当业务炸裂式增长,如何让关系型数据库平滑扩展?
爱奇艺、饿了么、摩拜单车…这些国民级应用的疯狂增长背后,是怎样一款国产的分布式NewSQL数据库,在做平滑支撑?
对话内容
选型宝:您怎么理解数据库技术的发展历程,分几个阶段?
黄东旭:其实整个大的背景大概是这样,上世纪六七十年代就有关系数据库概念了,一直发展到90年代,基本都是以IBM DB2、 Oracle,微软的SQL Server等单机关系型数据库为主的行业现状。
但是在2000年以后,随着互联网行业数据量爆发性的增长,同时最近这5-10年移动互联网的兴起,使得数据量在传统互联网之上又大了一个数量级。我觉得未来在5G包括IOT的时代,可能又会比现在的移动互联网又大一个数量级。所以在互联网蓬勃爆发的阶段,这些互联网公司第一次遇到了大数据的问题。
但是传统的关系型数据库都是一个单机的架构,无论怎么搞,它的弹性伸缩能力其实都是没有的,在这个背景下,在互联网行业里面诞生了NoSQL数据库,就是放弃掉SQL的模型,放弃掉一致性的事务,去换取弹性,通过简单的增加机器,就可以承载互联网的业务。比如说像Twitter、微博,它放弃掉了一致性,对于用户来说,我的业务很简单,就算少看一条微博,丢了,也无所谓,因为不是交易数据。
但是,今天很多业务不仅仅是微博这种形式,那可能也有交易,比如有一些像饿了么订单那样,订单,就不允许发生任何的丢失。谷歌第一个遇到了这样的问题,他们觉得NoSQL没有办法满足广告系统,钱包,这些跟钱有关的业务,数据不能出错,所以他们尝试有没有办法把传统SQL一些好的东西留下来,兼具 NoSQL 扩展性,又不丧失传统关系型数据库 ACID 特性。
另外,有一些分析的场景,比如说我们做了一个活动,想去了解一下活动的效果什么的。如果你在NoSQL上其实很难做这种复杂的分析。比如说对于数据分析师来说,我写几行SQL代码可以做复杂分析,但是如果你是在一个NoSQL系统上,其实你很难做这个事情。
所以现在大家渐渐的发现:我的业务用SQL写还是更方便一点,但是我的扩展性如果是用传统的单机数据库又没法满足需求,所以我们现在在尝试去做的一个事情就是把这两者的好处结合起来,做一个新形态的一种关系型数据库来去服务用户的需求。
我们为什么要从零开始,去完整实现一个NewSQL?因为是这样的,我个人觉得过去这种传统的单机数据库,你也想把它发展成一个通用的分布式数据库,其实这条路是很难走的通的。因为你无论怎么做,你的根基还是一个单机数据库,你无非就是在上面去做一些数据路由层或者说数据分片,仍然还是一个没有去触及本质的修改。
但在TiDB这边,我们其实就放弃了这条路,是从最底层开始去自己构建一套完全面向未来的一个架构,面向未来的这种分布式环境新的一个数据库。所以,你可以认为 TiDB 是从最底层开始,面向分布式场景去做的一个东西。
选型宝:TiDB的整体架构是怎样的?
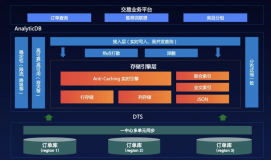
黄东旭:这里有一张TiDB的整体的架构图,因为本质上来说TiDB自己就是这种集群的形式,也就是说这个系统里面没有任何一个单点,它是可以完全做水平扩展。我简单展开一下,TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件,本身它自己也是微服务的一个思想的实现 。
PD Server
红色这个部分就是叫PD的一个小的Cluster ,叫Placement Driver 是存储整个系统原信息的一个模块,你可以认为有点像Hadoop里面的Zookeeper,或者说有点像etcd这样的原信息管理服务。
TiDB Server
绿色这部分是狭义上的TiDB Server,它其实是一层无状态的一个SQL解析层,其本身并不存储数据,只负责计算。你的业务层MySQL的客户端可以连接到任何一个TiKV Server 的实例上,都是一模一样的。所以当你在有海量并发过来的时候,你其实可以连接到任何一个TiKV Server的时候去承载。
TiKV Server
实际上数据的存储是会存储在中间这部分蓝色的叫TiKV的一个组件上。TiKV顾名思义KV,其实它内部本质上是一个Key-Value形式组织的一个分布式数据库,所以TiDB Server这边在做的事情,就是把用户的一个SQL的请求跟表结构这些信息,转换成在TiKV这种分布式的Key-Value的存储,然后把它这个存储下来。这一部分是真正数据存储的位置,同时它是可以做弹性的伸缩、水平扩展,然后分布式事物都是在这一层的这个基础上去实现的。
TiSpark
大家可能会好奇,另外这一块×××部分是什么部分?
