
DevOps是什么?

对于传统的软件研发而言,开发,测试,运维,运营,有不同的岗位进行分工协作,以保证质量和专业度,同一件事情,依赖不同岗位的排期、沟通、协调,效率难免会有打折。而对于互联网业务来说,快速的迭代,对人力的需求非常强烈,不大可能有足够的人力支撑这么多岗位。同时跨部门的沟通,强烈影响了项目的进度,因此一些快速发展的团队,开始推行DevOps,自己做测试,保证代码质量,自己上线运维,监控告警。亚马逊很早就开始推行"you build it, you run it"的文化。由于自己对自己的做事情很清楚,因此效率也会很高。这就是DevOps。
DevOps的挑战

DevOps责任多,事情多且杂。一天的时间怎么分配?我作为研发,肯定是希望一天90%能够专心的写代码。但实际上只有20%的时间来写代码,其他的时间做什么?帮用户调查问题,处理工单。做线上的运维等等。用户提了一个工单,你要立马放下手中的工作去帮用户调查问题。结果就发现时间被碎片化了,一天中很难有大块的时间去专门做研发。
通过数据驱动和智能自动化应对DevOps的挑战

怎么解决研发过程中时间碎片化的问题?我们原来做了很多重复性的工作,这些工作可以总结和沉淀下来,通过工具帮我们去沉淀。我们原来需要调查问题的时候,才登录集群要抓日志;现在做一个采集日志的工具,把所有日志的实时采集到云端,当需要看日志的时候,我立马就可以在服务端看到所有的日志信息。原来需要到机器上搜索日志,现在在云端做倒排索引,直接就可以搜索到整个集群的日志。原来我可能要用excel做一些数据分析的工作,去分析我的运营效果怎么样。现在在服务端实现一套实时分析的计算引擎,再加上可视化功能,帮助做各种各样的报表。原来调查问题的时候要登录集群上,用vim打开集群上的日志,看文件上下文是什么样子的。现在在云端做一个上下文关联的功能,直接在云端就可以看到所有集群上的日志和上下文信息。原来调查问题可能依赖于人的经验。现在通过AI帮我们做自动化的事情。

所以总结下来我们希望通过数据中台帮我们实现数据驱动的运维,来代替原来的人工驱动。借助于AI帮我们实现自动化、智能化。通过这种数据驱动加上智能自动化的运维帮我们节省被碎片化的时间。
数据中台的挑战

如果我们要做这样一个数据中台会面临哪些挑战呢?首先就是数据太少,如果我们抓取的数据太少的话,那么我们的信息量就会太少,在分钟级别的监控里面可能很多信息就被平均掉了,我们只有抓秒级监控才可以看到我们所关心的数据。第二个是实时性的挑战,我们做线上故障恢复的时候,都希望是说可以尽快定位问题的答案,尽快去恢复,这就是一个实时性的需求。如果我们找到答案太慢,可能已经错过了一个最佳的自救的时间。第三,系统越来越复杂,我们的需求是越来越多的,我们每加一个需求要加一个模块,那么维护整个一套系统其实是一个非常大的挑战。最后是数据太多的问题,数据太少是问题,太多也是问题。太少的话信息量不足,太多的话很多重要的信息被淹没。关于数据规模的问题和数据速度的问题可以通过数据中台来解决,数据中台帮我们通过算力来换取一个数据的速度和规模;而数据太多信息爆炸的问题,我们用AI算法来换取对数据深入的洞察力。
数据中台的基础能力

数据中台具备的能力,第一个就是数据采集,数据采集帮我们从各个数据孤岛中,从各种环境中,把各种各样的格式的日志统一采集,然后以统一的格式被存储起来。原来数据可能在手机上,可能在网页上等等各种各样的环境,格式也不一样。统一采集之后, 我们就有统一的格式,以后分析就非常方便了。数据采集帮我们做的脏活累活,其实是帮我们节省了很多的时间。数据采集之后,中台要有二次加工的能力。为什么要二次加工?因为我们采集过来的数据可能包含着脏数据,垃圾数据,我们要过滤掉,做一些转换和富华。增强数据质量,数据质量增强以后,分析的时候才可以得心应手。接下来就是一个查询分析的能力,中台提供的进行交互式的查询分析,可以在秒级别分析上亿日志。通过这种查询分析能力你可以尽情的探索你数据里面包含了什么价值。查询分析依赖于人的经验探索数据,那么我们还可以借助AI自动探索数据,这就是AI的预测能力和异常检测能力以及根因分析的能力。通过数据中台将AI,帮助我们去获取对数据源的可观察性,进而通过数据可观察性,实现对运维系统的可观察性。
基于数据中台的问题调查路径

我们前面介绍了数据中台的,接下来我会以一系列的实践去分享我们怎么样利用这样一个数据中台帮我们解决我们DevOps所遇到的各种各样的问题。
我们说到数据驱动的运维,首先我们会面临大规模的数据,如何去找有效的信息,这就是一个发现的过程。原来我们通过grep搜索的关键字,通过awk做一些简单的计算;借助中台,我们可以通过交互式查询去不停探索答案,也可以通过异常检测帮助我们智能的检测数据里面到底有什么异常的信息。
当我们发现一些有效信息以后,接下来怎么办?我们要从这些线索出发,然后去找更多的线索,去找关联关系,去找因果关系,这个就是上下文钻取,以及聚类。那么通过这种钻取我们可以找到一系列的更加关联的信息,我们最终找到了信息足够多之后,我们要确定最终的一个答案,这个就是根因分析,帮我们确定故障的根本原因是什么。
数据驱动和AI驱动的DevOps实践
1:搜索和上下文

