MySQL从5.6到8.0并行复制的演进
一、MySQL的主从复制
1.1 主从复制基本原理
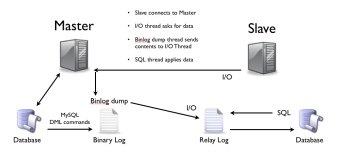
MySQL的主从架构依赖于MySQL Binlog功能,Master节点上产生Binlog并且写入到文件中。
Master节点上启动一个DUMP线程:当Slave节点I/O线程连接Master时,Master创建这个线程,DUMP线程负责从Master的binlog文件读取记录,然后发送给Slave。每个连接到Master的Slave都有一个DUMP线程。
Slave节点上启动两个线程:IO线程和SQL线程,IO线程从MySQL上拉取Binlog日志并写入到本地的RelayLog日志;SQL线程不断从RelayLog日志中读取日志并解析执行,这样就可以保证所有在主服务器上执行过的SQL语句都在从服务器上一模一样的执行过一遍。
1.2 复制延迟
复制延迟,指的就是一个事务在Master执行完成以后,要多久以后才能在Slave上执行完成。
由于对Binlog文件以及RelayLog文件的读写均为顺序操作,在生产环境中,Slave上的IO线程对Binlog文件的Dump操作是很少产生延迟的。实际上,从MySQL5.5开始,MySQL官方提供了半同步复制插件,每个事务的Binlog需要保证传输到Slave写入RelayLog后才能提交,这种架构在主从之间提供了数据完整性,保证了主服务器在发生故障后从服务器可以拥有完整的数据副本。因此,复制延迟通常发生在SQL线程执行的过程中。
在上面的架构图上可以看到,最早的主从复制模型中,只有一个线程负责执行Relaylog,也就是说所有在主服务器上的操作,在从服务器上是串行回放的。这就带来一个问题,如果主服务器上写入压力比较大,那么从服务器上的回放速度很有可能会一直跟不上主。既然主从延迟的问题是单线程回放RelayLog太慢,那么减少主从延迟的方案自然就是提高从服务器上回放RelayLog的并行度。
二、MySQL5.6的并行复制
2.1 MySQL5.6并行复制简介
MySQL从5.6版本开始支持所谓的并行复制,但是其并行只是基于schema的,也就是基于库的。如果用户的MySQL数据库实例中存在多个schema且schema下表数量较少,对于从服务器复制的速度的确可以有比较大的帮助。
在mysql5.6开启并行复制功能,SQL线程就变成了coordinator线程,那么coordinator线程主要负责两部分内容:
1.若判断可以并行执行,那么选择worker线程执行事务的二进制日志
2.若判断不可以并行执行,如该操作是DDL,亦或者是事务跨schema操作,则等待所有的worker线程执行完成之后在执行当前的日志
所以,coordinator线程并不是仅将日志发送给worker线程,也可以回放日志,但是所有可以并行的操作交付由worker线程完成。2.2 MySQL5.6并行复制存在的问题
基于schema级别的并行复制存在一个问题,schema级别的并行复制效果并不高,如果用户实例有很少的库和较多的表,那么并行回放效果会很差,甚至性能会比原来的单线程更差,而单库多表是比多库多表更为常见的一种情形。
三、MySQL5.7的并行复制
3.1 MySQL5.7并行复制简介
MySQL5.6基于库的并行复制出来后,基本无人问津,在沉寂了一段时间之后,MySQL 5.7出来了,它的并行复制以一种全新的姿态出现在了DBA面前。MySQL5.7中slave服务器的回放与master是一致的,即master服务器上是怎么并行执行的,那么slave上就怎样进行并行回放。不再有库的并行复制限制。
下面来看看MySQL 5.7中的并行复制究竟是如何实现的?
