原文:https://insidebigdata.com/2019/08/10/what-happened-to-hadoop-and-where-do-we-go-from-here/
Apache Hadoop出现在IT领域是在2006年,它可以支持使用廉价的商用硬件来存储海量数据。从某种意义上来说,Hadoop帮助我们迎来了大数据时代。希望越高,期待也越大。企业可以在称之为数据湖的基于Hadoop的存储中存储尽可能多的数据,并进行后续的分析。这些数据湖伴随着一系列的独立的开源计算引擎,并且基于此开源即意味着免费。那么会可能出现什么错误?
Monte Zweben,Splice Machine的CEO,对Hadoop将要发生的事情有一个有趣的看法,特别是对其垮台背后的三个主要原因:
模式读是一个错误
首先,所谓Hadoop的最佳功能竟是它的致命缺点。随着写模式限制的解除,TB级的数据结构化或非结构化的数据写入到数据湖中。由于Hadoop的数据治理框架和功能仍在设计,企业越来越难以确定其数据的血缘关系,导致它们对自己的数据失去信任,数据湖变成了数据沼泽。
Hadoop的复杂性和管道式的计算引擎
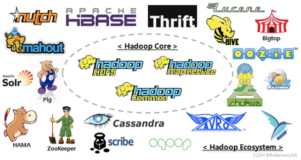
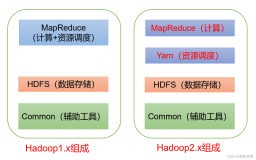
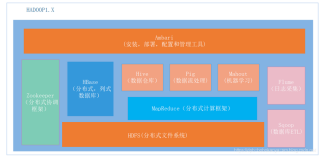
其次,Hadoop发行版中提供了一些列的开源计算引擎,例如Apache Hive,Apache Spark,Apache Kafka。这些计算引擎操作起来很复杂,需要专门的技术才能把这些技术串联起来,但比较困难。
错误的焦点 - 数据湖与应用程序
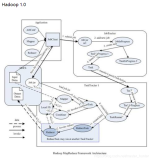
第三点也是最重要一点,数据湖项目开始失败,因为Hadoop集群往往成为企业数据流管道(过滤,处理,传输)的gateway,然后数据会转出到数据库和数据集市用于下游汇报,并且几乎从未在企业中找到真正的业务应用程序。结果,数据湖最终成为一组庞大的不同计算引擎,在不同的工作负载上运行,所有这些引擎共享相同的存储。这些很难进行管理。生态系统中的资源隔离和管理工具正在不断完善,但仍有很长的路要走。企业无法将注意力从使用数据湖作为廉价的数据存储库转移到使用数据和支持关键任务应用程序的平台。
许多组织都关注Hadoop生态系统的最新发展,并承受着展示数据湖价值的压力。对于企业来说,至关重要的是确定如何在Hadoop失败后成功地实现应用程序的现代化,以及实现这一目标的最佳策略。Hadoop曾经是最被炒作的技术,如今属于人工智能。当心炒作周期,有一天你可能不得不为它的影响负责。