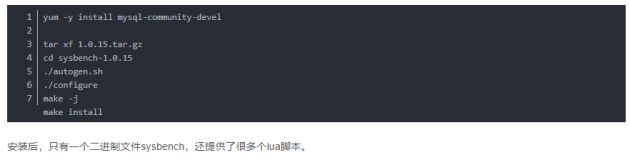
作为一家金融科技企业,宜信的大量业务都依赖于数据库。如何提高公司整体数据库应用水平,是对DBA的一大挑战,也非常具有现实意义。笔者在宜信的多年工作中,与团队一起总结整理了针对传统关系型数据库的使用规则,并借助自研的数据库审核平台落地,借此帮助研发团队评估数据库开发质量,达到尽早发现问题、解决问题之目的。下图正是这一系统的简单原理图。

如上图所示,针对规则部分又可细分为如下分类(部分)。简单描述如下,后面将逐一详细说明。

一、Oracle规则(对象)
1.1 表、分区
【规则1】
规则说明:超过指定规模且没有分区的表。
规则阈值:2GB(物理大小超过指定阀值)。
规则描述:表的规模过大,将影响表的访问效率、增加维护成本等。常见的解决方案就是使用分区表,将大表转换为分区表。
【规则2】
规则说明:单表或单分区记录数量过大。
规则阈值:1000000(单表或单分区记录数超过指定阀值)。
规则描述:控制单个表或单个分区的数据规模,提高单一对象的访问效率。如记录数过多,应考虑分库、分表、分区等策略。
【规则3】
规则说明:大表过多。
规则阈值:自定义(超过2G的表的数量过多)。
规则描述:大表在所有表中所占比例超过20%(OLTP)或95%(OLAP)。
【规则4】
规则说明:单表分区数量过多。
规则阈值:500(单表分区数量超过指定阀值)。
规则描述:分区表中分区数量过多,将导致整体维护成本过高,可调整分区粒度。
【规则5】
规则说明:分区表数量过多。
规则阈值:2000(分区表数量超过指定阀值)。
规则描述:分区表过多,常见原因是大表较多。因根据需求,考虑进行垂直拆分,减小单库规模。
【规则6】
规则说明:复合分区数量过多。
规则阈值:5(复合分区数量超过指定阀值)。
规则描述:同上面分区表数量过多理由类似(含有复合分区表的数量)。
【规则7】
规则说明:存在启用并行属性的表。
规则阈值:1(表degree属性不为1)。
规则描述:一般情况下不建议对表设置并行属性。
1.2 索引
【规则8】
规则说明:外键没有索引的表。
规则描述:外键没有索引会导致主子表关联查询时,关联效率很低。
【规则9】
规则说明:组合索引数量过多或没有索引。
规则描述:组合索引过多,将导致空间消耗较大、索引维护成本较高。应考虑构建战略性索引结构,不要针对每个需求都通过创建索引解决。
【规则10】
规则说明:单表索引数量过多。
规则阈值:3(单表索引数量超过指定阀值)。
规则描述:索引可以提高访问速度,但数量过多将导致空间消耗过大,且索引维护成本较高,影响DML效率等问题。应控制索引数量。
【规则11】
规则说明:存在7天内没有使用的索引。
规则描述:在数据库一段时间内,该索引没有被任何SQL语句使用。请评估此索引的有效性。
【规则12】
规则说明:字段重复索引。
规则描述:一个字段被多个索引引用,请考虑构建策略,删除不必要的索引。
【规则13】
规则说明:存在全局分区索引。
规则描述:全局分区索引,存在维护成本较高问题。当分区发生变化时,需要维护全局索引的有效性。
【规则14】
规则说明:失效索引。
规则描述:索引状态为INVALID、UNUSABLE。
【规则15】
规则说明:索引高度超过指定高度。
规则阈值:4。
规则描述:索引高度过高导致增加IO成本。
【规则16】
规则说明:存在位图索引。
规则描述:OLTP环境中不建议使用位图索引,如果表对象经查做DML操作,会在一定程度上阻塞相关操作。
【规则17】
规则说明:存在函数索引。
【规则18】
规则说明:存在启用并行属性的索引。
规则阈值:1(索引degree属性不为1)。
规则描述:一般情况下不建议对索引设置并行属性。
【规则19】
规则说明:存在聚簇因子过大的索引。
规则阈值:自定义。
规则描述:聚簇因子过大的索引,应该考虑优化。
1.3 约束
【规则20】
规则类别:约束。
规则说明:没有主键的表。
规则描述:主键是关系型数据库中唯一确定一条记录的依据,没有任何理由不定义主键。