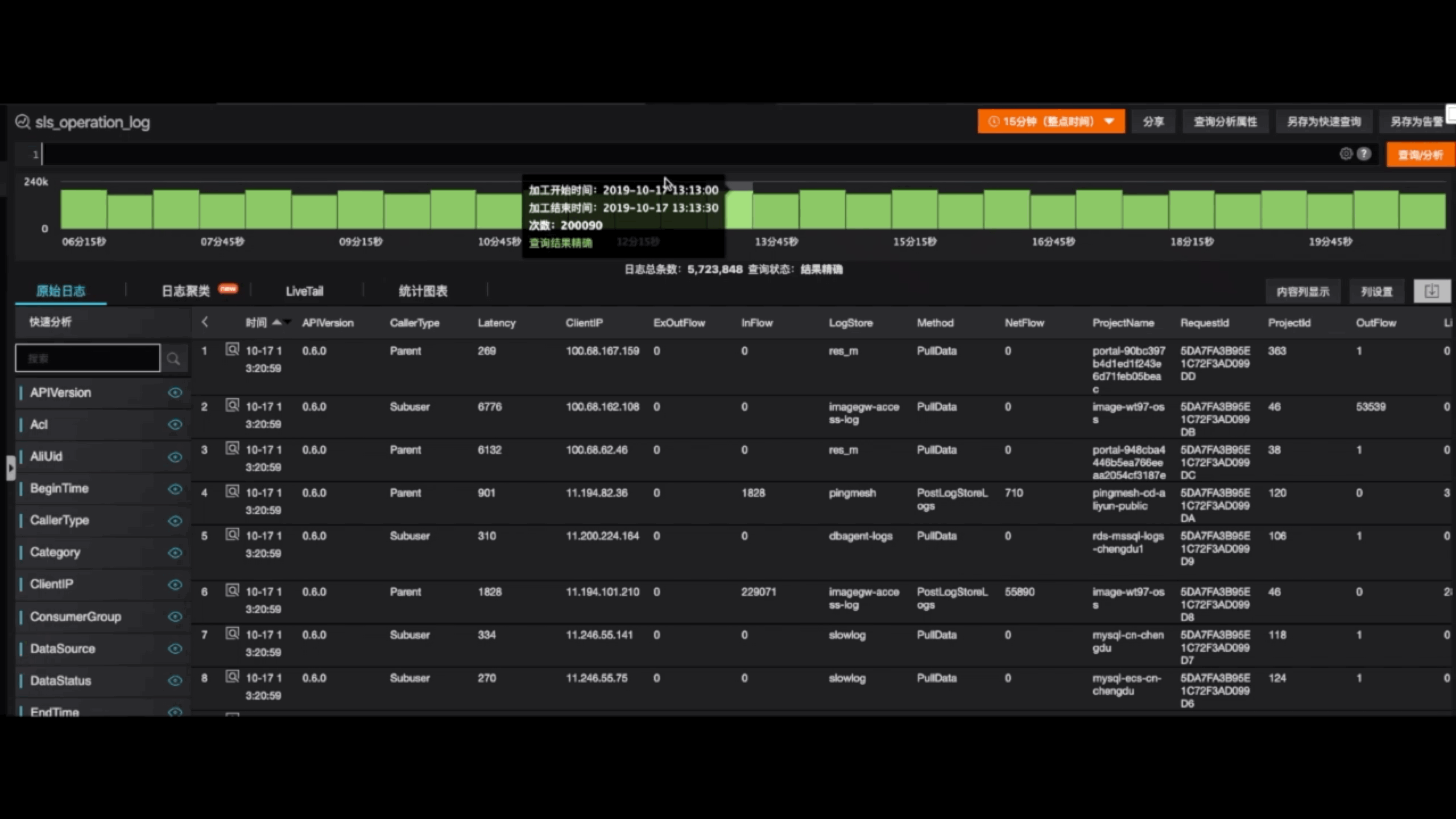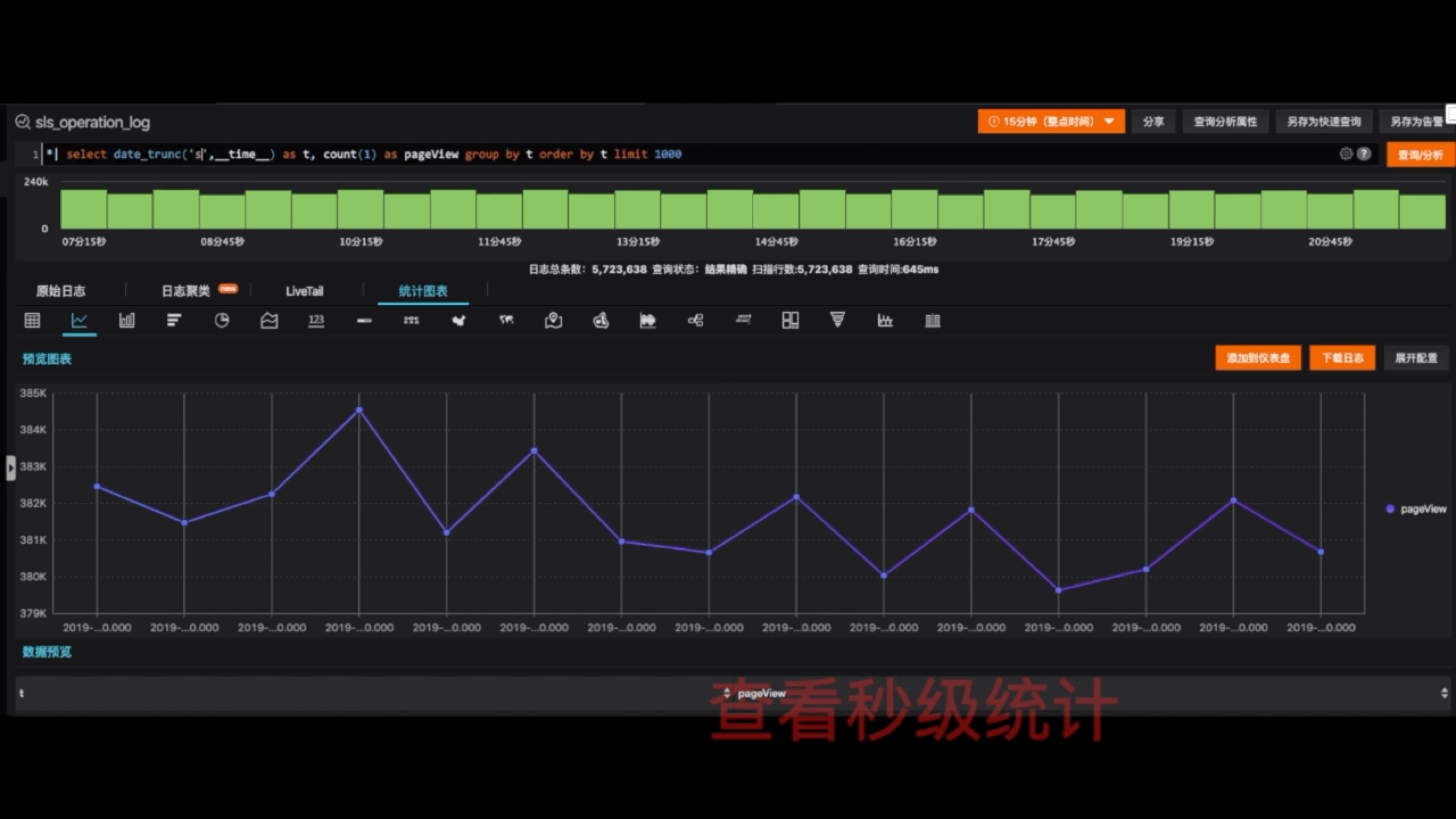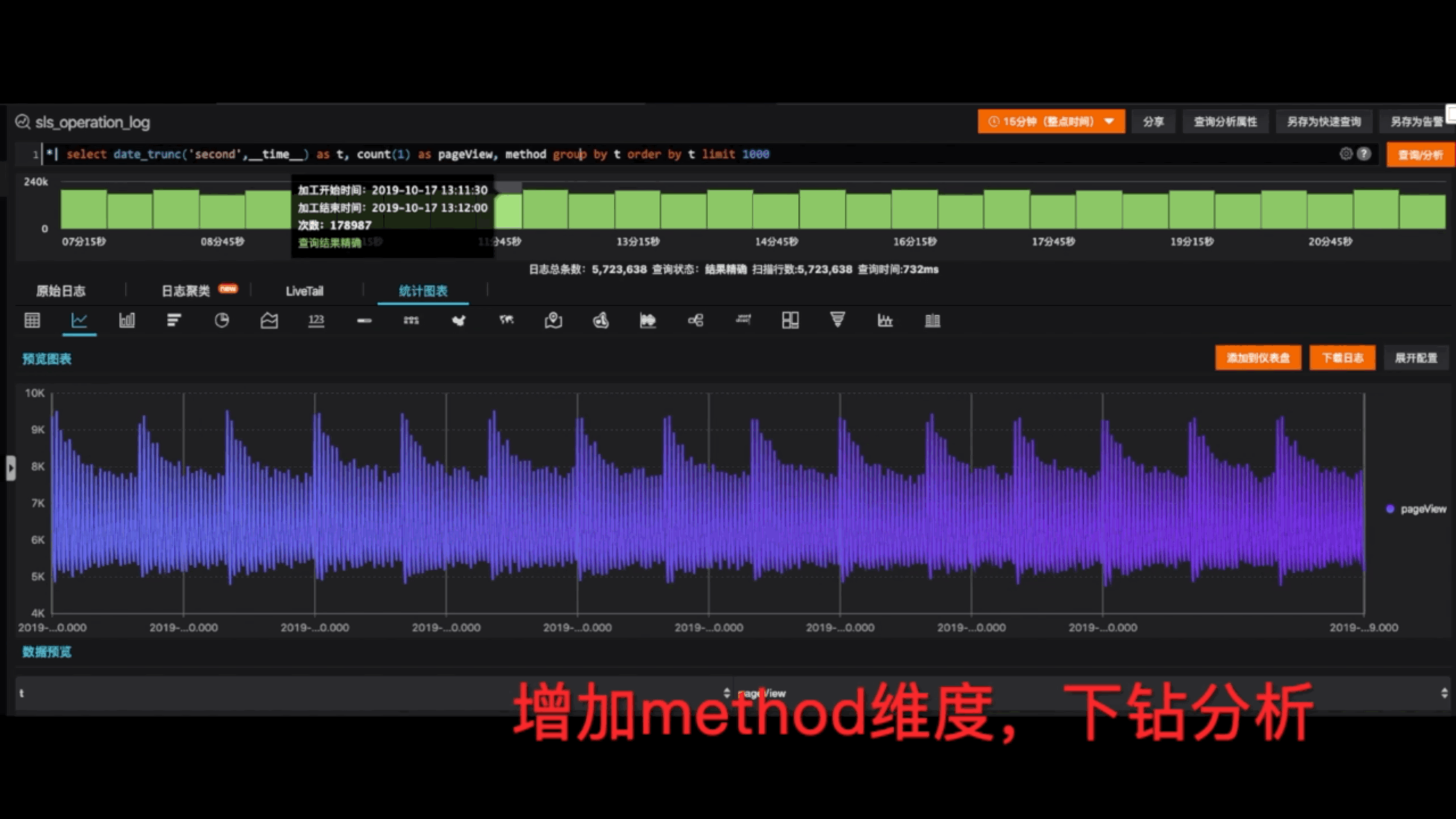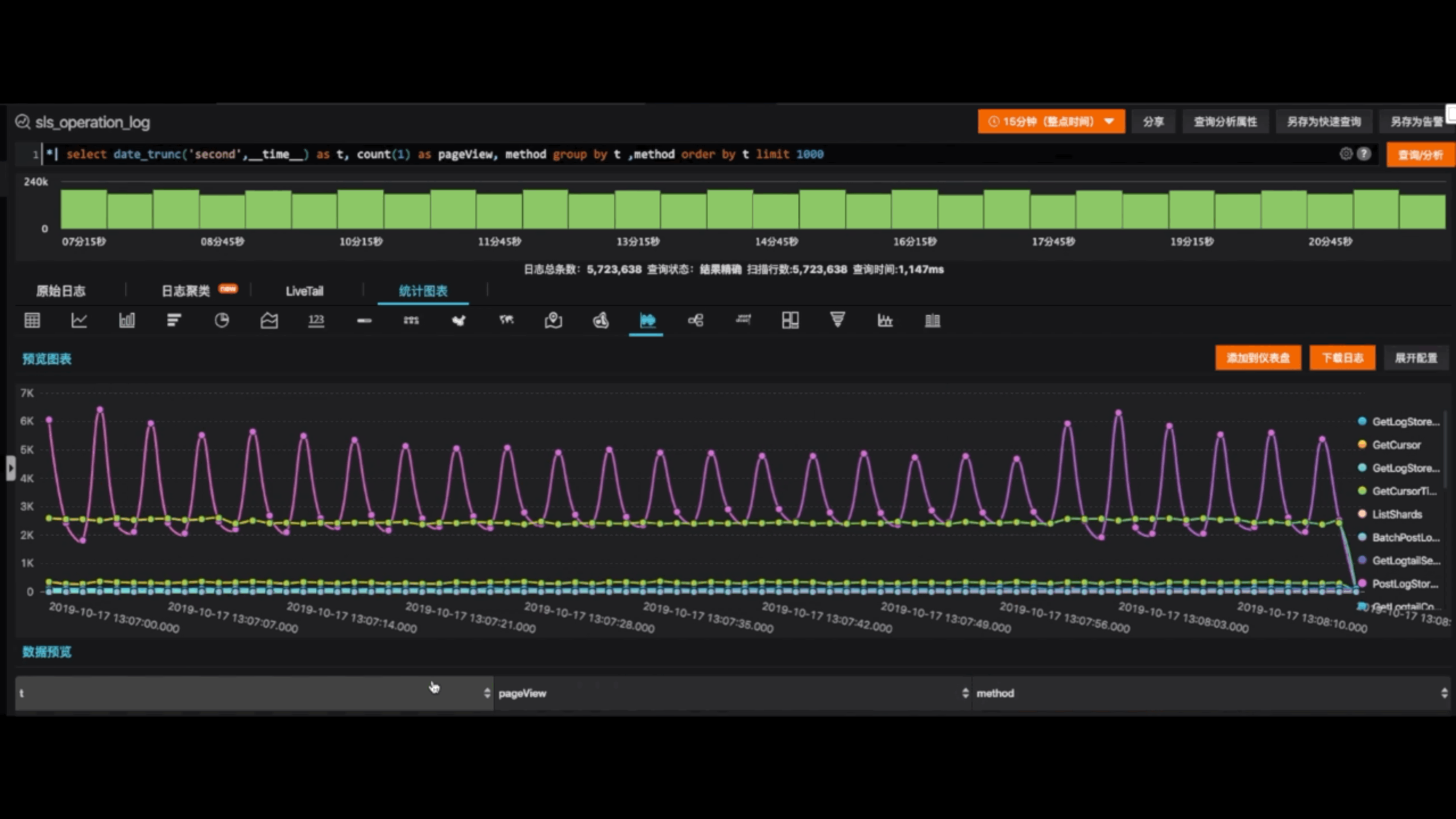
我们做数据分析最简单的形式是什么?我们上网的时候,用的最多的工具是什么?是搜索引擎,搜索可以帮我们尽情探索数据中的价值。原来我们到机器上搜索日志,数据在文件中是是有序的存储的。而在采集的过程中,为了性能的考虑,会以乱序的形式存储下来,当然我们搜索完之后,可能我们看到的是乱序的日志。如何从这些乱序的日志中找它的上下文信息呢?我们为每一条日志指定一个编码。当我们搜索到一条日志之后,去看它的编码值,再去计算它的下一条编码是什么,根据编号搜索下一条日志。通过这种方式去找,搜索,去定位下上文