其实最早期在TiDB去设计的时候,只有上述三个大的模块。就是说用户把这三个模块组合在一起,当做一个大型的一个MySQL去用着。 但后来有很多用户发现我的数据量在TiDB里面存储的越来越大,几十台甚至上百台机器在去存储数据。
用户就想要在上面去做一些数据分析,在过去传统的方案上,你必须得把数据库里的数据给搬到Hadoop,或者说放到一个离线的数据仓库里才能做分析。但现在用户就在想,TiDB本身不就已经是一个分布式的存储了吗?那我能不能直接拿spark在我这个东西上面去做分析呢?
这块×××的部分就是我们有一个叫TiSpark的项目,它是spark的一个插件。它把TiDB的一些表结构信息、把一些数据的分布信息,包括我们那些索引信息暴露给spark的执行引擎,能够让spark直接把计算逻辑下推到存储节点上去,做高效的聚合和复杂的分析型的计算。
甚至有些用户是这么用的:这一边用着MySQL去实时的写入,然后马上在这边就用的Spark SQL在同一份数据上去做实时的分析,其实这是一个HTAP的概念。
大体的架构大概是这样。每一个具体的模块里边也都是没有单点的这样一个设计,所以一是它能够很好的去支撑扩容,简单添加TiKV的物理节点就增加了。
如果你的网络流量或者计算能力不够,那你直接添加绿色的部分。你的DBA也不用去重新调整分片,也不需要去重新设计你的路由规则。加一台机器,晚上要回家睡觉了,第二天这个系统自动的就扩容扩好了。
选型宝:能不能给我们分享几个生产环境的案例,讲讲他们是怎么用的,用在什么场景下?
黄东旭:
类型1:OLTP型的应用 ( 支撑了微信12宫格里80%的应用)
其实我想分享几个比较大规模,或者说我们这边觉得比较代表性的几个用户。 第一类应用,你可以认为是纯OLTP型的应用,我可以举几个例子,一个是大家知道现在有一个很火的电商公司叫转转,它有点像闲鱼,是58下面的一个二手交易,它入驻的微信的十二宫格。
它其实内部是 ALL IN TiDB的状态,它过去老的方案是各个业务线,各自的一个个MySQL,很传统的一个方案,同时还有一部分MongoDB。但是后来发现,随着入驻微信的十二宫格,业务量的暴涨,他们发现MySQL在不管是高并发压力下延迟的抖动,还有扩展性,其实都没有办法很好地满足它的业务快速增长的要求。
在这种背景下,他们采用了ALL IN TiDB的策略,目前他们内部已经上线了十几套OLTP型的TiDB,包括他们的订单系统,电商商品介绍等这样的系统,还有他们最核心的IM系统,就是聊天系统。因为二手交易的一个特点是,买家在下单之前一定要跟卖家聊天的。所以如果聊天系统出现问题,那这个直接会影响到订单量。 聊天的IM表上,他们的设计规模是单表是上千亿条级别。
除了性能和扩展性,TiDB内置的这种两地三中心加上高可用的特性在里面,比如说任何一台物理机宕机了,对整个业务层其实没有任何影响的。
相比于NoSQL 数据库,TiDB的另外一个优势是,它可以让我们不改变平时用 MySQL 的操作习惯,这也是非常吸引转转的地方。
除了转转,我们统计了一下,在微信十二宫格里面80%的应用,也就是基本上有七八个格子里边的应用,背后其实都是由TiDB在执行。
类型2:搭建大中台
另外一个比较有意思的场景是大中台型的业务,过去电商公司,或者说一些大的互联网公司都会特别头疼的一个问题,就是多条不同的业务线,一个个的垂直去划分,每个业务线自己用自己的数据库。你会发现企业缺少一个实时的大中台,能够把不同的业务之间的数据汇总打通。
其实这是一个很大的问题。比如说公司老板,说我今天就要看某某数据,比如说某一个实时销售数据,或者说我要去跟另外一个表去撞一下,去做出一些个性化的一个报表,这个过程会很麻烦。
如果能有一个中间的数据中台,实时的跟多个数据孤岛之间把数据同步给做起来,你在这一层面上变成特别大的一个关系型数据库的数据池子,你就可以很方便地去做这种跨业务、跨分片的复杂的查询。
TiDB是可以直接作为MySQL的从库,它会伪装成MySQL的一个从库去实时地同步线上MySQL主库的数据,因为TiDB是MySQL的语法层面上都兼容的一个数据库,所以我们同时也能直接去同步它的binlog来把数据打通进来。