【规则21】
规则类别:约束。
规则说明:使用外键的表。
规则描述:不建议使用外键约束,数据一致性通过应用端解决。
1.4 字段
【规则22】
规则说明:表字段过多。
规则阈值:100(字段数量超过指定阀值)。
规则描述:字段过多,会导致记录长度过大。单个数据存储单元将保存的记录数过少,影响访问效率。
【规则23】
规则说明:包含有大字段类型的表。
规则描述:大对象字段是关系型数据库中应尽量避免的。如有需要,可考虑在外部进行存储。
【规则24】
规则说明:记录长度定义过长。
规则描述:记录定义长度与实际存储长度差异过大,请考虑字段类型定义是否合理,个别字段过长是否可分表存储。
【规则25】
规则说明:不包含时间戳字段的表。
规则描述:时间戳,是获取增量数据的一种方法。建议在表内增加创建时间、更新时间的时间戳字段。命名方式为CREATE_TIME、UPDATE_TIME。
【规则26】
规则说明:表字段类型不匹配。
规则描述:此规则会抽样部分数据,分析其定义类型与存储类型是否相符。常见问题如用数字、文本保存日期等。
1.5 其他对象
【规则27】
规则说明:缓存过小的序列。
规则阈值:100(序列cache值小于指定阀值)。
规则描述:系统默认会缓存20,如过小将导致频繁查询数据字典,影响并发能力。
【规则28】
规则说明:存在存储过程及函数度。
规则阈值:20(存储过程和函数的数量超过指定阀值)。
规则描述:存储过程及函数,将影响数据库的异构迁移能力,并存在代码维护性较差等原因。
【规则29】
规则说明:存在触发器。
规则阈值:20(触发器数量超过指定阀值)。
规则描述:触发器,将影响数据库的异构迁移能力。如有数据一致性维护需求,请从应用端给予考虑。
【规则30】
规则说明:存在DBLINK。
规则描述:不建议在一个数据库中访问其他数据库,请考虑在应用端解决。
二、Oracle规则(执行计划)
2.1 绑定变量
【规则31】
规则说明:未使用绑定变量。
规则阈值:自定义(执行次数)。
规则描述:执行次数超过一定阀值的语句,谓词右侧存在常量值。
【规则32】
规则说明:绑定变量的数量过多。
规则阈值:自定义(绑定变量的个数)。
规则描述:绑定变量数量过多会增加变量替换时间,在一定程度上增加sql执行时间。
2.2 表间关联
【规则33】
规则说明:笛卡尔积。
规则描述:缺少连接条件,导致表间关联使用了笛卡尔积的连接方式,执行计划中包含"CARTESIAN|"字样。
【规则34】
规则说明:嵌套循环层次过深。
规则阈值:自定义(层次数)。
规则描述:嵌套循环层次过深,超过指定阀值。执行计划中嵌套多层"NESTED LOOP"或"FILTER"字样。
【规则35】
规则说明:嵌套循环内层表访问方式为全表扫描。
规则描述:嵌套循环的内层表访问方式为全表扫描,效率很低。
【规则36】
规则说明:排序合并连接中存在大结果集排序。
规则描述:排序合并中两个结果集都要排序,应调整为其他连接方式。
【规则37】
规则说明:多表关联。
规则阈值:自定义(表个数)。
规则描述:过多的表关联,影响性能。
2.3 访问路径
【规则38】
规则说明:大表全表扫描。
规则阈值:自定义(表大小,单位GB)。
规则描述:对大表执行了全表扫描操作,执行计划中包含"TABLE ACCESS FULL"字样。
【规则39】
规则说明:大索引全扫描。
规则阈值:自定义(索引大小,单位GB)。
规则描述:对大索引执行了索引全扫描操作,执行计划中包含"INDEX FULL SCAN"字样。
【规则40】
规则说明:大索引快速全扫描。
规则阈值:自定义(索引大小,单位GB)。
规则描述:对大索引执行了索引快速全扫描操作,执行计划中包含"INDEX FAST FULL SCAN"字样。
【规则41】
规则说明:索引跳跃扫描。
规则描述:对索引执行跳跃扫描操作,执行计划中包含"INDEX SKIP SCAN"字样。
【规则42】
规则说明:分区全扫描。
规则描述:对分区表进行了全分区扫描,执行计划中含有“PARTITION RANGE ALL”字样。