我们看一个搜索和上下文的样例。我们把所有集群的日志都被统一的采集到一起,然后去搜索整个集群日志,这个时候如果我们对某一台机器感兴趣的话,我们可以把机器的hostname加入到搜索条件里面去。这个时候如果我们对某一些关键字不感兴趣的话,我们可以过滤掉。这个时候我们定位到9条日志,我们对这9条日志感兴趣。我们可以去看上下文的信息。在上下文里面,可以以上下文严格有序的一种形式去看这条日志前后发生的一些事情,通过这种方式找它的一个因果关系。
2:全局视野和局部视野

搜索针对的对象是什么?是日志;日志是什么?是一种事件类型的数据,里面包含的信息有事件的发生的时间、对象、操作,还有各种属性,关于事件的描述是非常详细的。除了这种事件日志,还有一种指标日志。指标日志有时间,有一个汇总的数值,例如用一个数值表示这一分钟有多少个浏览量。这两种数据有什么区别?事件日志描述的是一个非常详细的信息,所以它的体量和规模是非常大的。它代表的是我们从局部去观察问题的一种视角。而指标数据是一种汇总的信息,所有它的体量非常小。但是它代表的是一种全局视角,概括整个事件的信息。例如,我们一分钟有1万次的访问,我们用这种事件日志来表示可能就真的是1万条数据。用这种指标日志可能就是1万这一个数字,这就是两者之间的差别。这两种日志之中是不是割裂的?不是,我们可以通过计算把事件日志转化为指标日志,一个是代表大视野,一个代表小视野。我们可以充分利用计算在这两种视野之间切换去调查问题。
举个例子,我们面对一个事件日志,可能对某一些维度感兴趣,比方说时间维度,那么在时间维度中统计趋势指标;或者对IP维度感兴趣,可以统计出IP分布,他们这个时候我们就把一个事件日志转化成了指标日志,从局部视野跳到全部视野看待问题。
当我们看到某一个数值比较特殊,我们对它进行下钻,增加维度,进行更多的统计。比方说我们按照不同的IP统计出它的趋势。假如统计出来的各个维度之间,我们对某一些维度感兴趣的话,我们把它单独拎出来,跳回我们原来的事件日志当中,帮我们搜索对应的事件。这样的话我们就形成了一个调查问题的闭环,我们从事件日志出发去统计它全局的信息,再回到原来的事件,这是一个闭环。
3:聚类解决数据爆炸

事件日志的体量是非常大的,现在对于我们的业务来说,每天的数据量都在上涨,每分钟能达到上亿条的日志,日志这么多,重要的信息被淹没了怎么办?即使我们只关心错误的日志,但是错误的信息可能都有上千条,什么时候看完?我们通常对于这很多大量日志的这种场景,首先想的是排除法,比方说我们先把一些不关心的日志排除掉,逐步排除掉一些关键字,逐步的缩小数据的体量,慢慢靠近我们关心的信息。对于数值类来说,我们怎么样排除?我们可能统计数值的百分位,去统计它的25分位在哪里,75分位在哪里?99分位在哪里?假如说说我们对99分位感兴趣,只需要过滤出来99分位以上的数据,通过这种方式减少数值类型数据的体量。
但是这种排除法不一定可以帮助我们找到所有我们所关心的问题,因为我们现在的业务实在是太复杂了,维度太多了。有一个真实的案例,就是有一次我们一个新版本发布,有一个边界的条件没有测试到,上线之后也没发现,直到用户跑过来问,为什么我之前可以用,现在不能用?现在开始报错了?我到这个时候才发现发现,真的是从升级那一刻开始出现一种新类型的日志,原来都没有这种日志。显然用排除法是没有办法帮我解决升级后的这种异常检测,怎么办呢?那我们引入了智能聚类。即使每分钟产生上亿条日志,可能里面不到100种类新的事件,只是说每一种类新的事件重复发生了很多次,所以造成整体数据的膨胀。

