摘要:2016中国高校计算机大赛——大数据挑战赛是由教育部和全国高等学校计算机教育研究会联合主办,清华大学和阿里云联合承办,在“天池大数据众智平台”上开展的高端算法竞赛。本次赛题是对于阿里音乐流行趋势进行预测,本文整理自大赛冠军团队Datahacker团队的答辩演讲。
本文整理自获得本次2016中国高校计算机大赛阿里音乐流行趋势预测比赛冠军的Datahacker团队的答辩视频。Datahacker团队由三名成员组成,成员简介如下:

Datahacker团队的答辩主要从以下四个方面进行论述:
一、赛题分析
二、规则算法
三、模型算法
四、重要的事情
一、赛题分析
本次大数据挑战赛以阿里音乐用户的历史播放数据为基础,期望参赛者可以通过对阿里音乐平台上每个阶段艺人的试听量的预测,挖掘出即将成为潮流的艺人,从而实现对一个时间段内音乐流行趋势的准确把控。从下图中给出的测评公式,可以看出真实的播放量是在分母上边的,所以如果真实的播放量比较小的话,那么将会误差将会非常大,甚至在测试里面则会出现负分。基于这样的认识,在相同的可能情况下,Datahacker团队预测的播放量要偏小一些,所以测评的得分会大于偏大的情况。

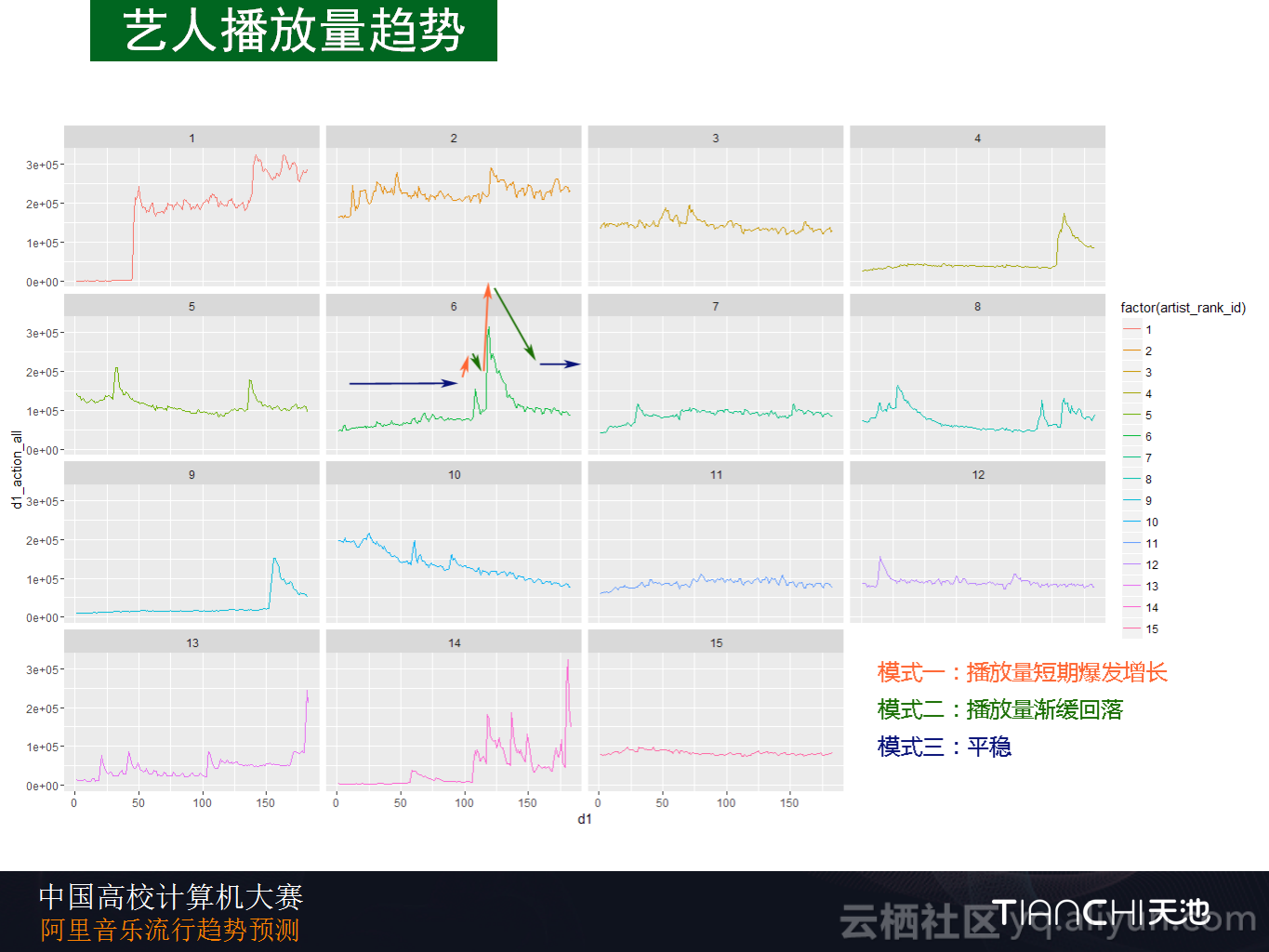
下图是挑选出的15个艺人的播放量趋势,从图中可以非常明显地看出艺人的播放量趋势存在三种状态:快速上升、指数镜像型下降以及保持平稳。
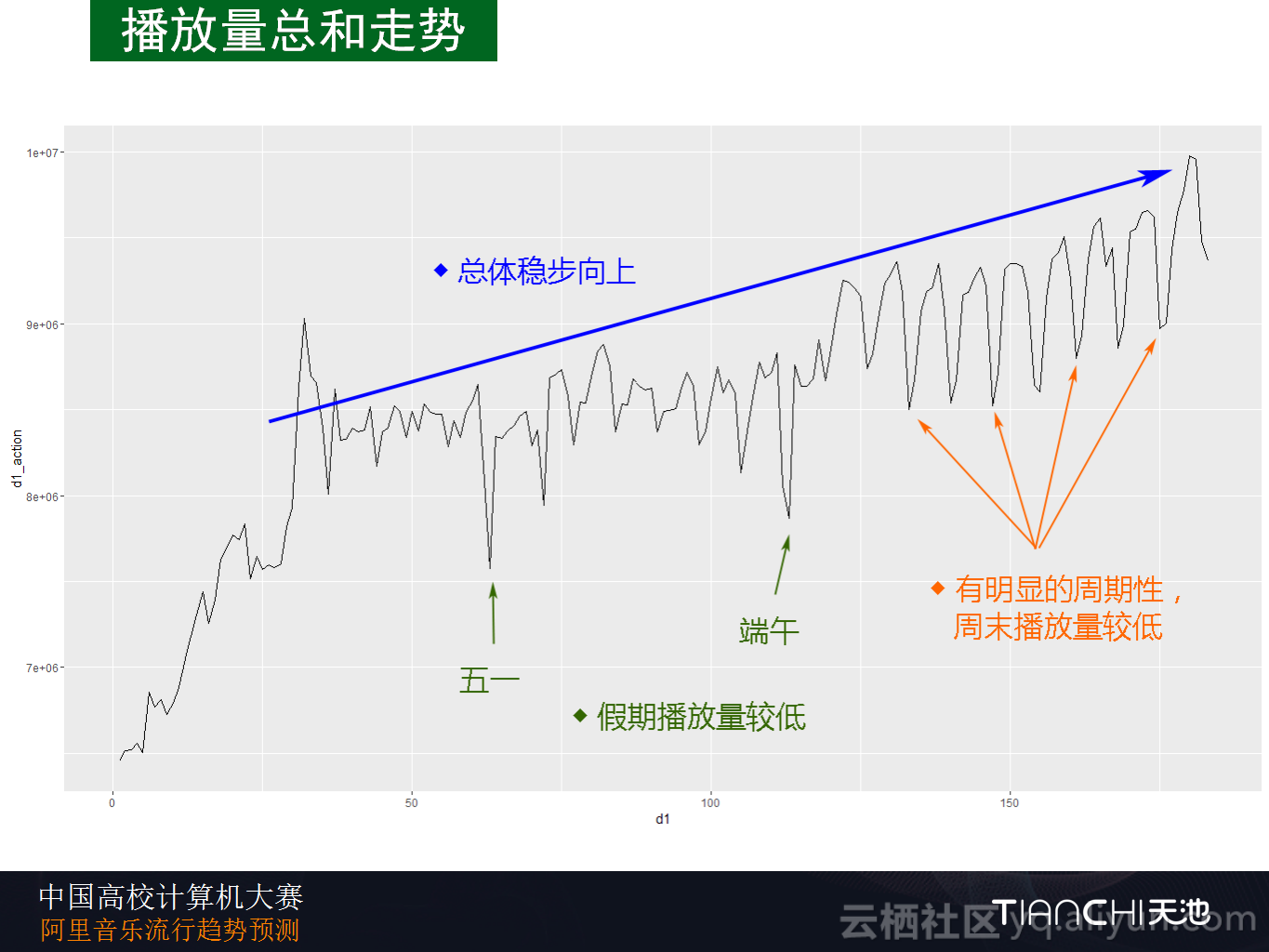
下图是播放量综合的走势情况。对于总体播放量而言,也存在三个整体特征:第一个特征就是总体稳步上升,这其实也表现了用户数的稳步上升;另外一个特征就是在“五一”和端午节两个假期的播放量明显低于日常播放量,从后面也可以看到用户数目足够多以后表现出了明显的周期性,这个周期性表现为周末的播放量会降低,工作日就会变多,反映出来就是音乐的播放量在大家的碎片时间比较多,相比而言,在工作日时间大家的碎片化时间会多一些。
Datahacker团队强调了对于基本概念的理解和把握需要非常清晰,因为对于预测问题时往往会做很多的近似,而在近似的过程中,如果不能很系统地把握里面的输入和输出以及自变量、因变量,这样的话最后往往会造成混淆甚至会走很多弯路。所以需要对于每一个函数以及每一个公式都清晰地了解其输入以及输出是什么,自变量和因变量又是什么。