过去MySQL DBA经常说的一句话就是一主多从,一主挂多个从,现在在TiDB架构里面正好反过来。多主联到一个从,多主一从,数据自然就汇总了。
刚才说的这个大中台案例是同程旅游,同程旅游其实也是微信十二宫格应用中的一个。
类型3:金融级别多数据中心多活
随着 TiDB 的逐渐成熟,TiDB 也已经开始应用在传统金融行业的核心应用,最典型的就是某商业银行,采用了 TiDB 作为在线支付业务的核心数据库。一是使用 TiDB 实现跨三中心的多中心容灾多活核心数据库集群;二是使用 TiDB 承担包括核心网联支付/银联无卡支付业务,支付对账,核心批量作业等一批核心交易应用。
我觉得这个案例,对我们来说更是一个里程碑的意义,并不是说业务量有多大,说实话可能它也没有今日头条的那个系统这么大。但是它的意义就是说可靠性,基本是得到了银行这种金融行业的认可。
刚才我说了几点,我再稍微总结一下:
第一就是海量数据、高并发+弹性扩展的这种互联网的场景
如果你发现你的MySQL,或者说你在内部业务MySQL开始需要分库分表,同时你的业务和DBA都非常不爽,两边都不爽,想到TiDB。
第二个就是你希望去做一个实时的数据中台
用最低的成本、最小的技术栈,去实现数据中台,可以去选择TiDB。
第三个就是说如果你有一些真正的两地三中心、多数据中心多活的金融级别场景
那你也可以去放心的选型TiDB,因为至少已经有很多之前的这些客户已经在上面积累了足够多的经验。
所以我觉得这几点,是TiDB现在来说比较擅长的,而且因为TiDB是兼容MySQL的,所以易用性来说,就是说如果你的应用已经是基于MySQL开发的,你不需要做很大的改动。
选型宝:你们是从解决关系型数据库扩展的问题切入,当然,您刚才也提到了这样一种架构,为客户带来很多方面的价值,请您总结一下,TiDB分布式的架构,为用户带来的价值,体现在哪些方面?
黄东旭:首先,我觉得扩展性是对于这种新型分布数据库的一个及格线
这是一个基础。现在这个年代你再做一个单机型的数据库,其实没有什么太大意义。
第二点其实刚才也说了,构建融合交易和分析的数据平台
我们最开始在做TiDB的时候,我们只是想简单的去做一个MySQL在大数据量下的一个替代方案、扩展方案,但后来发现用户在这么大数据传过来以后,下一个很自然的想法就是说我在上面做分析,我能不能挖掘出一些新的数据价值,我已经是一个分布架构了,我可以给你去提供复杂分析的能力,所以你可以认为我们的这个方向是从可扩展的OLTP的传统的关系数据库切入,慢慢的去补强我们的分析能力,往分析的上面去加强。
TiDB项目现在的打算,就是我们会慢慢的去模糊数据库跟数据仓库,交易跟分析中间的这个界限,就慢慢的会变成一个融合的平台。对于用户来说,我以后看到就是一个数据平台,然后对外的这个接口,对于你的业务开发人员和数据分析师的接口就是SQL,你可以在上面去做事务,你也可以在上面去跑分析。
第三点,面向未来IT环境、屏蔽底层复杂性,支持业务创新
我们其实想,未来随着这个数据量越来越大,分布式的架构会越来越普及,你作为程序员来说,你不用像现在我要去搞这一个分布式系统,不需要去关心我要买多少台服务器,我的服务器要部署在哪,我的数据该怎么分布,我要用多少种不同的存储引擎,都不需要关心。
就是以后大家再去做这个业务的时候,你只需要来关心你的业务的逻辑开发就好了。所以其实我们在这一块来说是希望能够把简单留给客户,把复杂留给自己。
其实这一点来说,这跟云的思想是不谋而合的。大家知道一个企业或者说一个基础架构,现在大家都想在上云的这个过程,云的一个大核心思想,就是我的各种资源,我的Iaas层尽可能的透明化,你看不见,通过弹性伸缩的能力来去使用这个云的平台。
所以我在设计TiDB的时候,里面的一个很重要的设计理念,就是这个数据库应该是拥有自我愈合,自我修复,自我疗伤的能力的,这个可能就像人一样,我划伤了一下没关系,自己会长好,这个其实是面向未来海量数据的时代,怎么去构建一个真正高可用的一个系统,要考虑的一个东西。
同云的理念一样,今天,要支撑业务创新,关系型数据库领域也需要有新的架构,屏蔽底层的复杂性,把复杂留给自己,把简单留给用户。
选型宝:刚才您提到关于云的问题,TiDB对云的支持上有什么样的一些策略?