通过这种分析数据之间的关联性,把数据里面的干扰信息过滤掉,提取出里面一些公共的特征,这个就是聚类。在这个例子中我们有1300万条数据,人眼去看这1300万条可能一天一夜也看不到。但是我们可以通过聚类,最后只有35条聚类的结果,这个时候我们去看35种类型的事件,其实一眼就可以看到,那么在机器上到底发生了什么事情。比如说,我可以一眼看到这是有这样一个timeout关键字,是不是要特殊的关注它?
我们怎么样利用智能聚会帮助我们解决升级后故障发现的问题。我们可以通过对比升级后你的聚类结果和升级前了聚类结果,查看有没有什么差别,如果一个新的事件在升级之后出现了,而之前是没有的,这是特殊关注的。通过这种方式我们去做告警,及时发现问题,及时的处理,避免影响到用户。
4:Metric数据异常检测

通过智能聚类实现对文本类的数据异常类检测。那么对于我们刚才说的Metric指标数据,怎么样寻求异常检测?最简单的指标什么?是一条平稳的直线,围绕这样一条直线,可能有一个很轻微的在正常范围之内的波动,对于这种数值我们设一个固定的阈值,可以很好的把一些大的抖动捕获出来。但是这是一种非常简单的场景,在现实的业务中其实没有这么简单的,现实的数据一定是有各种各样的波动。
最常见波动是什么?是周期性。一般我们工作日它的流量比较高,到了周末流量又跌下去了,那就是一个周期新的波动,所以对于波动性的信息我们怎么样做异常的检测?我可以通过同比、环比,拿当前时间点的数据和上一个周期同一个时间点的数据进行对比,看看有没有发生比较大的偏差,这就是同环比算法。
还有一种情况就是趋势性,对于互联网业务来说,增长是一种常态,没有增长的业务是没有前途的。在增长的趋势中,可能还有周期性的波动,以及扰动。我们所关心的那种异常的点可能被掩藏在这样一个增长的趋势中,对于人眼来说,其实一眼就可以看出来哪一个点是异常点。但是对于算法来说检测出来这样一个异常点是一个很大的挑战。我们的解决方案是通过机器学习,通过学习历史上的数据它的一个趋势性信息,周期性信息,然后去预测未来的点是什么样子的。那么把预测的点和真实出现的这个数据进行一个对比,那么当这样一个差值发生比较大的偏差的时候,就认为这是一个异常的点。通过这种方式去检测趋势性数据里面的一个异常点。
不管是周期性信息还是趋势性的信息,它其实都是一种很规律的一种波动。那么还有一种数据波动称为断层。比方说原来我们一个机器,它的CPU很低。突然有一天你把流量切到机器上,它的CPU立马暴涨到另外一个水平,但是它的波动又没有什么变化,这就是断层。对于断层的数据,其实统计的时候是非常难的,因为在这样一个点里面它的导数是没有的。那么我们可以用专门的断层检测算法去检测出来。
最后一个就是变点,变点是什么?就是在某一个点,它的波动形态、统计特征发生了变化。原来可能是一条平稳的直线,但是在某一个时间点假如说发生了异常,你的流量抖动开始发生了非常大的一个抖动,这就是一个变点。通过变点算法,统计所有数据里面的波动信息,然后对比不同点上的波动信息进行检测这种变点。这就是我们针对Metric指标数据,利用机器学习、统计算法进行异常检测的方法。
5:异常根因分析

当我们检测到异常之后,下一步要做什么事情?要找这个异常它发生的原因是什么?并且及时的去修复它。假如我们网站流量下跌了7%,下跌是什么原因引起的?通常人工是怎么检测这个问题的?我们可能按照我们的经验逐步去排查,比方说我们先到服务端看一下,有没有错过日志;服务端没有,再看网络上有没有抖动。OK,那网络端没有抖动,接下来怎么办,再去看用户的统计上有没有异常的一些抖动,结果发现,用户的统计上有抖动的话怎么办?我们再去下钻,去看什么类型的用户发生了抖动。比方说不同的城市有没有抖动,不同的接入点有没有抖动?不同的客户端有没有抖动?结果发现在客户端这样一个维度,有数据是抖动的。那么我们再深入的下钻去找哪一种类型的客户端发生了问题。通过这种逐层的下钻,逐层去找,最终定位到版本因素造成了流量下跌。

这是我们人工调查问题的一个方法,这一套流程走下来其实是非常耗费时间的。我们怎么样借助算法帮助我们做这种异常检测呢?这就是关联规则算法,大家都听说过啤酒和尿布这个故事:在一大堆物品当中,啤酒和尿布同时出现的频率非常高,所以我们认为它两个之间是有关联关系的,然后进行关联推荐。我们可以把这种关联推荐给映射到根因分析算法。比方说我拿了一个访问日志,访问日志里面有很多的错误信息,然后我们再把网络日志拿过来。结果发现在网络日志里面某个交换机经常会和这个错误日志同时出现,是不是可以认为这个交换机上出现了错误?
如何找两个关联的项目,就是我们通过频繁集算法。我们把一份错误的日志拿出来,找这个日志里面它高频出现的一些数据集合。比方说我们在这样一个错误日志里面定位到IP等于1002这样一个用户,他出现的频率是68%,那么是不是认为这样一个用户他就是造成我们错误的一个原因?不一定。为什么?因为这个用户可能在错误的日志中出现的频率比较高,但是在正确的日志中出现的频率也是非常高的,所以你不能简单认为他就是一个错误的原因。那怎么办呢?要通过差异集合算法进行统计,我们把一份完整的数据,按照是否有错误,分成正负两份样本,然后比较两个样本里面的频繁集有什么差别,如果某一个集合它在一个错误的集合中出现的频率比较高,而在正确的集合里面出现的频率比较低,就可以认为这个集合是造成错误的根本原因。