【规则43】
规则说明:非连续分区扫描。
规则描述:非连续分区扫描,执行计划中含有“PARTITION RANGE INLIST”或“PARTITION RANGE OR”字样。
【规则44】
规则说明:跨分区扫描。
规则描述:连续的分区扫描,执行计划中含有“PARTITION RANGE ITERATOR”字样。
2.4 类型转换
【规则45】
规则说明:存在隐式转换。
规则描述:在条件判断中使用了隐式数据类型转换。
2.5 其他执行计划
【规则46】
规则说明:存在大结果集排序操作。
规则描述:可考虑通过引入索引等操作避免排序。
【规则47】
规则说明:存在并行访问特征。
规则描述:并行很影响性能,一般情况下需要避免。
【规则48】
规则说明:存在视图访问。
规则描述:视图操作一般可以合并、解嵌套等,如都不行应该排查视图定义。
三、Oracle规则(执行特征)
3.1 执行特征
【规则49】
规则说明:扫描块数与返回记录数比例过低。
规则阈值:自定义(百分比)。
规则描述:扫描大量数据但返回记录数很少,需要从逻辑上调整SQL语句。
【规则50】
规则说明:子游标过多。
规则阈值:自定义(子游标数)。
规则描述:子游标过多,可能存在执行计划不稳定的情况。
【规则51】
规则说明:elapsed_time。
规则阈值:自定义。
【规则52】
规则说明:cpu_time
规则阈值:自定义
【规则53】
规则说明:buffer_gets
规则阈值:自定义
【规则54】
规则说明:disk_reads
规则阈值:自定义
【规则55】
规则说明:direct_writes
规则阈值:自定义
【规则56】
规则说明:executions
规则阈值:自定义
四、MySQL规则(对象)
4.1 表、分区
【规则57】
规则说明:超过指定规模且没有分区的表。
规则阈值:自定义(表大小,GB)。
规则描述:表的规模过大,将影响表的访问效率、增加维护成本等。常见的解决方案就是使用分区表,将大表转换为分区表。
【规则58】
规则说明:单库数据表过多。
规则阈值:自定义(表个数)。
规则描述:单库数据表过多,将影响整体性能。必要时,进行业务逻辑的垂直拆分。
【规则59】
规则说明:单表(分区)数据量过大。
规则阈值:自定义(数据规模,记录数)。
规则描述:单表(分区)数据表过多,将影响整体性能。必要时,进行分库、分表或定期清理、归档数据。
4.2 索引
【规则60】
规则说明:单表索引数量过多。
规则阈值:自定义(索引数量)。
规则描述:单表索引数量过多,不仅维护成本高,而且占用更多的空间。
【规则61】
规则说明:存在重复索引。
规则描述:索引能由另一个包含该前缀的索引完全代替,是多余索引。多余的索引会浪费存储空间,并影响数据更新性能。
【规则62】
规则说明:索引选择率不高。
规则阈值:自定义(选择率,百分比)。
规则描述:索引选择率不高,将导致索引低效,请调整索引字段。
4.3 约束
【规则63】
规则说明:表存在外键。
规则描述:外键资源将消耗数据库的计算能力,建议通过应用层保证数据约束。
【规则64】
规则说明:表没有定义主键。
规则描述:没有定义主键,MySQL会自动创建主键。这不是一种好的设计方法。
4.4 字段
【规则65】
规则说明:存在大对象字段。
规则描述:大对象字段将影响存取性能、耗费较多空间,建议在数据库之外存储。
【规则66】
规则说明:单表字段数过多。
规则阈值:自定义(字段数)。
规则描述:表字段数过多,将造成记录过长,单页存储记录数减少。可考虑拆表处理。
【规则67】
规则说明:单表字段定义长度过长。
规则阈值:自定义(字段长度,单位字节)。
规则描述:应控制单表定义长度,避免过长记录。
【规则68】
规则说明:单表主键字段定义长度过长。
规则阈值:自定义(字段长度,单位字节)。
规则描述:应控制主键字段长度,过长的主键字段会造成索引空间消耗过大。
【规则69】
规则说明:表没有定义时间戳字段。
规则描述:时间戳字段是获取增量数据的最佳方法,请为表定义时间戳字段。