首先对于播放量而言,其实播放量实际上是网络传播动力学的问题,这方面近期比较热门,但是目前没有一个强有力的结果。从赛题的角度而言,Datahacker团队则是通过星期和假期这些可以利用的历史数据来进行预测的,但是这其中也会存在着一些扰动项。

对于测试集的考虑而言,基本不会使用给出的整个六个月的数据来预测后面两个月,一般情况是使用后面三四个月甚至两个月的数据进行预测。Datahacker团队列举的例子中使用了四个月的历史数据进行预测,这样就可以顺利地完成比赛。但是使用历史数据预测七月和八月或者九月和十月,这两个函数f3和f4是不相同的,因为这其中的扰动是关于时间T的函数,但是为了预测,所以近似地令f3=f4,来得到平均预测值。再进一步,加上星号表示某一特定数,因为比赛中会经常出现更换数据的问题,所以f5/f4就是一个特例,它实际上牵扯到这组数据特有的几个艺人的特殊数据。最后实际上需要求的就是将f3使用历史数据回归出来,将f6抽出来,并且为了避免过拟合的问题需要让f6=f4-f3而不是f5-f3,并不是特定数据的差,否则就会出现过拟合的问题了。这个思路看上去比较简单,然而在实际操作时f3和f4的变量很多,所以在实现时需要推导很多模型,并且需要进行模型融合,所以有时混淆是很容易发生的。
那么经过上面的分析,就转化到求解f3和f6两个函数的问题了。这里求解f3其实就是一个回归问题,划分就是两大类:专家系统和机器学习。专家系统简称为规则,就是人为地构造一个非线性函数,并利用数据集求取参数;而机器学习则是利用机器学习方法获得回归函数。而f6的求解在整个比赛中也是比较重要的,因为数据挖掘其实就是获取信息,在比赛中除了给出数据信息之外,测评的分数也会包含很多的信息,如果从测评的分数中有技巧地构建答案进行提交的话,实际上也是可以获取非常多的信息的,对于成绩而言也会有非常大的提升。

对于f6而言,存在很多的扰动。第一个扰动因素就是长假,可以看出给出的数据里面是没有长假数据的,在这一点可以定性地判断出长假期间播放量会比较低,但是具体会低多少,以及在七天长假中以什么样的形式降低,这些都是无法从数据集中获取信息的,如果想要提高这部分的分数就需要从测评信息中获取。第二点,可以看出前面的播放量是稳步上升的,但是无法保证九月和十月份还是会稳步上升,也有可能走向下降的趋势。所以这些外部扰动所带来的影响都是无法通过历史数据获取的,需要在测评中通过一些假设进行获取求证,Datahacker团队还提到包括他们融合模型的参数就是通过测评不断改善的。
