摘要
上文(存储篇)说到数据库重要的两部分为存储和计算,本篇内容为你解读图数据库 Nebula 在查询引擎 Query Engine 方面的设计实践。
在 Nebula 中,Query Engine 是用来处理 Nebula 查询语言语句(nGQL)。本篇文章将带你了解 Nebula Query Engine 的架构。

上图为查询引擎的架构图,如果你对 SQL 的执行引擎比较熟悉,那么对上图一定不会陌生。Nebula 的 Query Engine 架构图和现代 SQL 的执行引擎类似,只是在查询语言解析器和具体的执行计划有所区别。
Session Manager
Nebula 权限管理采用基于角色的权限控制(Role Based Access Control)。客户端第一次连接到 Query Engine 时需作认证,当认证成功之后 Query Engine 会创建一个新 session,并将该 session ID 返回给客户端。所有的 session 统一由 Session Manger 管理。session 会记录当前 graph space 信息及对该 space 的权限。此外,session 还会记录一些会话相关的配置信息,并临时保存同一 session 内的跨多个请求的一些信息。
客户端连接结束之后 session 会关闭,或者如果长时间没通信会切为空闲状态。这个空闲时长是可以配置的。
客户端的每个请求都必须带上此 session ID,否则 Query Engine 会拒绝此请求。
Storage Engine 不管理 session,Query Engine 在访问存储引擎时,会带上 session 信息。
Parser

Query Engine 解析来自客户端的 nGQL 语句,分析器(parser)主要基于著名的 flex / bison 工具集。字典文件(lexicon)和语法规则(grammar)在 Nebula 源代码的 src/parser 目录下。设计上,nGQL 的语法非常接近 SQL,目的是降低学习成本。 图数据库目前没有统一的查询语言国际标准,一旦 ISO/IEC 的图查询语言(GQL)委员会发布 GQL 国际标准,nGQL 会尽快去实现兼容。
Parser 构建产出的抽象语法树(Abstrac Syntax Tree,简称 AST)会交给下一模块:Execution Planner。
Execution Planner
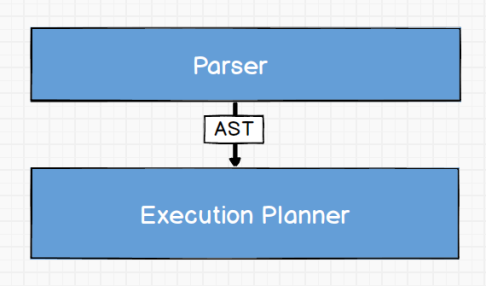
执行计划器(Execution Planner)负责将抽象树 AST 解析成一系列执行动作 action(可执行计划)。action 为最小可执行单元。例如,典型的 action 可以是获取某个节点的所有邻节点,或者获得某条边的属性,或基于特定过滤条件筛选节点或边。当抽象树 AST 被转换成执行计划时,所有 ID 信息会被抽取出来以便执行计划的复用。这些 ID 信息会放置在当前请求 context 中,context 也会保存变量和中间结果。
Optimization

经由 Execution Planner 产生的执行计划会交给执行优化框架 Optimization,优化框架中注册有多个 Optimizer。Optimizer 会依次被调用对执行计划进行优化,这样每个 Optimizer都有机会修改(优化)执行计划。最后,优化过的执行计划可能和原始执行计划完全不一样,但是优化后的执行结果必须和原始执行计划的结果一样的。
Execution
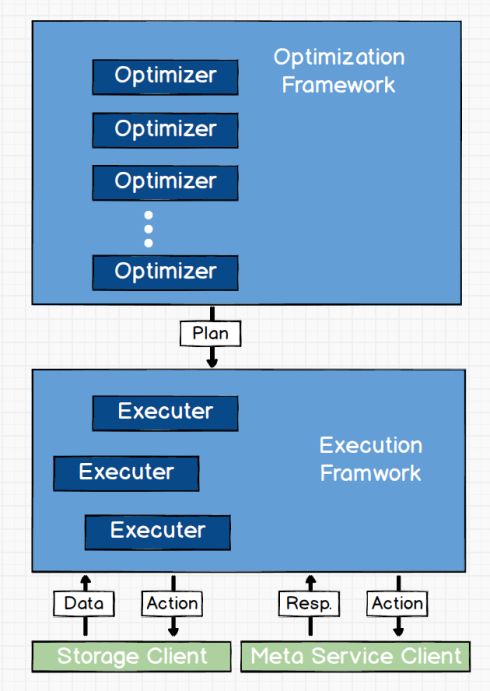
Query Engine 最后一步是去执行优化后的执行计划,这步是执行框架(Execution Framework)完成的。执行层的每个执行器一次只处理一个执行计划,计划中的 action 会挨个一一执行。执行器也会一些有针对性的局部优化,比如:决定是否并发执行。针对不同的 action所需数据和信息,执行器需要经由 meta service 与storage engine的客户端与他们通信。
最后,如果你想尝试编译一下 Nebula 源代码可参考如下方式:

有问题请在 GitHub(GitHub 地址:https://github.com/vesoft-inc/nebula) 或者微信公众号上留言,也可以添加 Nebula 小助手微信号:NebulaGraphbot 为好友反馈问题~