【规则70】
规则说明:字段数据类型定义错误。
规则阈值:自定义(记录数)。
规则描述:根据字段保存内容判断,字段类型定义异常,建议选择适合的数据类型。
4.5 其他对象
【规则71】
规则说明:单表存在函数、存储过程、触发器。
规则描述:存储过程、函数、触发器等都将消耗数据库的计算能力,建议通过应用层保证数据约束。
五、MySQL规则(执行计划)
5.1 访问路径
【规则72】
规则说明:大表全表扫描。
规则阈值:自定义(表大小,单位GB)。
规则描述:对大表执行了全表扫描操作。
5.2 SELECT_TYPE
【规则73】
规则说明:DEPENDENT UNION
【规则74】
规则说明:SUBQUERY
【规则75】
规则说明:DEPENDENT SUBQUERY
【规则76】
规则说明:MATERIALIZED
【规则77】
规则说明:UNCACHEABLE SUBQUERY
【规则78】
规则说明:UNCACHEABLE UNION
5.3 ACCESS_TYPE
【规则79】
规则说明:fulltext
【规则80】
规则说明:index_merge
【规则81】
规则说明:unique_subquery
【规则82】
规则说明:all
【规则83】
规则说明:index range
5.4 其他执行计划
【规则84】
规则说明:使用临时表。
规则描述:执行过程中使用了临时表,执行计划中包括"using temporary"。
【规则85】
规则说明:使用磁盘排序。
规则描述:执行计划中使用了磁盘排序,执行计划中包含"using filesort"字样。
六、MySQL规则(执行特征)
6.1 执行特征
【规则86】
规则说明:index_ratio
【规则87】
规则说明:lock_time_sum
七、Oracle+MySQL(语句级)
7.1 查询类
【规则88】
规则说明:select *
规则描述:禁止使用select *,必须明确选择所需的列。
【规则89】
规则说明:重复查询子句。
规则描述:禁止使用重复的查询子句,应使用with as替换子句(仅限Oracle)来提升SQL执行效率。
【规则90】
规则说明:查询字段引用函数。
规则描述:禁止在查询字段中引用函数(类型转换函数、函数索引情况可忽略)。
【规则91】
规则说明:嵌套select子句。
规则描述:禁止出现select子句的嵌套子查询,避免出现性能问题。
【规则92】
规则说明:出现union。
规则描述:防止出现不必要的排序动作。
【规则93】
规则说明:多个过滤条件通过or连接。
规则描述:防止优化器出现选择异常。
【规则94】
规则说明:谓词条件使用like '%xxx'
规则描述:无法使用索引。
【规则95】
规则说明:谓词中存在负向操作符。
规则描述:!=,<>,!<,!>,not exists,not。
【规则96】
规则说明:存在子查询情况。
规则描述:这个要区分位置(select、from、where、having等部分)。
【规则97】
规则说明:存在三个以上的表关联。
【规则98】
规则说明:存在全连接或外连接。
规则描述:cross join或outer join情况。
7.2 变更类
【规则99】
规则说明:update中出现order by子句。
规则描述:防止更新过程中出现不必要的排序。
【规则100】
规则说明:update中必须出现where子句。
规则描述:防止出现意外的全部更新动作。
【规则101】
规则说明:更新主键。
规则描述:禁止出现更新主键的情况。
【规则102】
规则说明:delete中出现order by子句。
规则描述:防止删除过程出现不必要的排序。
【规则103】
规则说明:delete中必须出现where子句。
规则描述:防止出现意外的全部删除动作。
【规则104】
规则说明:新增SQL文本过长规则。
【规则105】
规则说明:新增IN List元素过多。
作者:韩锋
首发于作者个人公号《韩锋频道》。
来源:宜信技术学院