其实比赛最关键的问题就是模式一——播放量的爆发增长是否可以预测?这一点通过历史数据是无法进行精确预测的。另外对于数据而言,去进行信息沙漏分析,将数据逐个去试也能够很快地得到这个结论,播放量的爆发增长是不能进行预测的,这个问题也是外部扰动的一项,而且外部扰动会非常强,有时候会有几十倍的增加。
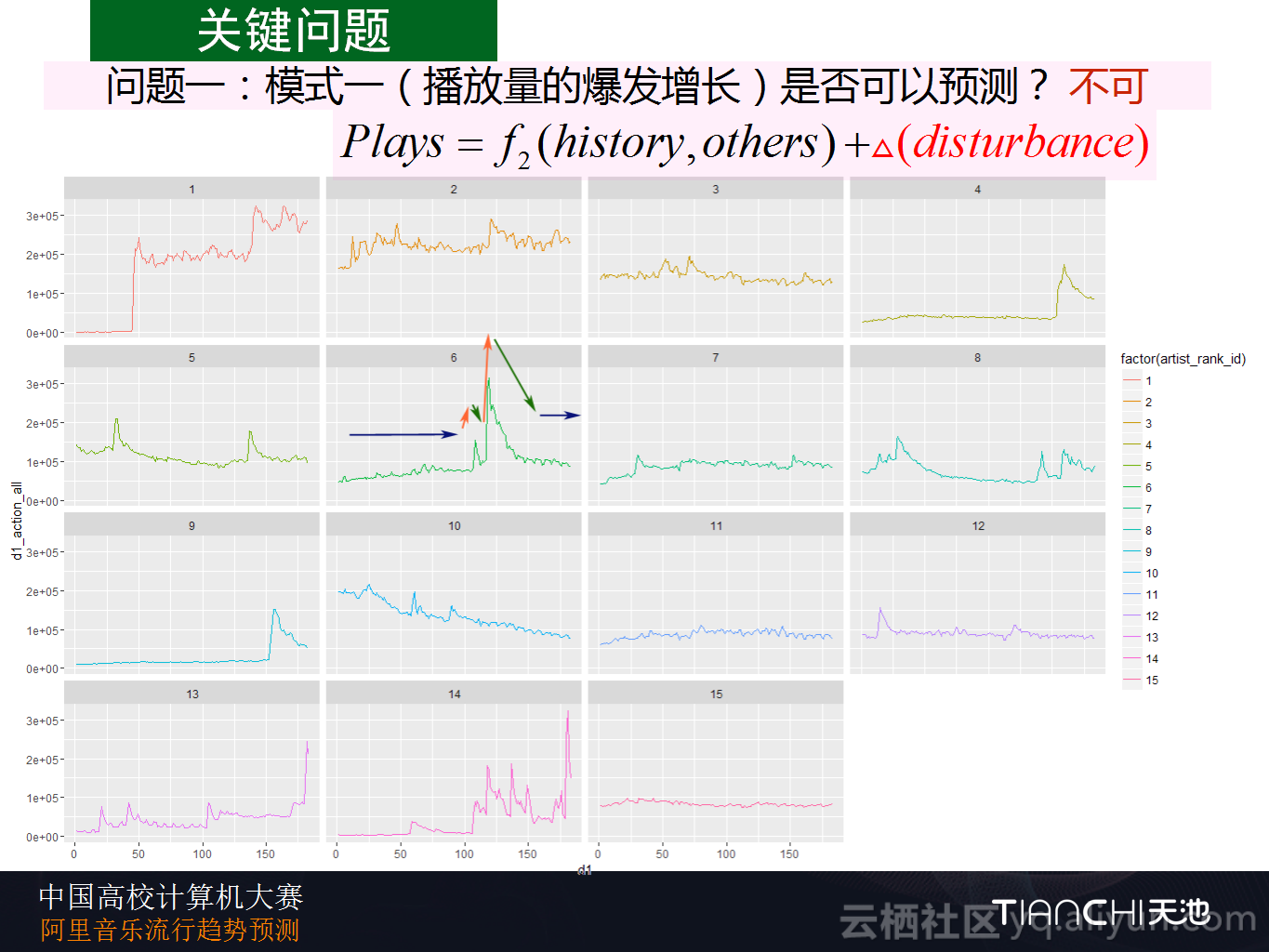
第二个问题就是题目所给出的数据集中其他的信息是否有用?Datahacker团队进行了如下分析:
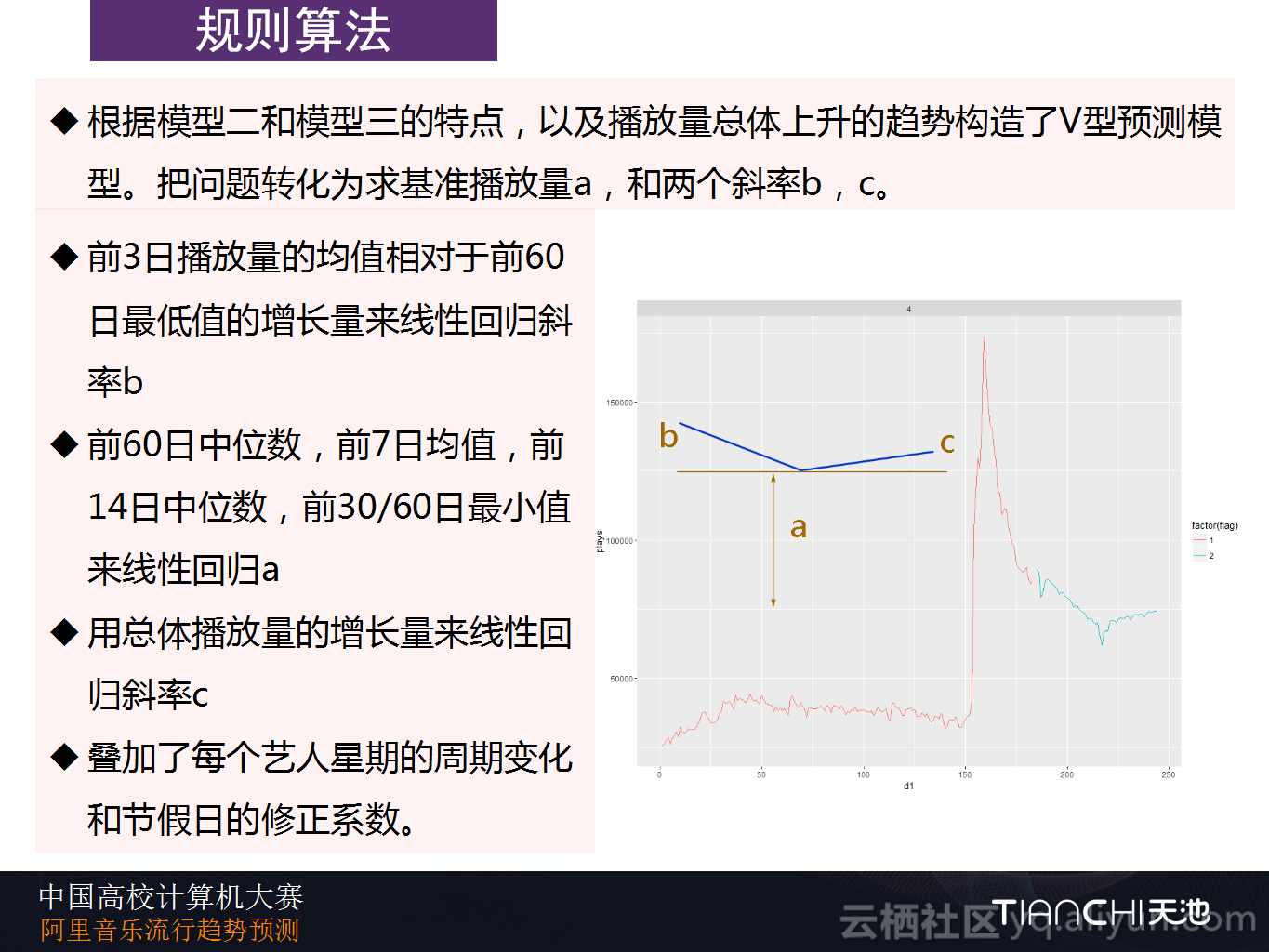
因为总体播放量在上升并且总用户数也在上升,所以会呈现V型。这样就把问题转化为求基准播放量a和两个斜率b,c。Datahacker团队使用了一些历史数据进行线性回归,第一个就是前三日播放量的均值,第二个是相对于前60日的增长量,后面又选取了中位数以及最小数等特征值。谈到为什么要选取这些值,Datahacker团队表示想法很简单,将数据的特征数值全部列举出来,进行线性回归,之后每次剔除掉一个影响量最小的值,在剔除几次以后就会找到最合适的三、四个特征值,这时候就会发现测评成绩已经非常稳定了,不会再上升了,这时候就可以用于预测了。
Datahacker团队使用了总体播放量的增长量来线性回归斜率c,与其他团队有所不同就是他们叠加了每个艺人星期的周期变化和节假日的修正系数。下图中右侧部分就是Datahacker团队给出的例子,其中红色的线就是数据集给出历史数据,蓝色是他们的预测,从例子中看上去还是很不错的。Datahacker团队在这其中发现一个很有意思的地方:通过给出的数据目测后面的数据其实是很难的,但是将自己的预测结果图画出来,通过目测进行判断其实与线上评测的结果是高度接近的,也就是使用目测法可以很容地判断出预测的结果准确与否。
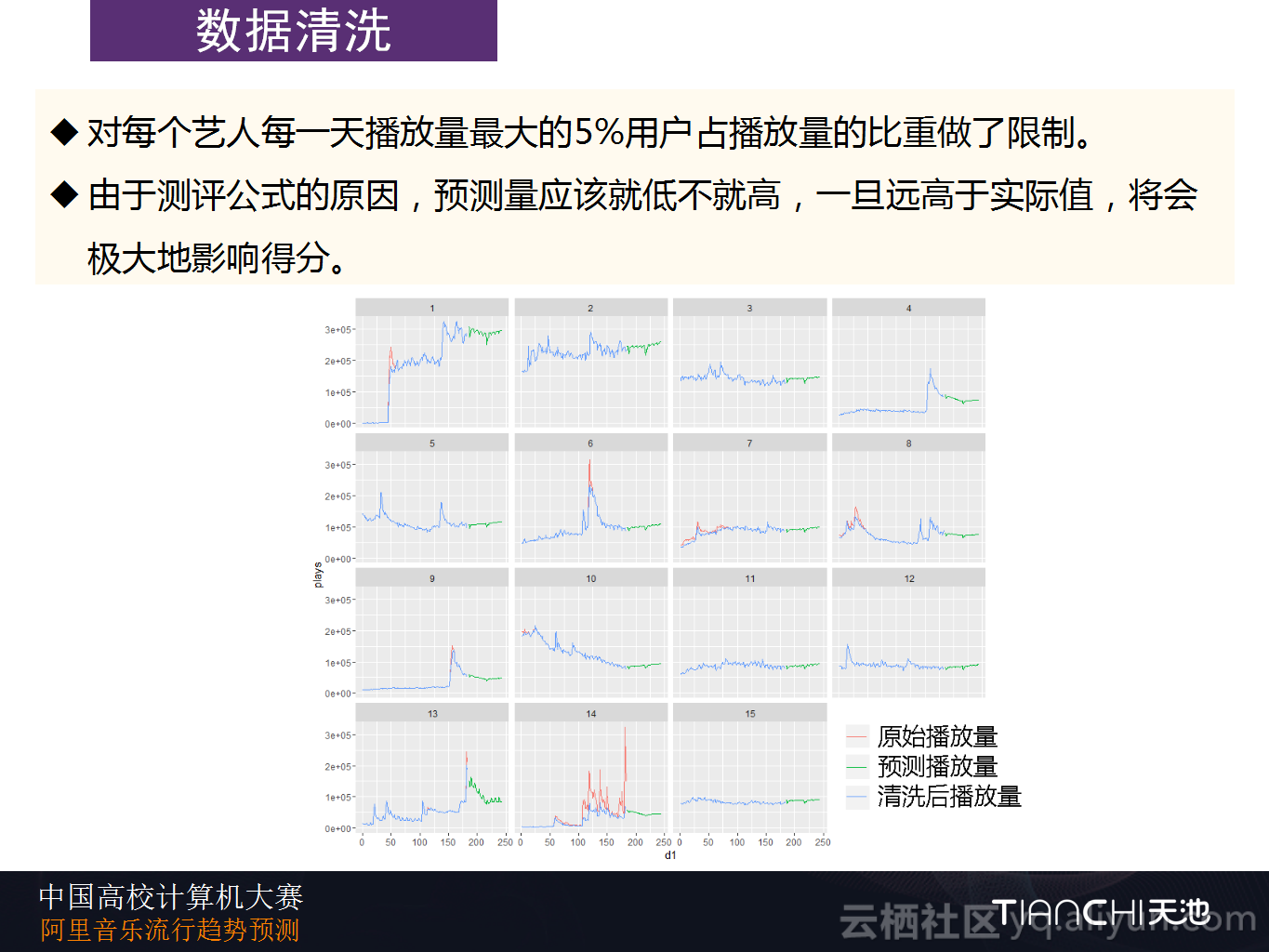
对于数据清洗方面,Datahacker团队对每个艺人每一天播放量最大的5%用户占播放量的比重做了限制。并且由于测评公式的原因,预测量应该就低不就高,一旦远高于实际值,将会极大地影响得分。
二、规则算法
