作者:大谷
什么是故障
简单来说,当功能或性能不符合预期,就是故障。
故障有两个比较重要的衡量指标:
RPO(Recovery Point Objective):主要指的是业务系统能容忍的最大数据丢失量,针对的是数据丢失。对于资金业务来说,一般 RPO 不能大于 0 的。
RTO(Recovery Time Objective): 主要指的是所能容忍的所业务停止服务的最长时间,针对的是服务丢失。
从单系统的角度看故障

一个系统,从头到脚,有非常多的故障点,所以,对于一个分布式系统来说,一定要假定故障是随时、而且一定会发生的。
故障隔离的目的
减少故障的方式有多种,包括系统优化、监控、风险扫描、链路分析、变更管控、故障注入演练、故障隔离等。故障隔离是其中一种手段,并且要求在系统设计时就需要考虑清楚。
从系统的角度看
故障隔离是指在系统设计的时候,要尽可能考虑故障的情况,当存在依赖关系的系统、系统内部组件或系统依赖的底层资源发生故障后,采取故障隔离措施可以将故障范围控制在局部,防止故障范围扩大,增加对上层系统可用性带来的影响。
并且当故障发生时,我们能够快速定位故障源,为后续的故障恢复提供必要条件。
从业务的角度看
故障隔离是为保障重点业务和保障重点客户,本质上弃卒保车的做法。
所以,各个业务域需要定义出哪一些是重点业务和客户。区分办法视各个业务而定。
有一种区分是按核心功能、重要功能、非关键功能三个等级来区分。比如,对于支付业务来说,支付肯定是一级业务,像营销、限额等是二级业务,而运营管理功能是三级业务。
故障隔离的基本原理
- 故障时能够切断依赖
- 服务或资源隔离,避免共享
- 避免同步调用
故障隔离的常用模式
第一、依赖降级
默认降级
默认降级就是当依赖方出现问题的时候,采用默认的策略进行处理,而不是直接系统异常。
它的另一个变种是需要通过开关才能打开降级能力,一般用于一些比较谨慎的场景,比如对整个营销系统依赖进行降级。
例子 1
当依赖的缓存系统故障时,业务处理不是直接失败,而是捕捉到异常后,直接降级调用数据库
例子 2
在支付的场景中,会有每日提现额度的限制(是一个二级业务)。当依赖的限额系统出现故障时,针对小额提现的场景,可以默认降级,不依赖于限额系统。并且,同时,会记录下哪些使用额度没有同步到限额系统,在限额系统恢复后,将故障期间的使用额度同步到限额系统。
动态切换(Failover)
当故障发生时,动态地切换到备用方案
例子 1
数据库的主备切换机制,独立的 HA 心跳机制检查主节点状态,一旦主节点不可用,则切换到备节点。类似的,缓存系统的备节点也是类似原理。
当然,这种方式常常是异步复制,RPO>0
例子 2
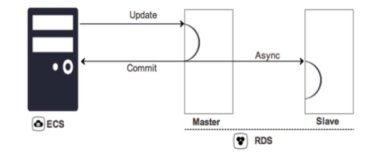
如下图,是针对流水型数据 master 节点故障的 FO 方案,可以做到 RPO=0。什么是流水型数据,就是比较支付订单,贷款请求等这种一次请求生成一条的业务数据。
当 master 库故障时,因为是异步复制的,如果直接切到 slave 库,可能会导致数据丢失。那么 FO 的方案,就是直接切到一个空的 FO 库,对于新数据就读写到新的 FO 库。这个时候的影响,是老数据无法访问,但是新业务还能继续运行,比如支付业务还是继续跑。
这个时候再人工恢复 master,保证其与 slave 数据完成同步。再把调用连接切回到 master。
一般来说,已经写到 FO 库的数据可以回迁,也可以不回迁,应用通用流水号的 FO 标记则能识别应该调用哪一个库。

例子 3
如下图,也是针对于消息型数据 master 故障时的 markdown 方案。比如消息中心的存储就是用这种方案。
消息型跟流水型数据的区分是,消息型通用路由规则是随机的,放在哪都无所谓,而流水型如何使用分库分表方案,通用路由规则需要固定。比如基于 user_id 的后 2 位路由到库表,这个不能随意变更,不然会导致数据大量错乱,可能会导致大量的跨库事务问题和恢复后数据无法回查的问题。