黄东旭:目前来说TiDB发布了 TiDB Cloud ,同时我们最近刚刚登陆了谷歌云的平台(GCP:Google Cloud Platform )。
在云这一块,我先说技术上我们是怎么去思考的,我们相信未来的数据库一定是跑在云上,不管是公有云也好,还是私有云也好。云会变成新的操作系统,我们的分布式数据库会成为操作系统上的一个服务。
所以,什么样的云的基础架构会变成通用的一个解决方案?我这边是更相信就是K8S,这套基于容器的调度框架。其实TiDB现在的思路,我不会去跟某一个具体的云厂商,或者某一个具体的云的解决方案去做对接,我会把整个TiDB的自动化的多租户运维、部署,各种各样的这种DBA原来是要手动去做的事情变成代码,然后注入到K8S里边,让K8S去学会怎么去调度TiDB集群。我相信未来不管什么样的云平台,包括私有云也好,公有云也好,一定会去提供基于K8S的这套云的方案。
选型宝:接下来谈一谈开源的问题,你们从一开始,就选择把自己的产品开源出去,来构建生态,这种选择,是基于怎么样的考量?
黄东旭:我自己有一个理念,当时我们去做Codis项目的时候,你知道Codis也是很流行的开源项目,现在很多公司也在用。当时让我有一个深刻的体会,其实我们做Codis这件事情也就几个人做了几周的时间,它开源出去产生的社会价值、产生的影响力,远远超出闭源软件。
我当时在想,开源一定是一个更好的传播的方式,开源也是更好的软件开发的模式、成熟的模式。
TiDB从写第一行代码开始,到现在也就差不多不到4年的时间,你能想象才4年的一个新项目的成熟度已经达到可以直接应用在银行的核心交易系统里面?如果是一个闭源软件的话,我觉得肯定是不可能的。
选择开源,极大的加速了TiDB的成熟的进程。两三年前,大量的早期的用户通过开源社区会给我们反馈,比如用在这个场景下,它可能有什么地方能改进,我在用到这个场景下你这边有个bug,社区会不停地反馈给你东西,把我们推着往前走。
另外一块,社区帮我们看见很多我们自己想不到的东西,比如说一开始我没想过要做HTAP,但是很多用户就是这么用的,有了需求,我才能看到这个需求。
所以要构建一个通用的产品,特别是基础软件产品,这一点我是这么认为的,就是用你的人越多,你的这个东西的成熟度就越快,这样的话,你跟闭源软件去竞争的时候,你永远是有这个优势的。
所以,我觉得一个活跃的开源社区,会带来持续的竞争力。很多人觉得你不是开源吗?我拿你的代码过去再自己去包装一个产品,但你仔细想其中的区别,相当于是一个有生命的跟一个没有生命的,在这边天天都在进化,很有可能一年以后你的这个产品跟以前有天翻地覆的差别。
选型宝:关于开源社区里面的人才的培养,这块有没有什么策略?