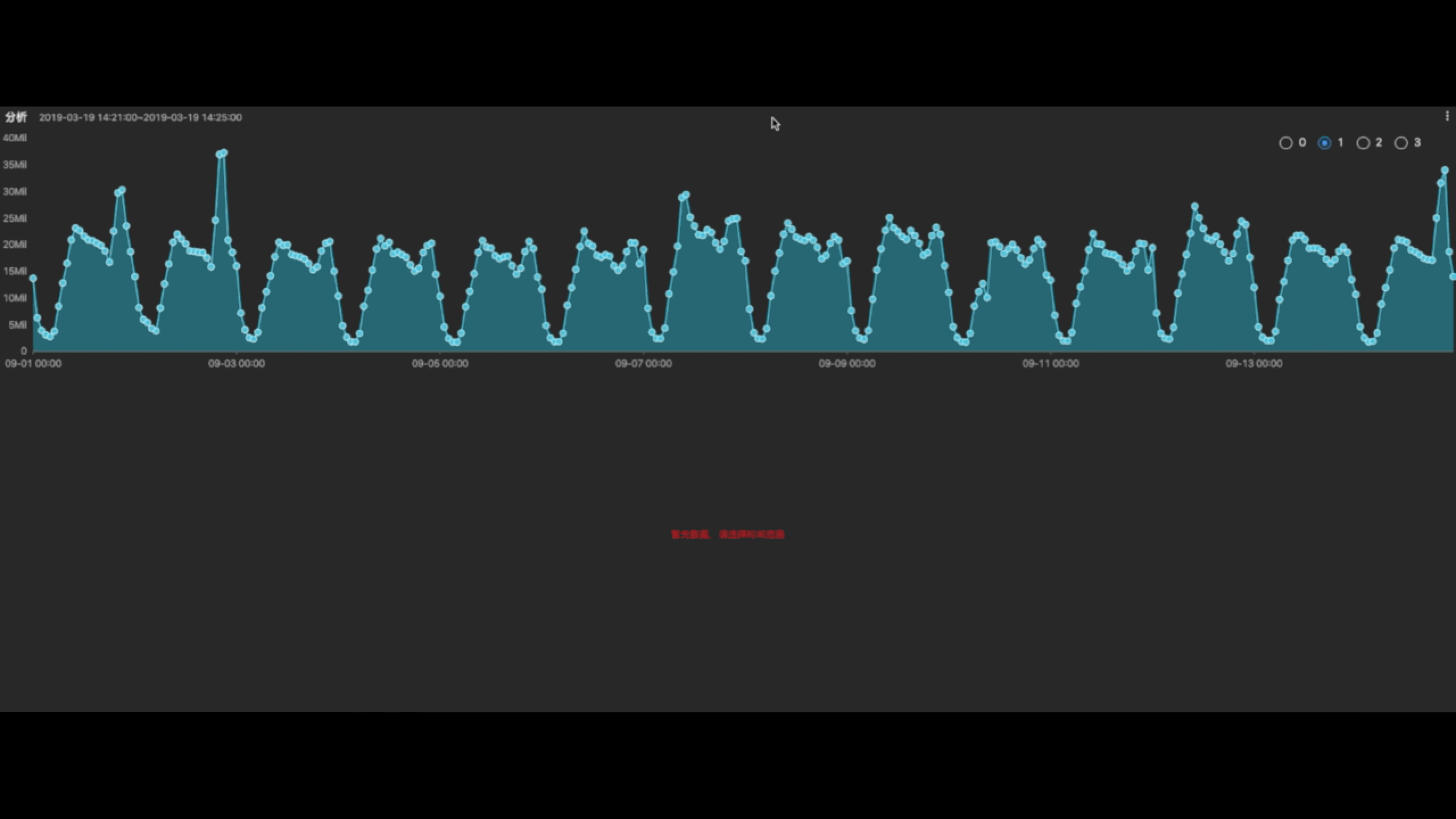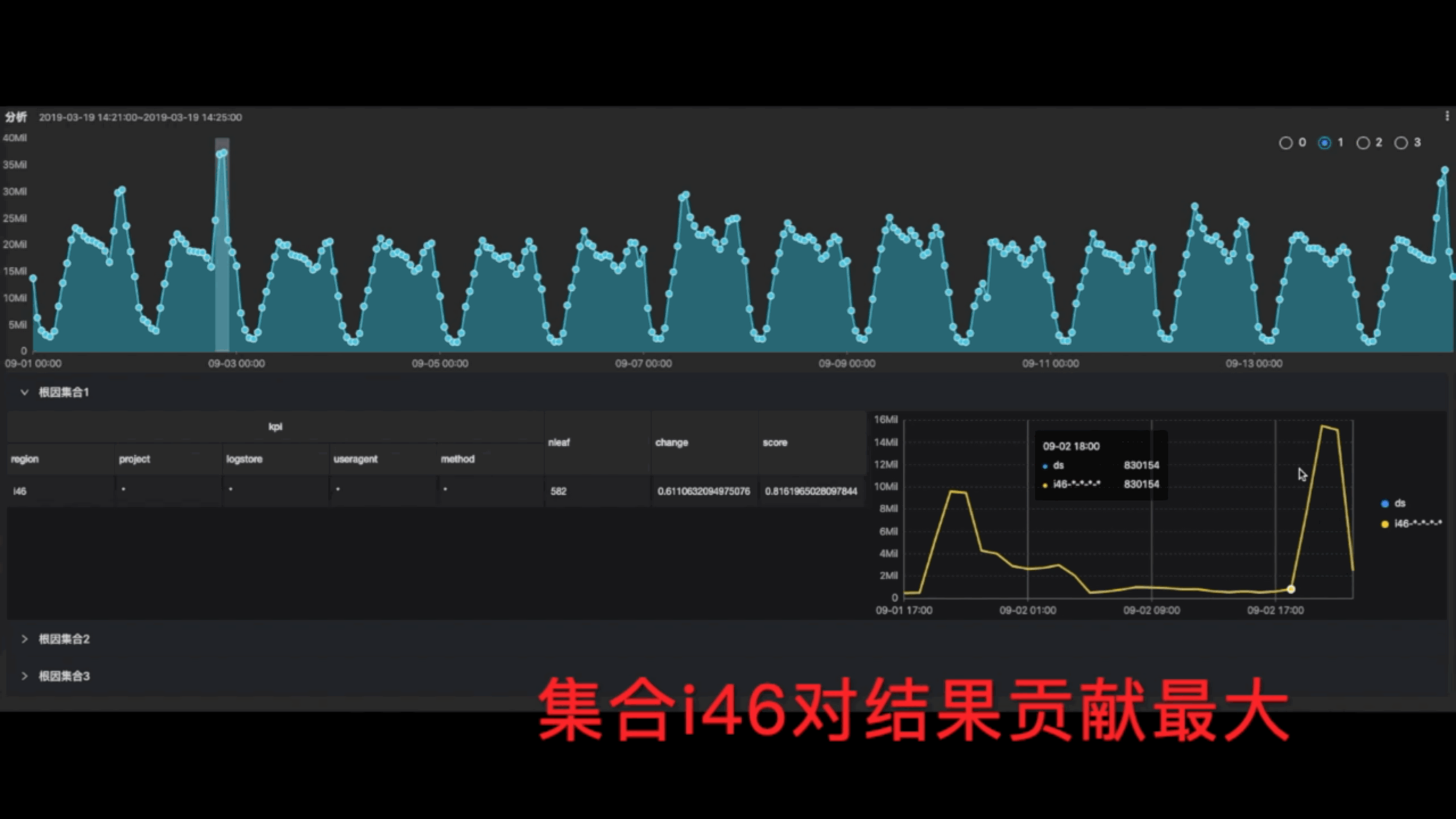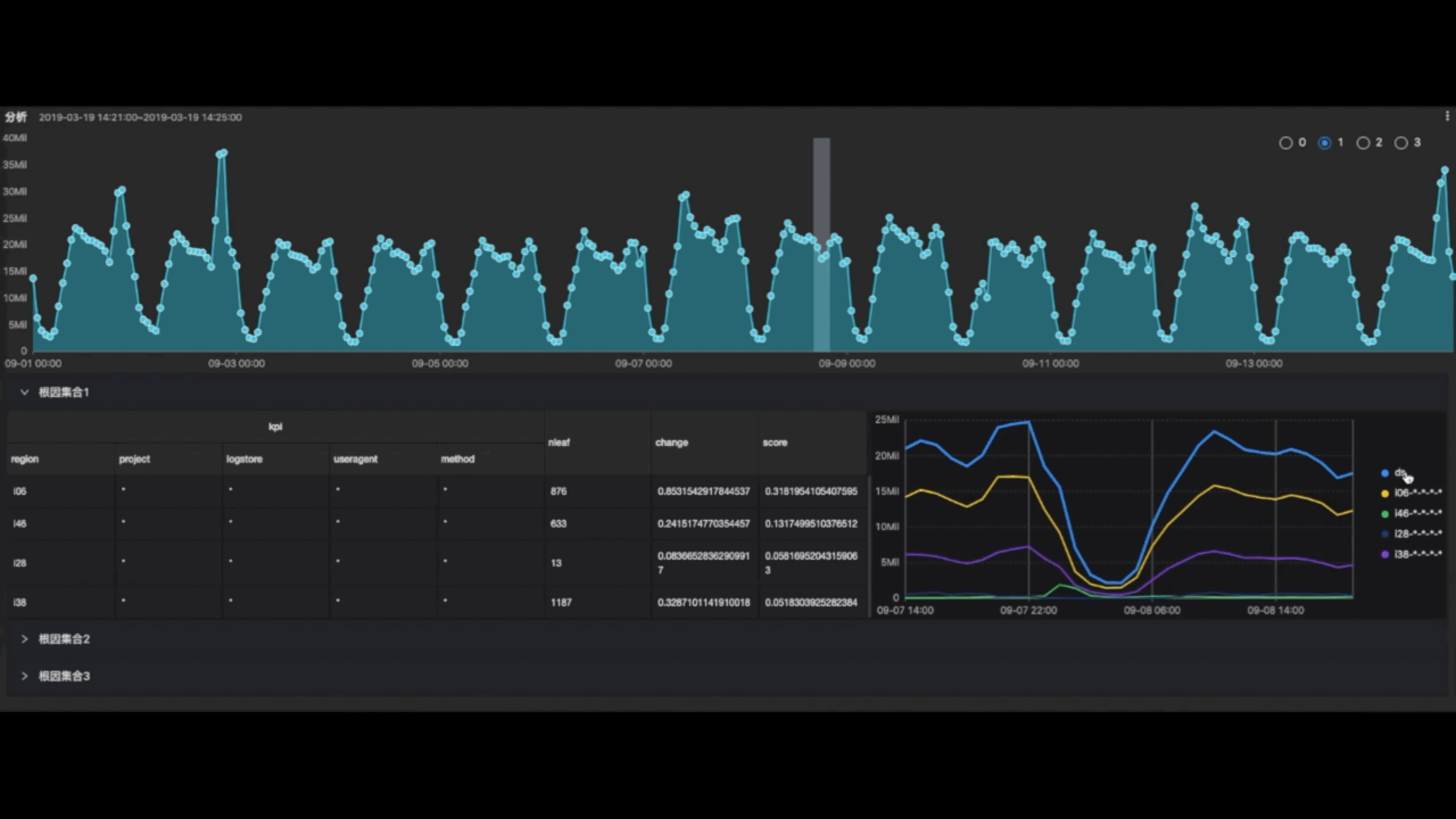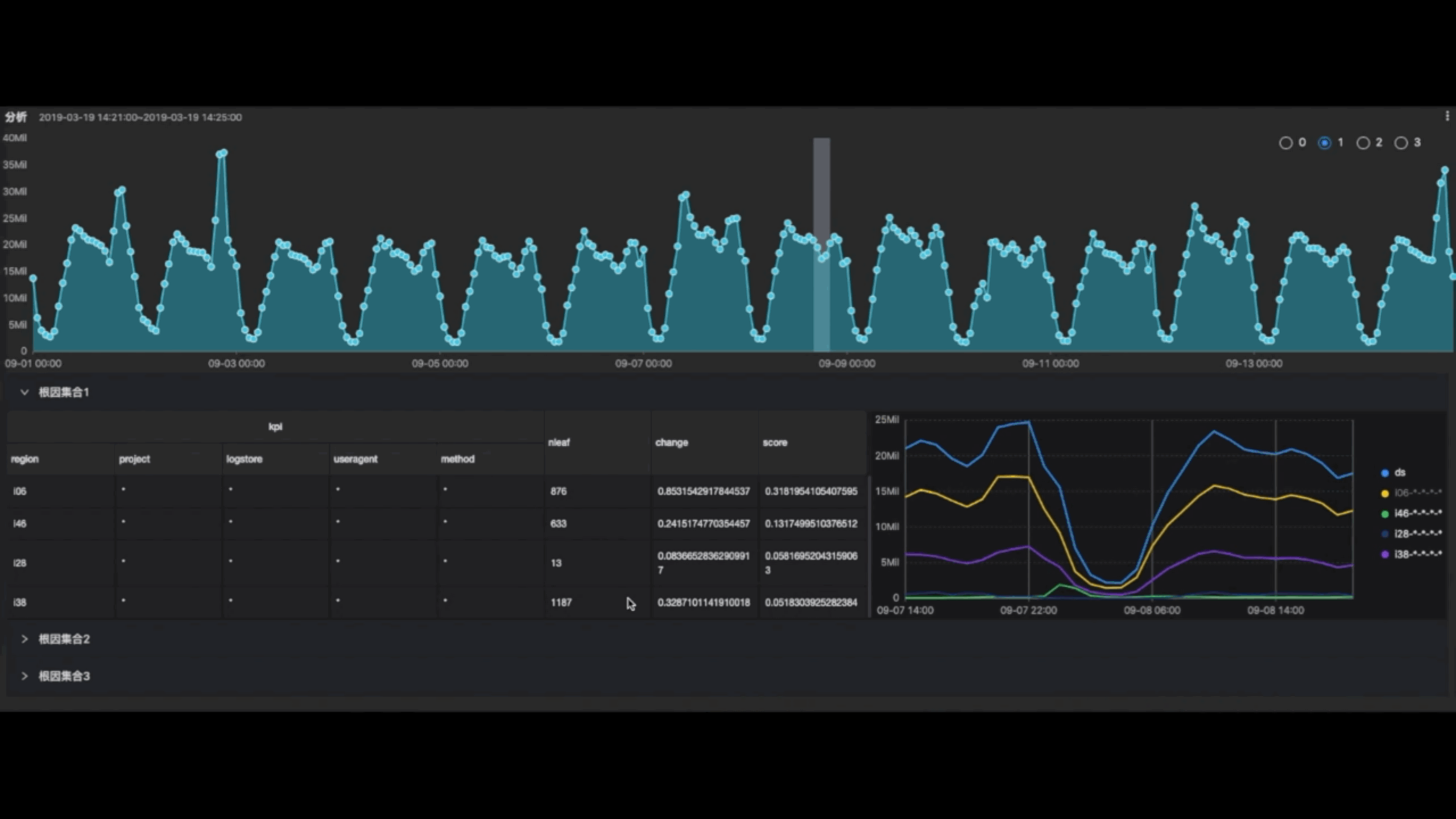
如果我们再引入到时序维度,针对我们刚才说的网站浏览量下跌的问题,我们怎么样做这种根因分析呢?我们首先面对一个汇总的流量下跌的曲线,然后可以把我们所关心的维度都引入进来,例如地区维度,运营商维度,客户端维度全部引入进来,把各种维度自由组合各种各样的集合,那么我们算出来每一个集合它的一个流量曲线,计算算每一个集合它下跌的一个趋势,和整体流量下跌趋势之间的关联度,并且打分,按照分数的高低寻找根因集合。通过这种打分找出来一个集合,它对整个流量下跌的贡献是最大的。比方说我们最终统计出来上海这个地区所有的运营商流量下跌都非常的严重,打分非常高,那我们认为上海这个集合就是根因。
6:DevOps成本控制

