作者简介:陈毅能(苇度)毕业于中国科学院,曾任职于百度、微软亚洲研究院、华为、阿里巴巴等公司,专注于分布式数据库内核开发。
Recursive CTE (Common Table Expressions) 能够实现SQL的递归查询功能,一般用于处理逻辑上为层次化或树状结构的数据(如查询组织结构、物料清单等),方便对该类数据进行多级递归查询。与Oracle的CONNECT BY语法的功能类似。
在AnalyticDB for PostgreSQL 6.0版本中,Recursive CTE不再作为待验证特性,而是默认打开。可以通过参数gp_recursive_cte打开或关闭Recursive CTE,默认情况下,gp_recursive_cte是打开的。
show gp_recursive_cte;
gp_recursive_cte
------------------
on
(1 row)例子:1到100求和
使用Recursive CTE可以完成一些普通SQL语句无法完成的功能。使用Recursive CTE后,SQL语句可以引用它自己的输出。首先来看一个例子,计算1、2、……、100的和。
WITH RECURSIVE cte(n) AS (
VALUES (1)
UNION ALL
SELECT n+1 FROM cte WHERE n < 100
)
SELECT sum(n) FROM cte;
sum
------
5050
(1 row)上述例子中,CTE递归调用了自己,从而生成了1到100的序列,进而在主查询中进行求和。
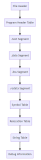
Recursive CTE语法及执行逻辑
使用Recursive CTE的语法如下:
WITH RECURSIVE cte_name AS (
non_recursive_term
UNION [ ALL ]
recursive_term
)
sql_statement;在recursive_term的部分,Recursive CTE对自身进行自引用。其整体执行逻辑如下:
- 执行non_recursive_term部分。如果是UNION,还需要执行一次去重。然后将数据作为本轮执行的结果,并将其结果放入一个临时工作表
- 如果这个临时工作表非空,则循环执行如下步骤。如果这个临时工作表为空,则返回所有轮的执行结果
(1)执行recursive_term部分。如果是UNION,需要去除重复数据,且要去除和之前结果重复的数据。然后将数据作为本轮执行的结果,并将其结果放入一个中间结果表
(2)将临时工作表的内容替换为中间结果表,并且清空中间结果表
在使用Recursive CTE的时候,需要确保执行结果是可收敛的,即总有一轮的执行结果为空,以结束循环,否则查询将出现无限循环。在前面1到100求和的例子中,有一个WHERE条件限制循环执行100步,数字达到100后因不满足WHERE条件,返回0行数据,循环终止,查询结束。
从上述执行逻辑看,Recursive CTE将对数据进行广度优先遍历。
例子:通过省市上下级关系表查询
建立省市上下级关系表:
CREATE TABLE city_relation
(
id int -- 当前省市id
, parent_id int -- 上级省市id
, name varchar(10) -- 当前省市名称
);插入省市关系数据:
INSERT INTO city_relation values( 2, NULL, '浙江省');
INSERT INTO city_relation values( 1, NULL, '广东省');
INSERT INTO city_relation values( 3, 2, '衢州市');
INSERT INTO city_relation values( 4, 2, '杭州市');
INSERT INTO city_relation values( 5, 2, '湖州市');
INSERT INTO city_relation values( 6, 2, '嘉兴市');
INSERT INTO city_relation values( 7, 2, '宁波市');
INSERT INTO city_relation values( 8, 2, '绍兴市');
INSERT INTO city_relation values( 9, 2, '台州市');
INSERT INTO city_relation values(10, 2, '温州市');
INSERT INTO city_relation values(11, 2, '丽水市');
INSERT INTO city_relation values(12, 2, '金华市');
INSERT INTO city_relation values(13, 2, '舟山市');
INSERT INTO city_relation values(14, 4, '上城区');
INSERT INTO city_relation values(15, 4, '下城区');
INSERT INTO city_relation values(16, 4, '拱墅区');
INSERT INTO city_relation values(17, 4, '余杭区');
INSERT INTO city_relation values(18, 11, '金东区');
INSERT INTO city_relation values(19, 1, '广州市');
INSERT INTO city_relation values(20, 1, '深圳市');查询浙江省及其下属城市列表:
WITH RECURSIVE cities AS
(
SELECT id, name, parent_id, name::text as path FROM city_relation WHERE id=2
UNION ALL
SELECT t.id, t.name, t.parent_id, c.path || '>' || t.name as path
FROM city_relation t JOIN cities c ON t.parent_id = c.id
)
SELECT id, name, path FROM cities;查询结果:
id | name | path
----+-------+----------------------
2 | 浙江省 | 浙江省
13 | 舟山市 | 浙江省>舟山市
11 | 丽水市 | 浙江省>丽水市
10 | 温州市 | 浙江省>温州市
9 | 台州市 | 浙江省>台州市
6 | 嘉兴市 | 浙江省>嘉兴市
5 | 湖州市 | 浙江省>湖州市
12 | 金华市 | 浙江省>金华市
8 | 绍兴市 | 浙江省>绍兴市
7 | 宁波市 | 浙江省>宁波市
4 | 杭州市 | 浙江省>杭州市
3 | 衢州市 | 浙江省>衢州市
18 | 金东区 | 浙江省>丽水市>金东区
17 | 余杭区 | 浙江省>杭州市>余杭区
14 | 上城区 | 浙江省>杭州市>上城区
15 | 下城区 | 浙江省>杭州市>下城区
16 | 拱墅区 | 浙江省>杭州市>拱墅区
(17 rows)引用
[1] https://gpdb.docs.pivotal.io/6-0/relnotes/gpdb-60-release-notes.html
[2] https://gpdb.docs.pivotal.io/6-0/admin_guide/query/topics/CTE-query.html
[3] https://blog.csdn.net/zengshaotao/article/details/84753796 (版权不明,互联网上可找到的发表最早的一篇)