr, t.pklong, t.col0
FROM otsSource AS t流计算作业建立流程
在Blink实时计算平台数据开发模块建立新任务,并填写节点类型、Blink版本、节点名称以及目标文件夹等相关内容,如下图所示:
新建任务之后,进入该任务,点击切换为SQL模式按钮。按照之前介绍的DDL定义开发自己的任务。如下图所示:
作业完成之后,点击发布,选择运行环境及配置可用CU,此次建立的流式作业就正式启动了,可通过运维界面管理作业以及查看作业运行相关信息。如下图所示: