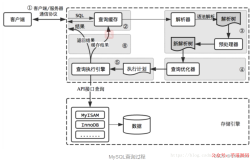
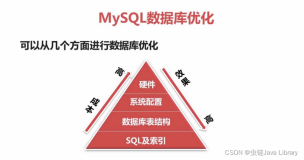
sql性能优化精华总结
explain在性能分析上有很大的作用
id:包含一组数字,表示查询中执行select子句或操作表的顺序,id相同,执行顺序由上至下,id越大优先级越高,越先被执行
select_type: 常见几个
simple:表示简单的select,没有union和子查询
primary:有子查询,最外面的select查询就是primary
union:union中的第二个或随后的select查询,不依赖外部查询结果
dependent union:union中的第二个或随后的select查询,依赖外部查询结果
table: 当前表名
type: system(表仅有一行(=系统表),这是const连接类型的一个特例),const(常量查询),ref(非唯一索引访问,只有普通索引),eq_ref(主键或唯一索引),range(索引的范围查询),index(根据索引查询全表),all(全表扫描,通常没有建索引的列)
效率:system>const>eq_ref>ref>range>index>all
possible_keys: 表中可能帮助查询的索引
key: 选择使用的索引
key_len: 使用的索引长度(在不损失精度的情况下越短越好)
rows: 扫描的行数,越大越不好
filtered: 表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数
extra: 了解几个
using temporary:组合查询返回的数据量太大需要建立临时表存储数据,出现这个sql应该优化
using where:使用where查询条件
using index:使用覆盖索引,不需要回表查询
using filesort:MySQL中无法利用索引完成的排序操作称为“文件排序”,使用文件排序,使用非索引列进行排序时出现,非常消耗性能,尽量优化
如果知道查询结果只有一条,那么sql语句中使用limit 1会提高查询效率,避免全表扫描
避免在复杂查询里使用like ‘%parm%’,以%开头的模糊查询都会导致索引失效,而’param’和’param%'还是会使用索引
如果不是业务必须,建议使用union all代替union,因为union需要进行排重,效率低。对于一些单纯使用分表来提高效率的查询,完全可以使用union all
尽量用join代替子查询,虽然join性能并不佳,但和mysql子查询比起来还是有非常大的性能优势,因为连接查询不需要建立临时表,其速度比子查询快
尽量避免使用!=或<>操作符,引擎将放弃使用索引而进行全表扫描,可以考虑改为范围查询解决
尽量避免使用or来连接条件,引擎将放弃使用索引而进行全表扫描,如可使用(or查询现在的mysql版本好像也走索引)
select id from table1 where name='zhangsan'
union all
select id from table1 where name='lisi'
替代
select id from table1 where name='zhangsan' or name='lisi'
尽量避免使用in和not in,引擎将放弃使用索引而进行全表扫描,对于连续数值,能用between就不要使用in(in查询现在的mysql版本好像也走索引)
尽量避免使用select *查询
区分in和exist
select * from table1 where id in (select id from table2)
等价于
select from table1 where exists(select from table2 where table2.id=table1.id)
exists以外表为驱动,先被访问,in以内表为驱动。exists适合外表小而内表大,in适合外表大而内表小
在in和exists通用的情况下使用exists,因为in不走索引
用where字句替换HAVING字句,因为having只会检索出所有记录之后才对结果集进行过滤
尽量不要有空判断的语句,这将导致全表扫描而不是索引扫描,一般为经常null判断的列增加默认值
索引列上有函数处理,将导致不走索引
隐式转换导致不走索引
mysql组合索引遵循“最左前缀”的原则,组合索引中第一列必须出现在查询条件中,组合索引才有效
尽量使用数字型字段,尽可能使用varchar/nvarchar代替char/nchar,这样节省存储空间,提升检索效率。
根据需要建立多列联合索引
根据业务场景建立覆盖索引只查询业务需要的字段
多表连接字段上需要建立索引
where条件字段上需要建立索引
排序字段建立索引
分组字段建立索引
作者:shuangyueliao
来源:CSDN
原文:https://blog.csdn.net/shuangyueliao/article/details/89512894
版权声明:本文为博主原创文章,转载请附上博文链接!