这个方案类似于例子 2 的思路。不同点在于它是多个节点都是活跃的,每一次请求可以随机写到其中某一个库,当其中一个库挂了,那只会影响 50% 的老数据,对于另外 50% 的老数据和新增的数据是不会有影响的。而且这个方案还可以继续扩展,可以搞成 N 组数据库。

动态调整请求
当依赖方某些节点出现故障时,自动调整调用频率,或直接剔除
例子 1
消息中心在推送消息时,会根据消费节点的响应时间,调整推送的消息数量和间隔,避免将消费节点打挂。比如:推送时发生消费节点最近 5 秒平均响应时间超过 1000ms,则减少消息推送量,加大推送间隔。如果下次推送时间恢复正常,则逐步加大推送量,减小间隔,多次之后,如果消费节点没有问题,则恢复到正常的节奏。
例子 2
rpc 调用时,当调用节点出现调用异常时,有多种动态调节策略。比如节点不可用,直从消费节点中剔除。如果是节点响应明显变慢,则会降低路由的权重,减少调用次数。还有就是节点冷启动的情况,当节点第一次调用时,会灰度先调用少量数量,使系统先完成初始化,再逐步加大权重,直到跟其他节点权重一样。
快速失败(Fail Fast)
快速失败是指依赖方不可用时,不能耗费大量的宝贵系统资源(比如线程,比如连接数)等,在等待其恢复,而是要在其超出合理的功能和性能要求时,快速失败,避免占用资源,反而拖垮系统
例子 1
rpc 调用时,如果不设置超时时间,当调用方不可用时,同时会耗尽调用方的线程池,从而拖垮调用方。如果调用方的上游也是这样,那就会导致整体雪崩。
例子 2
数据库执行 SQL,如果不设置超时时间,当出现不合理的慢 SQL 时,很快会耗尽连接池,新的业务请求拿不到连接,就会一直挂起等待,很快你的线程池和请求队列会被占满,系统严重不可用。如果请求队列连是无界队列,则有可能直接 OOM。
缓存依赖数据
依赖数据本地缓存是一种数据的降级方案,当依赖方故障时,可以一定程度地保障业务可用。一般是应用于核心,决不能挂的业务场景。
例子 1
客户系统是一个全部系统都会依赖的非常核心的系统,如果其不可用,则会导致全局性的业务不可用,非常凶险。其中一种处理办法,就是客户信息的本地缓存,一方面可以降级被客户系统的调用压力,另一方面,当客户系统异常时,只要是已经缓存客户,还是可以继续使用业务,可以最大限制的保障业务可用。
这里的技术难点是在于缓存的一致性更新。通常有几种策略,一种是定时更新(客户系统正常时),另一种是本地缓存由客户系统提供一个统一的 sdk 管理,提供一种机制,当某一个用户变更时,通用各种 sdk 方更新数据。
另一个变种是,是将缓存放在 Tair,而不是调用方本地。这样,数据一致性的维护会更简单一些。目前内部用的最多是这种方案。
例子 2
归因系统会依赖于 Tair 中的配置信息,来判断请求中的参数(pub 值)是否合法。可以将配置信息(不大),缓存到调用方本地,这样,当 Tair 故障时,只会影响少量新增的配置,对于大部分业务功能是可用的。
减少或不要对低级别系统的依赖
这个是一种依赖原则,因为高级别系统的可用性标准(可用率、性能等)一般是高用于低级别系统的,如果依赖于低级别系统,当它发生故障时,高级别系统也会故障。这样本本质上是将高级将系统的可用性拉低到低级别系统的水平。
例子 1
比如,在支付系统去依赖于运营后台的话,假设原来支付系统的可用率是 99.99%,而运营后台的可用率是 99%,一旦这么依赖且无降级方案,则支付系统的可用率也会降低为 99%。
第二、功能降级
限流
限流的目的,是通过牺牲超过系统处理能力的部分业务,来保全系统整体的可用。
例子 1
所有 API 网关都会有限流的能力,常用的算法有计数器、漏桶算法,令牌桶算法等,总之就是会保护在一定时间内的并发数或者请求数。避免突发流量或者恶意的攻击,将系统打垮。
例子 2
归因系统中,收到归因请求,不会直接处理,而是先落到队列中(用数据库实现),然后按一定的时候频率,每次捞取一定量的数据处理,这样可以匀速地处理系统请求,削峰填谷,避免突发的请求数将系统打挂。