组提交:通过对事务进行分组,优化减少了生成二进制日志所需的操作数。当事务同时提交时,它们将在单个操作中写入到二进制日志中。如果事务能同时提交成功,那么它们就不会共享任何锁,这意味着它们没有冲突,因此可以在Slave上并行执行。所以通过在二进制日志中添加组提交信息,实现Slave可以并行地安全地运行事务。
Group Commit技术在MySQL5.6中是为了解决事务提交的时候需要fsync导致并发性不够而引入的。简单来说,就是由于事务提交时必须将Binlog写入到磁盘上而调用fsync,这是一个代价比较高的操作,事务并发提交的情况下,每个事务各自获取日志锁并进行fsync会导致事务实际上以串行的方式写入Binlog文件,这样就大大降低了事务提交的并发程度。
Group Commit技术将事务的提交阶段分成了Flush、Sync、Commit三个阶段,每个阶段维护一个队列,并且由该队列中第一个线程负责执行该步骤,这样实际上就达到了一次可以将一批事务的Binlog fsync到磁盘的目的,这样的一批同时提交的事务称为同一个Group的事务。
Group Commit虽然是属于并行提交的技术,但是却意外解决了从服务器上事务并行回放的一个难题——即如何判断哪些事务可以并行回放。如果一批事务是同时Commit的,那么这些事务必然不会有互斥的持有锁,也不会有执行上的相互依赖,因此这些事务必然可以并行的回放。
为了标记事务所属的组,MySQL5.7版本在产生Binlog日志时会有两个特殊的值记录在 Binlog Event 中,last_committed 和 sequence_number,其中 last_committed指的是该事务提交时,上一个事务提交的编号,sequence_number是事务提交的序列号,在一个Binlog文件内单调递增。如果两个事务的last_committed值一致,这两个事务就是在一个组内提交的。
为了兼容MySQL5.6基于库的并行复制,5.7引入了新的变量slave-parallel-type,其可以配置的值有:DATABASE(默认值,基于库的并行复制方式)、LOGICAL_CLOCK(基于组提交的并行复制方式)。
3.2 MySQL5.7并行复制存在的问题
在上文可以看到,MySQL主从复制的SQL线程回放在5.6实现了库级别的并行,在5.7实现了组提交级别的并行,但是在MySQL5.7中,基于Logical_Clock的并行复制仍然有不尽人意的地方,比如必须是在主服务器上并行提交的事务才能在从服务器上并行回放,如果主服务器上并发压力不大,那么就无法享受到并行复制带来的好处。MySQL5.7中引入了binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count两个参数,通过让Binlog在执行fsync前等待一小会来提高Master上组提交的比例。但是无论如何,从服务器上并行回放的速度还是取决于主服务器上并行提交的情况。
(关于MySQL5.7并行复制具体可参考之前的文章)
四、MySQL8.0的并行复制
4.1 基于WriteSet的并行复制
在MySQL8.0中引入了一种新的机制来判断事务能否并行回放,通过检测事务在运行过程中是否存在写冲突来决定从服务器上的回放顺序,这使得从服务器上的并发程度不再依赖于主服务器。
事实上,该机制在MySQL5.7.20版本中就已经应用了。MySQL在5.7.20版本引入了一个重要的特性:Group Replication(俗称MGR),通过Paxso协议在多个MySQL节点间分发binlog,使得一个事务必须在集群内大多数节点((N/2)+1)上提交成功才能提交。为了支持多主写入,MGR在Binlog分发节点完成后,通过一个Certify阶段来决定Binlog中的事务是否写入RelayLog中。这个过程中,Certify阶段采用的就是WriteSet的方式验证事务之间是否存在冲突,同时,在写入RelayLog时会将没有冲突的事务的last_committed值设置为相同的值。在MySQL8.0中,MySQL的并行复制引用了这种机制,通过基于WriteSet的冲突检测,在主服务器上产生Binlog的时候,不再基于组提交,而是基于事务本身的更新冲突来确定并行关系。
4.2 相关参数
在MySQL 8.0中,引入了参数binlog_transaction_dependency_tracking用于控制如何决定事务的依赖关系。
该值有三个选项:
COMMIT_ORDERE:表示继续使用5.7中的基于组提交的方式决定事务的依赖关系(默认值);
WRITESET:表示使用写集合来决定事务的依赖关系;
