场景
今天我们做o2o有很多的线下场景需要基于用户的行为进行分析,比如 我们在商场入门口装了一个摄像头,可以通过摄像头识别商场进入的人脸,和出去时候的人脸,这样形成了2条数据。商场想统计下,每个用户在商场的逗留时间。这里面就出现了一种pattern的模式,就是当用户进门和出门这两个事件都发生的时候,激发某个动作(事件)。比如在这里是在用户出门的时候将用户进门时间和出门时间的差值相减,并存储在tablestore当中。然后可以通过分析汇总算出今日用户在商场的平均逗留时间,继而可以统计出当月,当年的平均逗留时间,等等,促使商家提升总体运营水平。
这里面 用户进入商场 和用户走出商场是两个用户行为,当它们组合在一起时候就有了奇妙的意义。blink在分析此类用户行为方面提供了极其强大的模式匹配功能。下面我以这个场景,详细描述下如果使用。
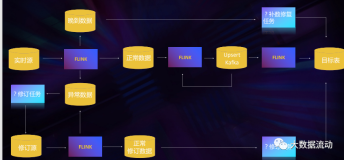
架构图

用户行为表
用户逗留时间表
用户行为表用来记录摄像头识别的用户进门和出门的产生的记录,用户逗留时间表用来记录每个用户的逗留时间。
以用户行为表为blink的源表,用户逗留时间表为结果表。这里使用tablestore为存储数据库。为什么使用tablestore,因为tablestore的通道和blink能进行无缝的集成,tablestore的存储成本非常的低廉,扩展性又非常的好。有想了解tablestore的同学,点击传送门,当然也可以换成hbase等类似的数据库。
下面是具体的代码
CREATE TABLE mofun_source_user_action (
--id
id BIGINT,
-- 记录日期
record_date BIGINT,
--用户iduser_id BIGINT,
--数据触发时间
prd_time BIGINT,
--数据行为类型
opt_type varchar,
--计算列
ts AS to_timestamp(prd_time),
WATERMARK FOR ts AS withOffset(ts, 1000),
primary key (record_date, user_id, prd_time,opt_type)
)
CREATE TABLE ots_result_user_play_time (
--进入id
inid BIGINT,
--出去id
outid BIGINT,
--记录日期
record_date BIGINT,user_id BIGINT,
play_time BIGINT,
primary key (record_date,user_id)
)
insert into ots_result_user_play_time
SELECT
inid,
outid,
start_tstamp,
`user_id`,
play_timeFROM mofun_source_user_action MATCH_RECOGNIZE (
PARTITION BY `user_id`
ORDER BY ts
MEASURES
e1.id as inid,
e2.id as outid,
e1.record_date AS start_tstamp,
(e2.prd_time-e1.prd_time) AS play_time
ONE ROW PER MATCH
PATTERN (e1->e2) WITHIN INTERVAL '10' Hour
DEFINE
e1 AS e1.opt_type ='in',e2 as e2.opt_type='out'
)
其中最关键的是最后这块代码
解释一下代码
DEFINE,定义的是模式匹配的变量,意思你要用哪列,什么条件的数据来进行条件匹配
PATTERN 就是变量的匹配模式,e1->e2的意思是指 进门后面如果出现了出门就匹配成功
MEASURES 里面是要在select中显示的数据列
具体文档看传送门(https://yuque.antfin-inc.com/rtcompute/doc/sql-query-cep),不过这篇文章讲得也不是很清楚,后面我会写一篇文章专门详细介绍复杂的匹配。
像上面这种场景稍微的进行一下更改就有很多场景可以使用。比如 我们现在经常使用短视频,那么我们怎么分析用户在某个短视频的停留时间呢?就可以在用户进入视频和出了视频产生一个事件,然后用上面这个语法就能分析出来,每个用户在视频上面的停留时间,然后根据排个实时排行榜,然后进行推荐。排行榜的架构,可以看我的上一篇文章,如何构建实时的排行数据。