异步编程CompletableFuture实现高并发系统优化之请求合并
先说场景:
根据Redis官网介绍,单机版Redis的读写性能是12万/秒,批量处理可以达到70万/秒。不管是缓存或者是数据库,都有批量处理的功能。当我们的系统达到瓶颈的时候,我们考虑充分的压榨缓存和数据库的性能,应对更大的并发请求。适用于电商促销双十一,等特定高并发的场景,让系统可以支撑更高的并发。
思路:
一个用户请求到后台,我没有立即去处理,而是把请求堆积到队列中,堆积10毫秒的时间,由于是高并发场景,就堆积了一定数量的请求。
我定义一个定时任务,把队列中的请求,按批处理的方式,向后端的Redis缓存,或者数据库发起批量的请求,拿到批量的结果,再把结果分发给对应的请求用户。
对于单个用户而言,他的请求变慢了10毫秒是无感知的。但是对于我们系统,却可以提高几倍的抗并发能力。
这个请求合并,结果分发的功能,就要用到一个类CompletableFuture 实现异步编程,不同线程之间的数据交互。
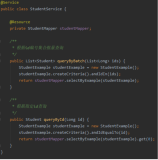
线程1 如何创建异步任务?
//创建异步任务
CompletableFuture> future = new CompletableFuture<>();
//阻塞等待获取结果。
Map result = future.get();
线程2 如何把数据赋值给线程1 ?
// 线程2的处理结果
Object result = "结果";
//线程2 的结果,赋值 给 线程1
future.complete(result);
CompletableFuture 是由大牛 Doug Lea 在JDK1.8 提供的类,我们来看看complete()方法的源码。
复制代码
/**
* If not already completed, sets the value returned by {@link
* #get()} and related methods to the given value.
*
* @param value the result value
* @return {@code true} if this invocation caused this CompletableFuture
* to transition to a completed state, else {@code false}
*/
public boolean complete(T value) {
boolean triggered = completeValue(value);
postComplete();
return triggered;
}复制代码
翻译:
如果尚未完成,则将返回的值和相关方法get()设置为给定值。
也就是说,
线程1 的get() 方法,拿到的就是线程 2 的complete() 方法给的值。
看到这里,应该基本明白这个异常编程的意思了。它的核心就是线程通信,数据传输。直接上代码:
复制代码
package www.itbac.com;
import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.*;
public class CompletableFutureTest {
//并发安全的阻塞队列,积攒请求。(每隔N毫秒批量处理一次)
LinkedBlockingQueue<Request> queue = new LinkedBlockingQueue();
// 定时任务的实现,每隔开N毫秒处理一次数据。
@PostConstruct
public void init() {
// 定时任务线程池
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {// 捕获异常
try {
//1.从阻塞队列中取出queue的请求,生成一次批量查询。
int size = queue.size();
if (size == 0) {
return;
}
List<Request> requests = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
// 移出队列,并返回。
Request poll = queue.poll();
requests.add(poll);
}
//2.组装一个批量查询请求参数。
List<String> movieCodes = new ArrayList<>();
for (Request request : requests) {
movieCodes.add(request.getMovieCode());
}
//3. http 请求,或者 dubbo 请求。批量请求,得到结果list。
System.out.println("本次合并请求数量:"+movieCodes.size());
List<Map<String, Object>> responses = new ArrayList<>();
//4.把list转成map方便快速查找。
HashMap<String, Map<String, Object>> responseMap = new HashMap<>();
for (Map<String, Object> respons : responses) {
String code = respons.get("code").toString();
responseMap.put(code,respons);
}
//4.将结果响应给每一个单独的用户请求。
for (Request request : requests) {
//根据请求中携带的能表示唯一参数,去批量查询的结果中找响应。
Map<String, Object> result = responseMap.get(request.getMovieCode());
//将结果返回到对应的请求线程。2个线程通信,异步编程赋值。
//complete(),源码注释翻译:如果尚未完成,则将由方法和相关方法返回的值设置为给定值
request.getFuture().complete(result);
}
} catch (Exception e) {
e.printStackTrace();
}
}
// 立即执行任务,并间隔10 毫秒重复执行。
}, 0, 10, TimeUnit.MILLISECONDS);
}
// 1万个用户请求,1万个并发,查询电影信息
public Map<String, Object> queryMovie(String movieCode) throws ExecutionException, InterruptedException {
//请求合并,减少接口调用次数,提升性能。
//思路:将不同用户的同类请求,合并起来。
//并非立刻发起接口调用,请求 。是先收集起来,再进行批量请求。
Request request = new Request();
//请求参数
request.setMovieCode(movieCode);
//异步编程,创建当前线程的任务,由其他线程异步运算,获取异步处理的结果。
CompletableFuture<Map<String, Object>> future = new CompletableFuture<>();
request.setFuture(future);
//请求参数放入队列中。定时任务去消化请求。
queue.add(request);
//阻塞等待获取结果。
Map<String, Object> stringObjectMap = future.get();
return stringObjectMap;
}
}
//请求包装类
class Request {
//请求参数: 电影id。
private String movieCode;
// 多线程的future接收返回值。
//每一个请求对象中都有一个future接收请求。
private CompletableFuture<Map<String, Object>> future;
public CompletableFuture<Map<String, Object>> getFuture() {
return future;
}
public void setFuture(CompletableFuture<Map<String, Object>> future) {
this.future = future;
}
public Request() {
}
public Request(String movieCode) {
this.movieCode = movieCode;
}
public String getMovieCode() {
return movieCode;
}
public void setMovieCode(String movieCode) {
this.movieCode = movieCode;
}}
复制代码
这样就实现了请求合并,批量处理,结果分发响应。让系统支撑更高的并发量。
当然,因为不是天天双十一,没有那么大的并发量,就添加一个动态的配置,只有当特定的时间,才进行请求堆积。其他时间还是正常的处理。这部分逻辑就不写出来了。