WRITESET_SESSION:表示使用WriteSet来决定事务的依赖关系,但是同一个Session内的事务不会有相同的last_committed值。在代码实现上,MySQL采用一个vector的变量存储已经提交的事务的HASH值,所有已经提交的事务的所修改的主键和非空的UniqueKey的值经过HASH后与该vector中的值对比,由此来判断当前提交的事务是否与已经提交的事务更新了同一行,并以此确定依赖关系。该向量的大小由参数binlog_transaction_dependency_history_size控制,取值范围为1-1000000 ,初始默认值为25000,该值越大可以记录更多的已经提交的事务信息,不过需要注意的是,这个值并非指事务大小,而是指追踪的事务更新信息的数量。同时参数transaction_write_set_extraction控制检测事务依赖关系时采用的HASH算法有三个取值OFF|XXHASH64|MURMUR32,如果binlog_transaction_depandency_tracking取值为WRITESET或WRITESET_SESSION,那么该值取值不能为OFF,且不能变更。
4.3 WriteSet依赖检测条件
WriteSet是基于主键的冲突检测(binlog_transaction_depandency_tracking = COMMIT_ORDERE|WRITESET|WRITESET_SESSION,修改的row的主键或非空唯一键没有冲突,即可并行)。在开启了WRITESET或WRITESET_SESSION后,MySQL按以下的方式标识并记录事务的更新:
如果事务当前更新的行有主键,则将HASH(DB名、TABLE名、KEY名称、KEY_VALUE1、KEY_VALUE2……)加入到当前事务的vector write_set中。
如果事务当前更新的行有非空的唯一键,同样将HASH(DB名、TABLE名、KEY名、KEY_VALUE1)……加入到当前事务的write_set中。
如果事务更新的行有外键约束且不为空,则将该外键信息与VALUE的HASH加到当前事务的 write_set中。
如果事务当前更新的表的主键是其它某个表的外键,则设置当前事务has_related_foreign_key = true。
如果事务更新了某一行且没有任何数据被加入到write_set中,则标记当前事务 has_missing_key = true。在执行冲突检测的时候,先会检查has_related_foreign_key和has_missing_key , 如果为true,则退到COMMIT_ORDER模式;否则,会依照事务的write_set中的HASH值与已提交的事务的write_set进行比对。如果没有冲突,则当前事务与最后一个已提交的事务共享相同的last_commited,否则将从全局已提交的write_set中删除那个冲突的事务之前提交的所有write_set,并退化到COMMIT_ORDER计算last_committed。
在每一次计算完事务的last_committed值以后,需要去检测当前全局已经提交的事务的write_set是否已经超过了binlog_transaction_dependency_history_size设置的值,如果超过,则清空已提交事务的全局write_set。从检测条件上看,该特性依赖于主键和唯一索引,如果事务涉及的表中没有主键且没有唯一非空索引,那么将无法从此特性中获得性能的提升。除此之外,还需要将Binlog格式设置为Row格式。
五、总结
在MySQL8.0中,开启了基于WriteSet的事务依赖后,Slave上的 RelayLog回放速度将不再依赖于Master上提交时的并行程度,使得Slave上可以发挥其最大的吞吐能力,这个特性在Slave上复制停止一段时间后恢复复制时尤其有效。
这个特性使得Slave上可能拥有比Master上更大的吞吐量,同时可能在保证事务依赖关系的情况下,在Slave上产生Master上没有产生过的提交场景,事务的提交顺序可能会在Slave上发生改变。虽然在5.7的并行复制中就可能发生这种情况,不过在8.0中由于Slave上更高的并发能力,会使该场景更加常见。通常情况下这不是什么大问题,不过如果在Slave上做基于Binlog的增量备份,可能就需要保证在Slave上与Master上一致的提交顺序,这种情况下可以开启slave_preserve_commit_order,这是一个5.7就引入的参数,可以保证Slave上并行回放的线程按RelayLog中写入的顺序Commit。