小叽导读:在时间就是金钱的时代,降低搜索时间成本,迅速找到目标产品具有重要意义。如今的电商平台已不仅仅是一个摆放商品的货架,“智能推荐”成为电商的一个重要功能。今天,我们来看看强化学习是如何帮助用户与平台实现互动,让用户在商品的海洋中迅速找到心仪的“它”。
交互搜索简介
智能交互搜索是一种新型的购物搜索方式,用户可以在搜索中同时与系统进行交互,我们希望可以在与用户的交互中提供帮助用户决策的信息。大致包含以下几种维度:
细化需求:用户购物需求比较确定的情况下,系统会推荐有助于细化决策的维度,比如“耳机”的Query下,系统会让用户选择“佩戴方式”,帮助用户更快成交。
探索发现:解决逛和发现的需求,在发现用户不是购买意图下,推荐一些发散的Query。
知识问答:解决用户之前通过第三方网站了解购物知识,然后来淘宝直接搜索商品的问题;提供一些知识解释;最终希望引导用户在淘宝能流畅完成购前找买什么,购买和购后分享的整个链路;
某用户Session数据如下:
初始Query为“无鞋带 男鞋”,Agent给用户推荐了“颜色分类:红色、白色、黑色、灰色”,
用户选择了“销量排序”
用户选择了“黑色”,Agent给用户推荐了一些发散性Query“发现:皮鞋男、板鞋男、鞋子男、小白鞋男、布鞋男、帆布鞋男、休闲鞋男、豆豆鞋男、t恤男”
用户“翻页”
用户选择“小白鞋男”,Agent同时给用户推荐了“鞋头款式:尖头、扁头、圆头”
用户点了“尖头”
用户点了“圆头”
...
产品形态如下图:

问题定义&相关工作&建模
问题定义
在当前问题中,我们希望可以让用户尽可能多的和系统交互。更多的交互意味着更多的pv,增加用户的停留时间和粘度,pv增加也会提高广告的收入。在智能语音交互方面,微软提出了一个统计指标——CPS,即人类与人工智能“聊天机器人”的对话轮数。据微软统计显示,目前小冰的CPS是23左右,而Siri、Google Now 等以智能助手为目的开发的人工智能引擎,CPS往往都不超过3。本文我们也采用这个Matrics作为优化目标。
当然我们也可以把这个问题看做一个Task Oriented Dialog System,让用户以最少的交互次数完成购物,目前我们把目标设定为前者。
强化学习在交互搜索场景的意义
强化学习work的场景必须有明确的delay reward,典型的有棋类游戏中的放弃当前子来获取全局的优势,竞技类游戏比如dota2中英雄放弃补刀的金钱收益去选择gank、打肉山,强化学习擅长建模在序列决策中存在delay reward的问题,即放弃当前局部最优的决策来获取更长期的收益。
交互搜索系统对用户的反馈是典型的序列决策过程,有时需要放弃当前最高收益,在这个问题中,如果我们的优化目标是整体的CTR,比如在耳机的搜索场景中,有两个维度(品牌),(佩戴方式)可以在context下用于决策,用有监督的方法我们学到的是当前context下的最优选择,为下图Greedy的思路,这时我们学到的是“首次展示品牌”更好,而实际上,如果我们调换品牌,佩戴方式的出现顺序,虽然我们首次决策不是当前状态下最优的,但序列决策下的期望却是最优的。

相对RL应用较成功的游戏、棋类、机器控制领域,对话交互系统对“终止”的定义比较模糊,在闲聊机器人中可以定义为用户退出,在交互搜索里用户的意图切换是否定义为终止就与任务相关,如果是希望用户增加PV,我们可以整体交互的退出作为终止,如果希望在细化类目做进一步导购直到成交,终止则定义为退出或切换意图。

强化学习在任务型对话的一般思路
DM经典的做法是把问题看成一个槽填充问题,在2007-2013,基本做法是定义好一个任务,并拆分为一系列的槽(slot),在对话交互过程中进行填充。而这种方法的最大问题在于:错误传递,上游错误会传递到下游导致下游直接错误,比如NLU或DST的某步骤出错,会直接导致DM输出错误的Action,而且几乎无法修正。而端到端的方法可以做到一定程度的纠错,基本思路为首先监督方法训练,然后用深度强化学习调参(样本为真实用户)。比较代表性的工作有是Bing Liu在17年nips的文章,结构如下,优化同时考虑的slot filling和action。

