一、常规抓包分析
比如要爬取企业注册信息查询_企业工商信息查询_企业信用信息查询平台_发现人与企业关系的平台-天眼查该页面的基础信息。
通过火狐浏览器抓包,可以发现,所要数据都在下图的json文件里
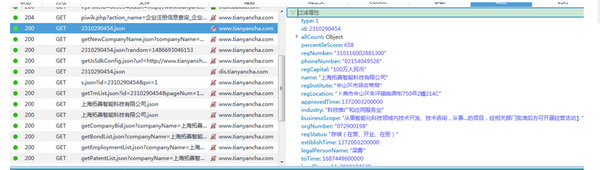
查看其请求
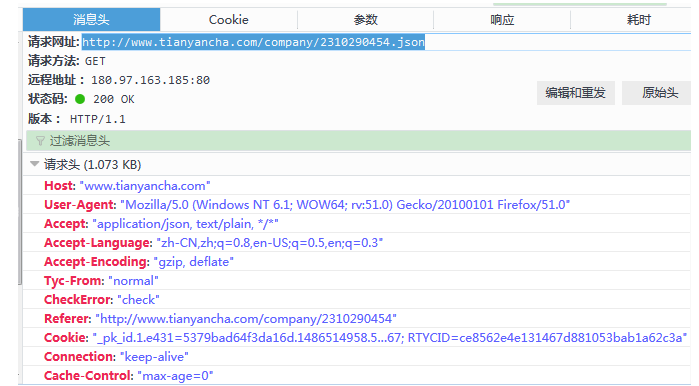
伪装成浏览器爬取该文件:
伪装成浏览器爬取该文件:
import requests
header = {
'Host': 'www.tianyancha.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Tyc-From': 'normal',
'CheckError': 'check',
'Connection': 'keep-alive',
'Referer': 'http://www.tianyancha.com/company/2310290454',
'Cache-Control': 'max-age=0'
,
'Cookie': '_pk_id.1.e431=5379bad64f3da16d.1486514958.5.1486693046.1486691373.; Hm_lvt_e92c8d65d92d534b0fc290df538b4758=1486514958,1486622933,1486624041,1486691373; _pk_ref.1.e431=%5B%22%22%2C%22%22%2C1486691373%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3D95IaKh1pPrhNKUe5nDCqk7dJI9ANLBzo-1Vjgi6C0VTd9DxNkSEdsM5XaEC4KQPO%26wd%3D%26eqid%3Dfffe7d7e0002e01b00000004589c1177%22%5D; aliyungf_tc=AQAAAJ5EMGl/qA4AKfa/PDGqCmJwn9o7; TYCID=d6e00ec9b9ee485d84f4610c46d5890f; tnet=60.191.246.41; _pk_ses.1.e431=*; Hm_lpvt_e92c8d65d92d534b0fc290df538b4758=1486693045; token=d29804c0b88842c3bb10c4bc1d48bc80; _utm=55dbdbb204a74224b2b084bfe674a767; RTYCID=ce8562e4e131467d881053bab1a62c3a'
}
r = requests.get('http://www.tianyancha.com/company/2310290454.json', headers=header)
print(r.text)
print(r.status_code)
返回结果如下:
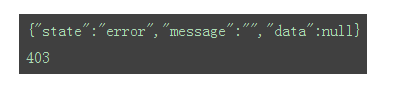
状态码为403,常规爬取不成功。考虑下面一种方式。
二、使用selenium+PHANTOMJS获取数据
首先下载phantomjs到本地,并将phantomjs.exe存放在系统环境变量所在目录下(本人讲该文件放置在D:/Anaconda2/路径下)。
为phantomjs添加useragent信息(经测试,不添加useragent信息爬取到的是错乱的信息):
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0"
)
driver = webdriver.PhantomJS(executable_path='D:/Anaconda2/phantomjs.exe', desired_capabilities=dcap)
获取网页源代码:
driver.get('http://www.tianyancha.com/company/2310290454')
#等待5秒,更据动态网页加载耗时自定义
time.sleep(5)
# 获取网页内容
content = driver.page_source.encode('utf-8')
driver.close()
print(content)
对照网页,爬取的源代码信息正确,接下去解析代码,获取对应的信息。
简单写了下获取基础信息的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
from bs4 import BeautifulSoup
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def driver_open():
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0"
)
driver = webdriver.PhantomJS(executable_path='D:/Anaconda2/phantomjs.exe', desired_capabilities=dcap)
return driver
def get_content(driver,url):
driver.get(url)
#等待5秒,更据动态网页加载耗时自定义
time.sleep(5)
# 获取网页内容
content = driver.page_source.encode('utf-8')
driver.close()
soup = BeautifulSoup(content, 'lxml')
return soup
def get_basic_info(soup):
company = soup.select('div.company_info_text > p.ng-binding')[0].text.replace("\n","").replace(" ","")
fddbr = soup.select('.td-legalPersonName-value > p > a')[0].text
zczb = soup.select('.td-regCapital-value > p ')[0].text
zt = soup.select('.td-regStatus-value > p ')[0].text.replace("\n","").replace(" ","")
zcrq = soup.select('.td-regTime-value > p ')[0].text
basics = soup.select('.basic-td > .c8 > .ng-binding ')
hy = basics[0].text
qyzch = basics[1].text
qylx = basics[2].text
zzjgdm = basics[3].text
yyqx = basics[4].text
djjg = basics[5].text
hzrq = basics[6].text
tyshxydm = basics[7].text
zcdz = basics[8].text
jyfw = basics[9].text
print u'公司名称:'+company
print u'法定代表人:'+fddbr
print u'注册资本:'+zczb
print u'公司状态:'+zt
print u'注册日期:'+zcrq
# print basics
print u'行业:'+hy
print u'工商注册号:'+qyzch
print u'企业类型:'+qylx
print u'组织机构代码:'+zzjgdm
print u'营业期限:'+yyqx
print u'登记机构:'+djjg
print u'核准日期:'+hzrq
print u'统一社会信用代码:'+tyshxydm
print u'注册地址:'+zcdz
print u'经营范围:'+jyfw
def get_gg_info(soup):
ggpersons = soup.find_all(attrs={"event-name": "company-detail-staff"})
ggnames = soup.select('table.staff-table > tbody > tr > td.ng-scope > span.ng-binding')
# print(len(gg))
for i in range(len(ggpersons)):
ggperson = ggpersons[i].text
ggname = ggnames[i].text
print (ggperson+" "+ggname)
def get_gd_info(soup):
tzfs = soup.find_all(attrs={"event-name": "company-detail-investment"})
for i in range(len(tzfs)):
tzf_split = tzfs[i].text.replace("\n","").split()
tzf = ' '.join(tzf_split)
print tzf
def get_tz_info(soup):
btzs = soup.select('a.query_name')
for i in range(len(btzs)):
btz_name = btzs[i].select('span')[0].text
print btz_name
if __name__=='__main__':
url = "http://www.tianyancha.com/company/2310290454"
driver = driver_open()
soup = get_content(driver, url)
print '----获取基础信息----'
get_basic_info(soup)
print '----获取高管信息----'
get_gg_info(soup)
print '----获取股东信息----'
get_gd_info(soup)
print '----获取对外投资信息----'
get_tz_info(soup)
这仅仅是单页面的一个示例,要写完整的爬虫项目加工,以后再花时间改进。