黄东旭:其实这也是我们从今年下半年开始在去做的一个很重要的战略。对于PingCAP或者TiDB来说,因为现在使用TiDB的公司越来越多,使用TiDB的程序员,或许他会有很多主动的想法,我能不能更深入的去掌握我现在每天在使用的TiDB的产品,包括通过选型宝这边,我要去使用TiDB的时候,我应该具备什么样的一个知识储备,我能不能有一些在线的学习资料,让我深入的去学习。
所以,我们开始推出了一个面向企业培训的系列课程,大概是一个3到5天的课程,比如说你做为一个企业,你可以派你的DBA过来,我们会有一整套的线下的讲师培训,还有上机的操作,一个技术的演练、考试,最后学完这一套培训的课程以后,会给你一个我们这边TiDB委员会认证的一个证书,然后持证上岗。
你如果要用TiDB的话,出了问题,你肯定是希望第一时间自己能够去解决,我也希望你能够第一时间去解决,所以我们推出面向公司培训的这个系列课程,你可以直接去买课程,不用考虑买软件,你就买课程,学会了你自己去可以很好的使用,现在去购买我们的课程,可能直接会帮你送我们原厂的几次应急响应救援服务。
所以总体来说,我还是希望能够让渴望去更深入了解TiDB的社区的用户,能够有一个渠道,手把手的教,这样对生态来说,是一个好事情。
关于TiDB DBA 官方培训认证计划,详情可以了解这篇文章
选型宝:当客户决定用TiDB的时候,他一般会经历怎么样的一个切换和迁移的过程?
黄东旭:其实这里分两种情况考虑,比如说你现有的系统已经是基于MySQL在开发了,现在遇到了一些容量上或者说并发上或者数据量上的一些问题,这个时候可以分两步走:
第一步,就是你可以用原生的MySQL这个数据导入导出工具,先把数据导到TiDB这边试一试,因为是这样,本身TiDB是兼容MySQL的,这样你在线上去观察你的业务,能不能正常的跑,包括像做一些灰度的流量的切过来,跑到TiDB上看行不行?
第二步,你就会发现,你不希望再去用上面MySQL的这个主库了,那你直接就把这个业务切上来就OK了。
其实这是典型上线过程,摩拜当年就是这么上线的,先把它作为一个MySQL的一个备机,先挂上面,看看写入、并发、压力、查询、兼容性,没什么问题后,切上去,这种MySQL的业务迁移是很简单的。
但是还有一些更传统的用户,比如说像oracle像DB2这样切换过来,市场有一些合作伙伴,可以帮客户切换到MySQL上,其实我们的这个方案很简单,如果您能换到MySQL上,那一定能切换到TiDB上面。
选型宝:从TiDB本身产品下一步的发展规划上,您是怎么去设计的呢?
黄东旭:一个比较大的愿景,就是大一统,我希望能够有一个平台,像TiDB这样的平台,能够去统一不同的数据的结构,底层的数据存储引擎来去通过一套比较简单的接口去把这些复杂的选型的问题给屏蔽掉。
下一步,简单来说,就是更高、更快、更强。主要是几个方面:
一是,会持续的去加强我们的分析能力,因为其实事务这块你的目标是很明确的,多少并发,然后多少个压力,但是复杂的分析范围就很广,其实我个人认为TiDB是一个铁人三项型选手,我们现在有很大一个团队在做高性能的HTAP方向,就是更好的资源隔离,复杂分析的更高性能,这一块是未来可能会发展的一个方向。
二是,跟云的整合会持续的进行投入,在未来大家可以去期待一个这种云平台,私有云或者公共云平台上一键去自动使用TiDB的一个体验。
三是,让产品更稳、更健壮。
其实很多商业客户,他的诉求也很朴素。稳,够大、使用更方便、别出事,这都是很朴素的一些想法,我们其实也是这样很接地气的在做数据库。
把一个数据库做快,对我们来说不是什么太困难的东西。但是做稳做健壮,是一个我觉得很重要的一点。把一个东西做稳,在各种环境下得到了充分的锻炼,包括我们在内部对于测试非常重视,我们写了一系列的文章去描述我们的测试的框架平台,去把它搞稳定,测试充分,这一点是我个人觉得最有挑战的一部分事情之一。
所以到现在为止,我对一些很新潮的技术会更理性的去思考。在我的头脑里面稳定性是放在最高的位置上,我已经见到太多很复杂的场景。 中国人为什么愿意讲愚公移山的故事,很多时候就是把简单事情做到极致。相信时间的力量,所以我们比较有耐心的。