交互搜索基于强化学习框架的建模
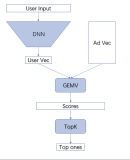
我们用强化学习的框架来对交互搜索场景建模。其中智能体(agent)是我们的服务进程。环境(env)是用户和平台的其他因素。具体地,用户首先提交query,例如“手机”。agent选择该类目的某个属性,例如“品牌”。页面展示“品牌”的具体取值,例如“华为”,“小米”等。用户可能会选择/取消某个属性值,也可能直接翻页,这些操作都会跳转到下一个PV。agent与env不断交互直至用户退出会话,构成一个episode。
我们记t时刻env给出状态,agent做出动作,env根据内生的动态,反馈给agent奖励并跳转到状态。强化学习旨在为agent搜索最大化期望累积奖励的策略。
在交互搜索场景中,我们将状态,动作,和奖励定义为:
1、状态设计:State的设计要考虑两点,当前State足够学到合适的Action,以及用户与环境交互的过程State要有明显变化去学Q函数,这里我们考虑了以下几个方面:
User State:包括用户的性别、年龄、购买力。
User History、Agent History:类目、页码(用户翻页)、用户点过的tag、Agent推荐过的tag。
Query State:DST后Norm Query做Embedding(取语义粒度分词后embedding的均值,当然这里也可以考虑用self-attention的方式考虑语义贡献,但目前的数据量下我们没有这么做)作为当前的query state。
Tag静态分:Query-Tag Score,User-Tag Score等。:包括用户信息(性别、年龄、购买力等)和会话信息(类目、页码、query、用户操作记录等)。
2、动作:某个类目属性,例如“品牌”, “裤型”, “材质”等。动作空间是所有合法的类目属性。
3、奖励:如果用户没有离开,否则。这样设计是因为最大化累积奖励等价于目前的业务目标,即尽可能增加交互轮数。
此问题的难点在于,所有类目属性的个数约有200K,即动作空间的大小为200K(类目*维度),这势必导致搜索空间过于庞大,难以求解最优策略。另一方面,每个商品类目平均有约15种属性。这个动作空间的规模虽然可以接受,但是我们共有约1500种类目,如果分别训练1500个agent,因为头部类目与尾部类目所拥有的流量严重失衡,所以用机器学习的方法很难为尾部类目训练得到性能可观的agent。
我们注意到不同类目所拥有的属性集合是有大量交集的,例如“连衣裙”和“裤子”都有“材质”这一属性。同一属性对于不同类目来说,意义往往是无差别的。例如”品牌“是重视品质,在乎品牌赋予同质化的商品的附加意义的用户会倾向于选择的属性。基于此,我们通过共享模型参数(User History、Agent History、Action的embedding),联合训练(多任务)各类目的agent。具体模型如下,另外一次输出这么高维度的打分向量显然是过度计算了,所以这里我们根据类目对Action Space集合做了一个Mask,只对当前类目下考虑的Action打分,对最后的的计算我们采用了对Action做打分:

系统
我们基于PAI TF,使用Ali AI Agent(简称A3gent)强化学习组件实现的DQN算法来求解最优策略。
我们的神经网络的输入层包含多路输入,且不同通道的状态分别有sparse/dense,定长/变长,数据的类型包括int, float, string多种类型。A3gent支持多路状态输入,每个通道的数据类型及形状均可配置。
除了需要处理多路输入,我们的神经网络结构也较为复杂,包括embedding layer,fully connected layer, concatenation layer。另外,考虑到其中一路状态是agent在当前episode推荐过的属性集合且我们的动作空间正是属性集合,我们让output layer与embedding layer共享参数。即对于属性P,它的embedding向量会作为该P对应的output neuron的参数:,其中h表示output layer的输入。
由于不同类目的agent共享模型参数,所以每个类目的agent的策略不能平凡地做一次forward。由于状态包含一个通道为类目的ID,记为c,我们首先根据c查询类目到属性列表的词典,找到c所对应的合法属性集合。再根据Q值大小贪婪选取动作:
A3gent组件中已经将上述逻辑通过计算图表达,对于使用者不存在于普通forward的区别。
由于强化学习需要agent与env交互的过程中在线更新,且基于QP的服务进程无法实现模型的训练,所以我们采用基于PAI TF的准实时训练策略:

训练
数据:

我们首先用历史数据做预训练,预训练的结果基本可以学到线上的策略,作为模型的初始参数。baseline(top5的维度random,所以random的结果也不差)对比,从Query级别点击率来看DRL离线可以带来1.9%的提升(后面我们也分析了,当前的Reward设定其实并不能显著提升CTR),而基于统计ensemble的版本有6.8%的提升。同时分析了不同策略下对全局指标的影响,人均pv/uv降低0.5%,一个大Session内的平均交互次数增长0.16%。具体如下:

