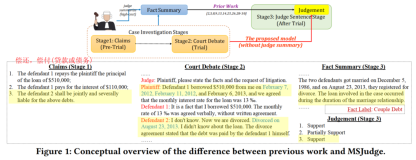
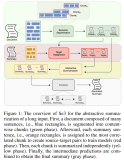
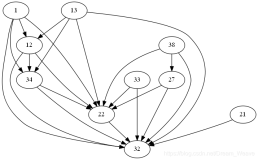
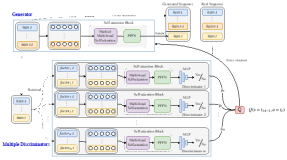
10000 小时法则
根据《异类-不一样的成功启示录》一书中的描述,要想在任何一个领域当中称为专家,都必须经过 10000 小时的刻意练习。具体的方法包括:
Chunk it up
将待学习的领域切分为细化的知识点。在数据结构和算法领域,必须掌握的包括:
数据结构
Array
LinkedList
Stack/Queue
PriorityQueue
HashTable
Tree/Binary Tree/Binary Search Tree
Heap
Skip List
Graph
Trie Tree
BloomFilter
LRU Cache
算法
递归
排序
二分查找
搜索
哈希算法
贪心算法
分治算法
回溯算法
动态规划
字符串匹配算法
Deliberate practicing
刻意练习。刻意地,反复地练习相关领域的知识点。在初期地时候,它可能带给你的直接感受是:不舒服、不爽、枯燥,但是只要能够坚持下来长期练习,必定能够获得成功。
Feedback
获得反馈。学习相关领域时,在获取反馈时需要注意如下的几点:
及时地获取反馈
主动型反馈(主动获取)
阅读别人写的代码(Github、Leetcode)
Gogole
被动型反馈 (等待高人给予指点)
Code Review
Big-O Complexity Chart
如下图,可以直观得看到不同的时间复杂度的渐进关系:
Common Data Structure Operations
下图展示了常见的数据结构中,对应的常见时间和空间复杂度:
Array Sorting Algorithms
下图展示了常见的排序算法的时间和空间复杂度:
All in one