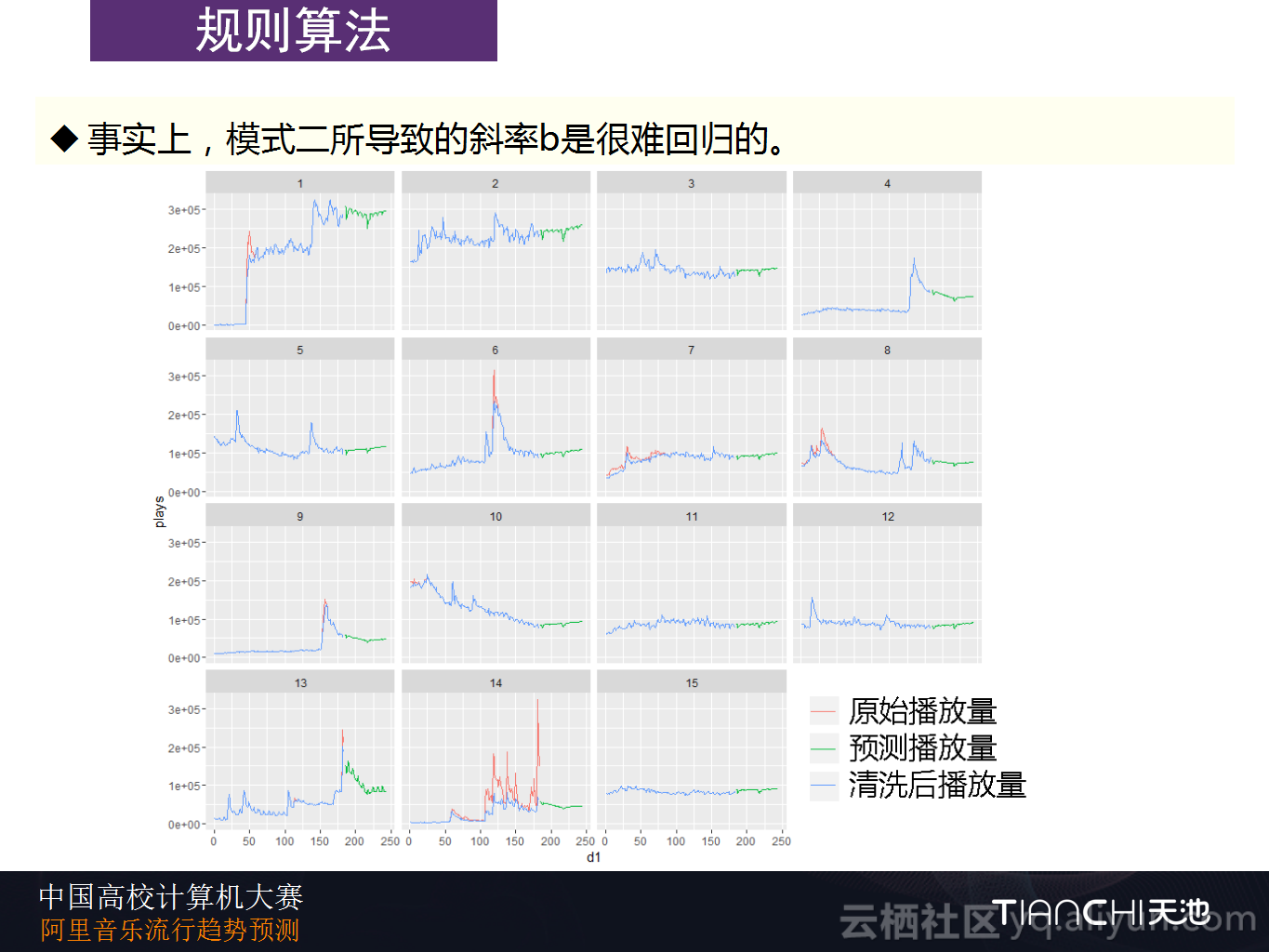
前面看到的方式看上去很简单,就是用线性回归计算出系数就可以,但是实际上将所有的用户数据全部放进去以后一起进行预测,效果就不会特别好了。特别是因为前面谈到的斜率对于八月份的异常增长用户的预测,但是后面数据会下降,所以将所有的用户都放进去时实际的效果会比较差。因此,实际上对于八月份的异常需要进行分类预判,然而对于回落的预判是非常难的,因为异常增长的高度、幅度以及时间发生点都是不可预测的,所以也是无法刻画的。Datahacker团队在这里使用替代的方法进行分类,就是使用后30天播放量的均值/前7天播放量的均值来替代模式二的指代性特征,并使用了不同的阈值设计了分类器。
在论述这部分时,Datahacker团队还谈到了一个不确定的经验:对于百万级别数据量的训练集,组合特征在数百维的量级上,这样其实对分类性能是有益无害的。所以抱着这样的一个认识,Datahacker认为可以放心的堆特征,因此只使用了两类数据:播放量和播放人数,但是最后堆出来的特征维度达到了200多个维度,然后将b1按照不同的阈值进行分成四个组,得到八个类别,并且最后得到了四组预测数据。
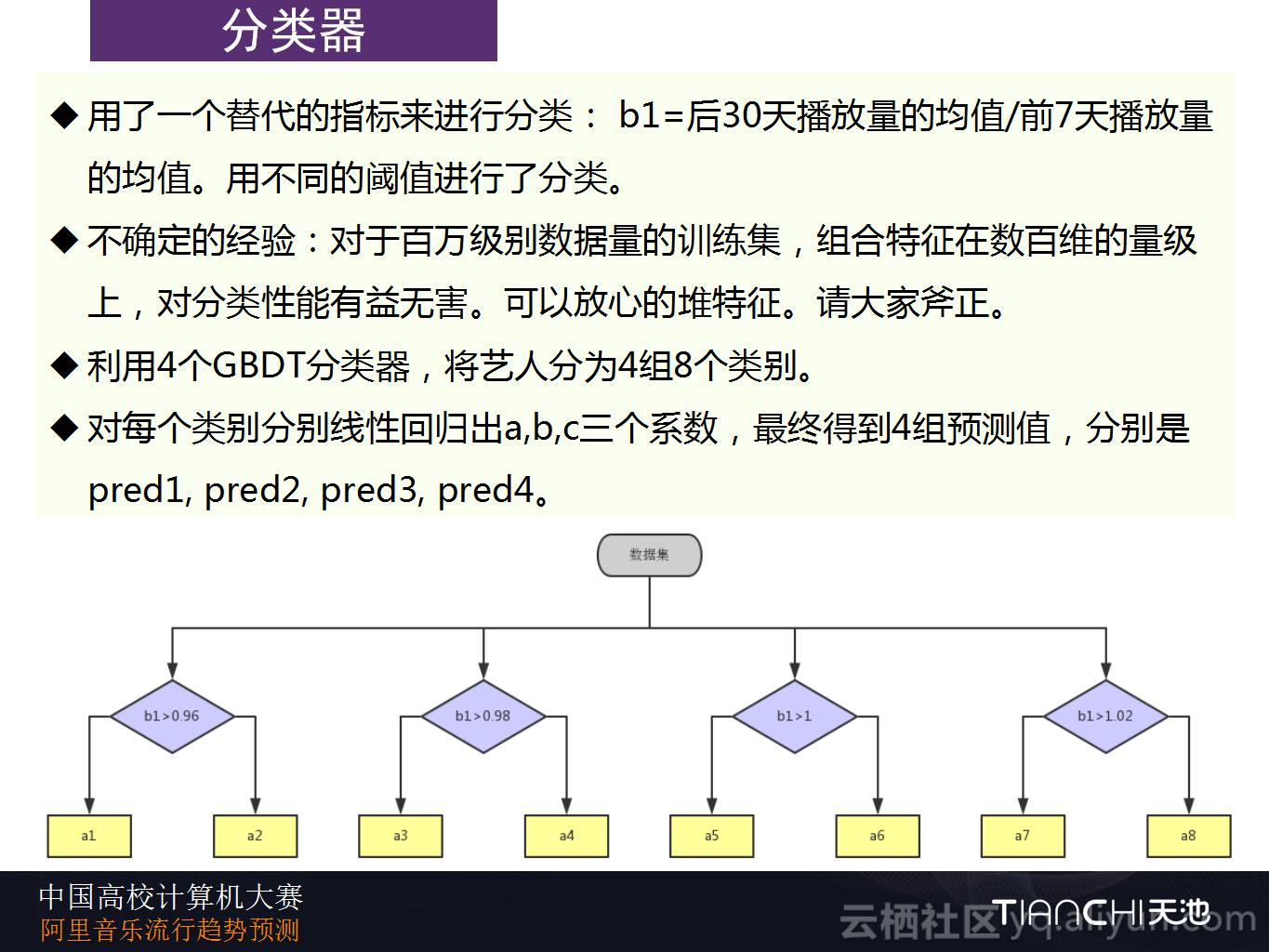
接下来就已经将模型构建完成了。实际上,对于不同阈值的分类器的模型准确度是可以线下计算出来的,计算出来的准确度高的权值就大,准确度低的权值就比较低,最后保证权值和最后等于1就可以了。

Datahacker团队模型的最终得分是505151,这个分数领先其他团队非常多,特别是在整个线上测试中,他们一直处于领先地位,而在更换数据集之后,数据量大了,Datahacker团队领先的幅度就更大了。Datahacker团队谈到他们的模型有以下的优点:
接下来,Datahacker团队简单地介绍了他们的模型算法。第一点,由于没有周期性数据,其实模型算法的构建比较困难。需要预测60天这样一个比较长的时间,使用模型算法的滑窗法的话就会遇到困难,要么就需要设计出60个模型,每个模型的时间间隔不同;要么就设计时间间隔相同的模型,再将预测出来的数据作为训练集带入到后面的训练中,这样误差就会累积,导致结果非常差。所以Datahacker团队并没有在模型算法上面花费太多的时间,因为他们通过之前的观察认为V型模型是更适合的。