针对这个结果,我们认为DRL只是在统计+random生成的样本上做了一轮训练,而DRL需要与环境进行交互,用当前策略(on-policy)去产生训练数据,目前基于统计ensemble的版本用到了大量主搜数据,所以效果会比较好。基于目前的分析,我们尝试了准实时训练,数据生成部分我们做到实时解析,在porsche产生实时数据(pvlog),目前拼一个完整的EPISODE给模型训练,需要拿到用户退出的操作,而我们的数据量较小,需要三小时才能产出足够的样本,所以为了快速验证效果,这一步目前我们是通过小时级离线解析,然后用PAI去训练模型。我们也开发了一个实时Matrics,实时监控小时级别的CTR和小时级别的平均CPS(平均交互次数)。
线上部署
DII(一个算法在线服务平台)在升级到0.33版本后内置了Tensorflow模型预测功能,我们测试性能是可以满足需求的。在模型更新部分,DII服务会在扫到模型文件切换index后重新加载模型,目前唯一的缺点是,没法做到实时,实测1.4G的模型文件从产出、build、切换索引到生效大约需要半小时。我们的场景中,目前流量下,Replay Buffer积累数据也需要小时级,所以这部分暂时是可接受的。
ps:目前想实时生效只能通过写DII增量,在DII的process里自己实现Inference,考虑到我们的更新频率、以及模型切换后的开发成本,我们暂时没有这么做。目前是采用定时调度的形式实现的。

结果
评价方式
RL在离线的评价一直是一个问题,因为传统的AUC都是基于当前context下有监督的最优,一般评价的方式有:
模拟器:根据真实数据产生一个Env的模拟器,可以与训练的Agent进行交互,用平均Reward评价。这对打游戏十分有效,比如gym里的各种环境。在淘宝中也有很多模拟器的项目,我们下一步也会考虑通过模拟器的方式快速迭代算法,比如对话系统模拟器。
人工测试:采用人工的方式与系统进行交互,统计平均Reward,这种方式人工反馈的量是比较有限的。
线上测试:直接与真实环境进行交互,然后统计随时间变化的平均Reward,这种测试方式需要真实环境有大量交互行为,我们也采用了这种评价方式。
线上效果
训练后的CPS相对ensamble的版本有明显提升。在新的交互系统中,用户平均交互次数提升了1.5次,提升30%+。
Tag的CTR并没有明显提升,这里我们也分析了原因,目前的Reward设定其实不一定展示给用户的是点击率最高的,比如我们可能会出一个不是当前context下点击率最高的Tag,但这个Tag点击后的商品对用户满意度最高,用户会更多浏览,这也会增加与系统的交互次数。
总结与展望
基于强化学习的Task-oriented Dialogue System已经在客服领域、医疗诊断等领域取得了巨大成功,前者可以节省大量人力成本,帮助用户快速完成任务,后者则有望基于有经验的医疗诊断数据,解决医疗资源不均的问题。
在商品导购领域,消费者完成一笔订单,用户通常会经过与销售客服交流,自己查资料,到决定购物的决策过程,在淘宝海量购物数据中,我们希望可以挖掘出“购物老司机”的购物路径,并且在合适的时机给用户“有决策价值的解释”,给消费者更好的导购体验。本任务中,Action Space极大,相对于传统的Task-Oriented Dialogue订机票、订餐、医疗的任务,我们的Action Space包括确定当前的系统动作,如:商品属性的选择、内容解释等,确认了动作后还要对具体动作的值进行排序,如果候选空间有m个动作,有n个是需要排序展示的,那么动作空间会是维。这个量级的Action空间,对于学术界和工业界都是巨大的挑战,我们目前只是做了其中的一层,动作空间有百万维。
本问题是一个典型的多层决策问题,是否可以设计更好的HRL方式,更全局的考虑全局的收益?此外如何在有限的样本中做信息共享?如何在真实线上环境中做高效率的探索?如何够早一个合理的“experience replay”使online learning更“稳定、快速、有效”都是接下来要研究的问题?
参考文献
1.End-to-End Optimization of Task-Oriented Dialogue Model with Deep Reinforcement Learning
2.A network-based end-to-end trainable task-oriented dialogue system
3.Learning end-to-end goal-oriented dialog
4.A copy-augmented sequence-to-sequence architecture gives good performance on task-oriented dialogue.
5.An end-to-end trainable neural network model with belief tracking for task-oriented dialog.
6.End-to-end task-completion neural dialogue systems
7.Iterative policy learning in end-to-end trainable task-oriented neural dialog models
8.Hybrid code networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning
9.Towards end-to-end reinforcement learning of dialogue agents for information access
最后,如果你对智能交互、自然语言处理、语义搜索、强化学习、深度学习感兴趣,欢迎加入我们团队!如果你是非应届毕业生,希望在真实场景数据下实现算法,我们有大量research intern名额,以上职位有意向都可以发送简历+意向岗位到:guren.xf@alibaba-inc.com,期待你的加入。