对于我们DevOps而言,我们不仅要关心我们所做的成果,还要关心我们的成本,因为拿堆资源做出来的成果不代表一个人的能力,用最少的资源做最大的事情才可以代表一个人的能力。我们通常做采购机器,然后等待机器到货、上架,最终部署这个软件,交付。这是一个原来传统的上线机器的流程。这个流程是很长的,一般过几个月才能拿到机器。现在有云服务,一键可以创建机器,当你需要的时候可以立马拿到资源,这样一个流程实在太方便了。但是就是方便背后其实也有一些其他的困扰。比方说我一次测试的时候买了一台机器,用完之后忘了释放,结果这机器在那里跑着一直产生费用,或者我在储存里面放了一大堆的数据,测试完全之后忘记了删除,过了很久,谁都不知道这个数据是干嘛的,谁也不敢删,谁都不知道这个数据删掉以后会不会影响其他的业务。但是这些资源一直产生的费用。直到财务人员发现你的消费比较高的时候,一般都会来踢你的屁股,说你部门成本怎么这么高?你要优化一下了。这个时候其实就已经是很被动了,为什么?因为这个时候我们去统计所有的资源,统计谁在用这些资源,这个流程是非常长的。我们可以通过主动的成本控制,去统计我们的资源使用量,实时去统计资源使用量,实时去优化。

我们看一个成本控制的样例。我们把实时的把账单数据导入数据中台,然后可以统计出来,我这个月到底花费了多少钱,预测这个月大概花多少钱,以及每一个云产品花钱的数量。还可以去看,过去三个月的趋势是怎么样的,以及每一个产品的趋势。或者根据我们过去的趋势信息预测我未来三个月大概要花多少钱,利用这个数字及时的去申请预算。
同时我们还可以在我们账单数据里面,根据统计信息看一下有没有一些异常的账单。比方说我在近三个月的消费曲线中,发现10月1号这一天账单发生了暴涨。我要抓出来到底是哪一个云产品产生了这么多消费?于是深入下钻到日志里面去分析,用刚才提到的根因分析的算法去找哪一个产品对一个消费的上涨贡献归最大,所以我们发现SLS这样一个产品,它的异常打分是最高的。那么我们就认为,这个产品出现的消费异常,及时的发出告警即可。
Summary

我们做一个总结,我们介绍了调查问题的一系列案例,通过这些样例展示我们如何借助于数据中台,帮助我们做数据驱动,以及借助AI做一些智能化、自动化的运维。通过这种数据驱动和智能、自动化的运维,整体提升我们的效率,减少我们被碎片化的时间。