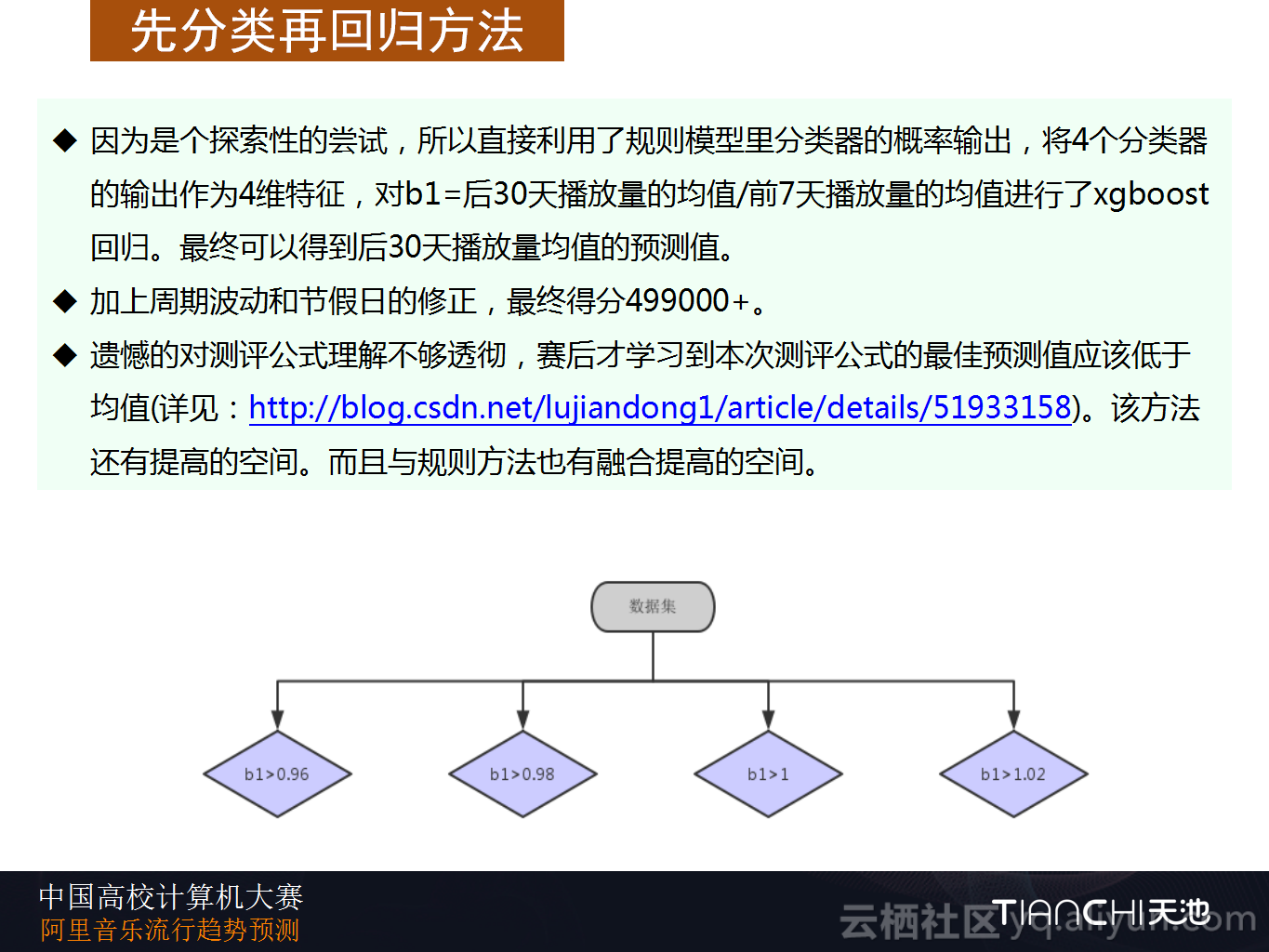
第二点,机器学习的回归方法对训练集的数据量要求很高。如果使用归回方法的话,百万级别的训练集都无法支持数百维特征进行训练,维度的要求就会非常低,这样对于特征选择就会有影响。特征数量的限制导致无法充分利用信息,进而影响了回归模型的精度。在菜鸟-需求预测与分仓规划比赛中,他们也使用了先分类再回归的类似stacking的方法,取得了较好的成绩,这次也用这种方法进行了模型回归的尝试。
因为是个探索性的尝试,所以Datahacker团队直接利用了规则模型里分类器的概率输出,将4个分类器的输出作为4维特征,对b1=后30天播放量的均值/前7天播放量的均值进行了xgboost回归,最终可以得到后30天播放量均值的预测值。加上周期波动和节假日的修正,最终得分499000+。Datahacker团队谈到比较遗憾的是对测评公式理解不够透彻,赛后才学习到本次测评公式的最佳预测值应该低于均值。如果将最优值带入的话,该方法还有提高的空间,而且与规则方法也有融合提高的空间。
接下来,Datahacker团队谈了一下对于天池比赛的感想。Datahacker团队的成员基本都是经验丰富的天池的老选手了,可以说见证了天池的成长,虽然时不时的都会编个段子黑天池,但这只是段子手们笨拙的表达自己的喜爱之情的一种方式。毫无疑问,天池在大数据领域的影响力是有目共睹的。
Datahacker团队谈到天池的算法平台是个非常令人激动的产品,遗憾的是功能还不完善:算法数量不够,特别是时序分析算法,更是完全没有。数据探索时最重的数据可视化方面更是有待完善,时间序列预测问题不能画曲线图实在有点说不过去。在最后Datahacker团队谈到了共享机制,希望天池在未来能提供更好的代码/代码片段的共享机制,以及最重要的评论机制,毕竟无吐槽不社交。
四、重要的事情
1.始终保持概念清晰,对于任一模型、函数或者系统,都要非常准确的把握自变量和因变量,输入和输出分别是什么。
2.数据挖掘的本质是获取信息,对于时间序列预测型竞赛来说,信息的来源有两个:数据集和测评系统得分。
3.单一模型往往不能取得很好的成绩,推荐实现结构简单,但是实现上有一定复杂性的融合模型,融合模型总会具有更高的精度和更强的鲁棒性。
4.数据清洗非常重要,大数据往往代表的是大量有问题的数据。