关闭非关键业务
就是关闭非关键的业务,不让其影响关键业务
例子 1
支付账单在双 11 高峰的时候,关闭实时更新账单的能力,改为双 11 过后,批量处理。
例子 2
双11高峰的时最为关键的业务,就是担保交易的付款,其它业务的重要性都会相对较低,比如收费业务,完全可以晚一点再向商户收取,以及淘宝的一些通过 CAE 代扣进来的返佣等业务,也可以一定程度上的滞后。
例子 3
消息中心提供了积压查询的功能,但是该功能是一个非关键功能,并且非常的耗费 DB 性能。大促时或系统处理能力紧张时,可以关闭掉,等恢复正常再打开。
第三、日志降级
顾名思义,就是将日志从 INFO,甚至 DEBUG 级别降为 WARN 或 ERROR 级别。
例子 1
写日志是比较消耗性能的操作,而且会占用大量磁盘,比如在大促时,或者因为日志过大导致磁盘打满时,可以通用日志降级来处理。
服务或资源隔离
概述一下,一般来说,隔离的级别可以有很多,如下图,不同的处理办法会不同在级别上进行。

用户级别隔离
将不同用户所使用的资源分开,保障部分资源故障时,只影响部分用户,而不是全体用户。
例子 1
支付宝按 RZONE 拆成逻辑机房,每个 RZONE 机房都会有完整的业务处理能力。用户请求的时候,会根据其 id 号,按配置的路由规则路由到某一个 RZONE 中。
这样,当部分 RZONE 异常时,只会影响跌幅到这部分机房的用户,而不是全局不可用。
例子 2
分库分表的时候,将用户相关的数据独立成一组分库。用户处理请求的时候,会根据其 id 号路由到其中一个分库上。这样,当用户数据相关的数据库的某一个实例宕机时,只会影响其中的部分用户,比如分了 10 个分库,则只会影响 10% 的用户,而不是全局用户。
业务功能隔离
将不同业务功能所使用的资源隔离,不互相影响
例子 1
贷款系统中,将还款和借款拆分不同系统。因为前者是一个非实时的批处理系统,而后者是对实时性和稳定性要求很高的联机系统,是用户可以直接感知到的。
拆分后,不会因为在批处理高峰期占用过多资源而影响借款系统的稳定性,而且两者在运维上,也可以更方便地根据各自的需要评估所需的机器数据。
例子 2
支付系统中,支付是关键业务,而账单是非关键业务,而且后者涉及到一些大数据量的查询(尤其是大商户),这些查询如果使用在线库查询,会影响支付的稳定性。所以,这两个业务进行了拆分。拆分后,支付业务会将数据异步同步给账单系统,账单系统会保存到更适用于账单查询的大数据存储中(HBase 或 ES)。
系统资源隔离
将不同的请求和所使用的资源隔离,不互相影响。
例子 1
API 请求网关,如果所有 API 请求都使用一个线程池,则当某一个 API 处理过慢的时候,会因为占满了线池,而导致其他 API 也不可用。所以,需要将不同的 API 分组,分配不同的线程池,避免互相影响。
例子 2
数据库集群管理的时候,将关键业务的实例和非关键业务的实例分开到不同集群,保障非关键的实例发生异常拖挂系统时,不会影响到关键业务的实例。
异步化处理
分阶段处理
分阶段就是主要逻辑就是避免同步调用,因为同步调用意味着强依赖,当依赖方故障时,调用方也会异常,而且这个异常可能会被用户感知。换句话讲,就是尽量异步化处理。
例子 1
消息的处理过程主要分为消息投递和消息接收两个阶段,如果两个处理阶段强耦合在一起,当某阶段出现故障,会影响另一阶段的处理。
例子 2
支付请求分至少分为支付受理、支付处理、支付结果回调三个阶段,如果这三个阶段分阶段异步处理,那么这其中某一个步骤异常了,都会导致支付失败,支付成功率低,用户体验差。而且,因为需要等待所有步骤都处理完,接口的性能也会很差。
例子 3
归因请求处理,分为接收处理(只有简单的归类逻辑)、归因处理(会有复杂的业务逻辑和外部依赖)两个阶段。同上,如果强耦合,当某阶段出现故障,会影响另一阶段的处理。