最后,分享给大家Norbert Wiener的一句话:要想改善对象的特性,必须从对象上获取信息,并将这种信息反作用于对象上,这种作用就叫做控制。
本文整理自获得本次2016中国高校计算机大赛阿里音乐流行趋势预测比赛冠军的Datahacker团队的答辩视频。Datahacker团队由三名成员组成,成员简介如下:
一、赛题分析
二、规则算法
三、模型算法
四、重要的事情
一、赛题分析
本次大数据挑战赛以阿里音乐用户的历史播放数据为基础,期望参赛者可以通过对阿里音乐平台上每个阶段艺人的试听量的预测,挖掘出即将成为潮流的艺人,从而实现对一个时间段内音乐流行趋势的准确把控。从下图中给出的测评公式,可以看出真实的播放量是在分母上边的,所以如果真实的播放量比较小的话,那么将会误差将会非常大,甚至在测试里面则会出现负分。基于这样的认识,在相同的可能情况下,Datahacker团队预测的播放量要偏小一些,所以测评的得分会大于偏大的情况。
首先对于播放量而言,其实播放量实际上是网络传播动力学的问题,这方面近期比较热门,但是目前没有一个强有力的结果。从赛题的角度而言,Datahacker团队则是通过星期和假期这些可以利用的历史数据来进行预测的,但是这其中也会存在着一些扰动项。
那么经过上面的分析,就转化到求解f3和f6两个函数的问题了。这里求解f3其实就是一个回归问题,划分就是两大类:专家系统和机器学习。专家系统简称为规则,就是人为地构造一个非线性函数,并利用数据集求取参数;而机器学习则是利用机器学习方法获得回归函数。而f6的求解在整个比赛中也是比较重要的,因为数据挖掘其实就是获取信息,在比赛中除了给出数据信息之外,测评的分数也会包含很多的信息,如果从测评的分数中有技巧地构建答案进行提交的话,实际上也是可以获取非常多的信息的,对于成绩而言也会有非常大的提升。
其实比赛最关键的问题就是模式一——播放量的爆发增长是否可以预测?这一点通过历史数据是无法进行精确预测的。另外对于数据而言,去进行信息沙漏分析,将数据逐个去试也能够很快地得到这个结论,播放量的爆发增长是不能进行预测的,这个问题也是外部扰动的一项,而且外部扰动会非常强,有时候会有几十倍的增加。
- 大量的关于用户行为的数据,对本赛题无用。求解宏观问题用宏观方法,求解微观问题用微观方法。
- 下载数据和收藏数据,可能存在有用的信息。但是在模式一这种强扰动要素无法预测的背景下,这种次要信息的意义不大,而且提取也较困难。
- 因此使用的数据只有艺人播放量和播放人数的历史值及历史统计量。
Datahacker团队使用了总体播放量的增长量来线性回归斜率c,与其他团队有所不同就是他们叠加了每个艺人星期的周期变化和节假日的修正系数。下图中右侧部分就是Datahacker团队给出的例子,其中红色的线就是数据集给出历史数据,蓝色是他们的预测,从例子中看上去还是很不错的。Datahacker团队在这其中发现一个很有意思的地方:通过给出的数据目测后面的数据其实是很难的,但是将自己的预测结果图画出来,通过目测进行判断其实与线上评测的结果是高度接近的,也就是使用目测法可以很容地判断出预测的结果准确与否。
对于数据清洗方面,Datahacker团队对每个艺人每一天播放量最大的5%用户占播放量的比重做了限制。并且由于测评公式的原因,预测量应该就低不就高,一旦远高于实际值,将会极大地影响得分。
二、规则算法
前面看到的方式看上去很简单,就是用线性回归计算出系数就可以,但是实际上将所有的用户数据全部放进去以后一起进行预测,效果就不会特别好了。特别是因为前面谈到的斜率对于八月份的异常增长用户的预测,但是后面数据会下降,所以将所有的用户都放进去时实际的效果会比较差。因此,实际上对于八月份的异常需要进行分类预判,然而对于回落的预判是非常难的,因为异常增长的高度、幅度以及时间发生点都是不可预测的,所以也是无法刻画的。Datahacker团队在这里使用替代的方法进行分类,就是使用后30天播放量的均值/前7天播放量的均值来替代模式二的指代性特征,并使用了不同的阈值设计了分类器。
- 使用了四个模型,满足机器学习的“好而不同”的特点。
- 其实机器学习不一定对于性能有很高的影响,但是对于鲁棒性的提升却是会非常明显的。加上模型融合以后,模型对更换数据集不敏感,对于任意足够大,且总体参数稳定的数据集,都可以稳定的得到领先的分数。
- 模型对自身参数也不敏感,可以保证参数在一定范围内的变化,得分保持在一个很高的水平上。对于GBDT的分类器而言,一般情况下不会调整参数,直接使用默认参数就可以。
接下来,Datahacker团队简单地介绍了他们的模型算法。第一点,由于没有周期性数据,其实模型算法的构建比较困难。需要预测60天这样一个比较长的时间,使用模型算法的滑窗法的话就会遇到困难,要么就需要设计出60个模型,每个模型的时间间隔不同;要么就设计时间间隔相同的模型,再将预测出来的数据作为训练集带入到后面的训练中,这样误差就会累积,导致结果非常差。所以Datahacker团队并没有在模型算法上面花费太多的时间,因为他们通过之前的观察认为V型模型是更适合的。
第二点,机器学习的回归方法对训练集的数据量要求很高。如果使用归回方法的话,百万级别的训练集都无法支持数百维特征进行训练,维度的要求就会非常低,这样对于特征选择就会有影响。特征数量的限制导致无法充分利用信息,进而影响了回归模型的精度。在菜鸟-需求预测与分仓规划比赛中,他们也使用了先分类再回归的类似stacking的方法,取得了较好的成绩,这次也用这种方法进行了模型回归的尝试。
因为是个探索性的尝试,所以Datahacker团队直接利用了规则模型里分类器的概率输出,将4个分类器的输出作为4维特征,对b1=后30天播放量的均值/前7天播放量的均值进行了xgboost回归,最终可以得到后30天播放量均值的预测值。加上周期波动和节假日的修正,最终得分499000+。Datahacker团队谈到比较遗憾的是对测评公式理解不够透彻,赛后才学习到本次测评公式的最佳预测值应该低于均值。如果将最优值带入的话,该方法还有提高的空间,而且与规则方法也有融合提高的空间。
Datahacker团队谈到天池的算法平台是个非常令人激动的产品,遗憾的是功能还不完善:算法数量不够,特别是时序分析算法,更是完全没有。数据探索时最重的数据可视化方面更是有待完善,时间序列预测问题不能画曲线图实在有点说不过去。在最后Datahacker团队谈到了共享机制,希望天池在未来能提供更好的代码/代码片段的共享机制,以及最重要的评论机制,毕竟无吐槽不社交。
四、重要的事情
1.始终保持概念清晰,对于任一模型、函数或者系统,都要非常准确的把握自变量和因变量,输入和输出分别是什么。
2.数据挖掘的本质是获取信息,对于时间序列预测型竞赛来说,信息的来源有两个:数据集和测评系统得分。
3.单一模型往往不能取得很好的成绩,推荐实现结构简单,但是实现上有一定复杂性的融合模型,融合模型总会具有更高的精度和更强的鲁棒性。
4.数据清洗非常重要,大数据往往代表的是大量有问题的数据。
最后,分享给大家Norbert Wiener的一句话:要想改善对象的特性,必须从对象上获取信息,并将这种信息反作用于对象上,这种作用就叫做控制。