更多深度文章,请关注云计算频道:https://yq.aliyun.com/cloud
作者介绍:
Parul Sethi,undergrad of Maths and IT at CIC, University of Delhi. RaRe Incubator Student.

在众多词嵌入(有的也称作词向量)模型中选择一个合适的模型是很困难的任务,是选择NLP常用的Word2Vec还是其他模型?
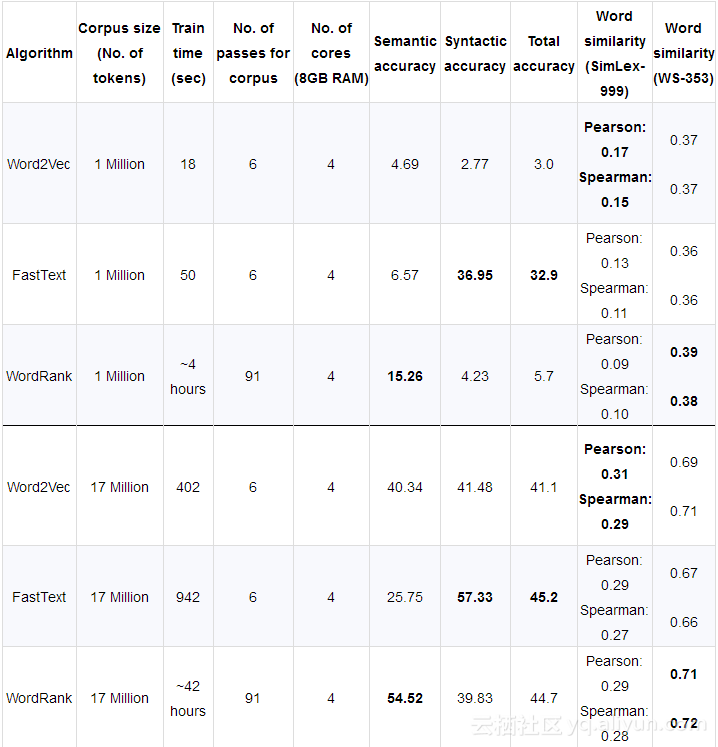
如图1所示,用WordRank,Word2Vec和FastText三种模型分别找出与“king”最相似的词语,WordRank的结果更加倾向于“king”这个词本身的属性或者和“king”同时出现最多的词,而Word2Vec的结果多是和“king”出现在相似的上下文。
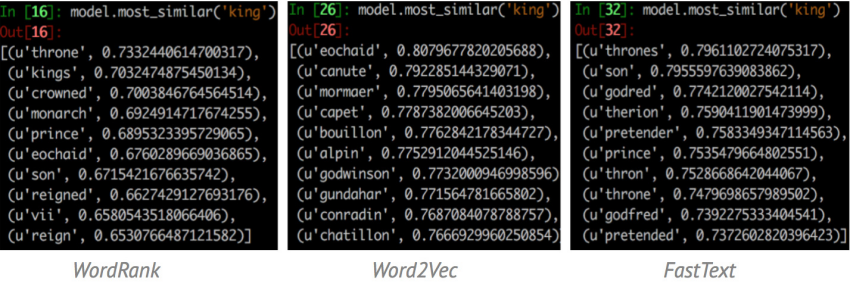
图1. WordRank, Word2Vec和FastText三种模型输出与"king"最相似的词
不同模型实验结果对比
可视化比较
在使用TensorBoard对这三种词嵌入模型的结果进行可视化处理后,得出的结论和最开始三种模型的输出结果相似。TensorBoard使用PCA或者t-SNE方法将原始多维词向量降维至2维或者3维,原始词向量的信息会丢失一些,词之间的余弦相似度/距离会有所改变,但仍然是相关的,所以可视化的结果相对于图1中的结果会有所改变。
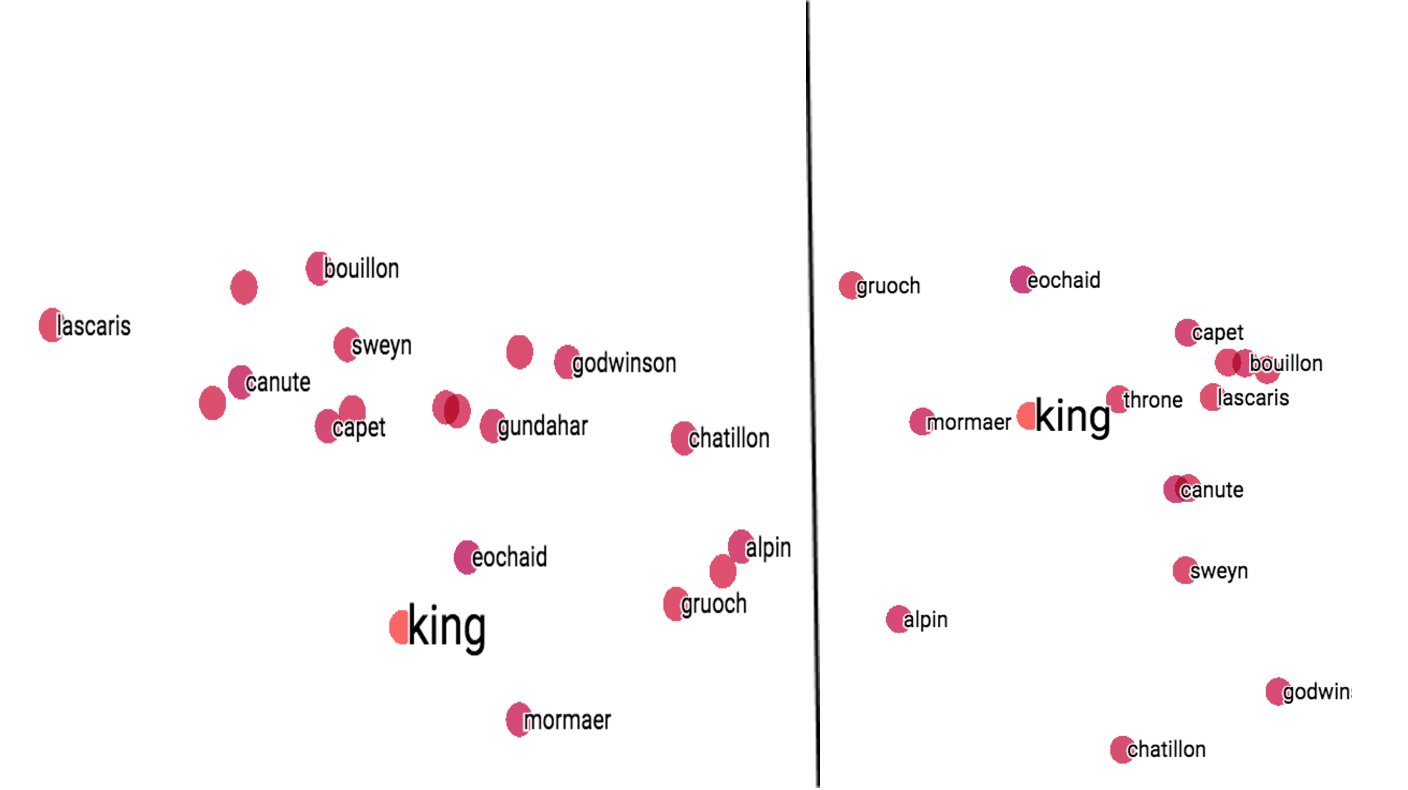
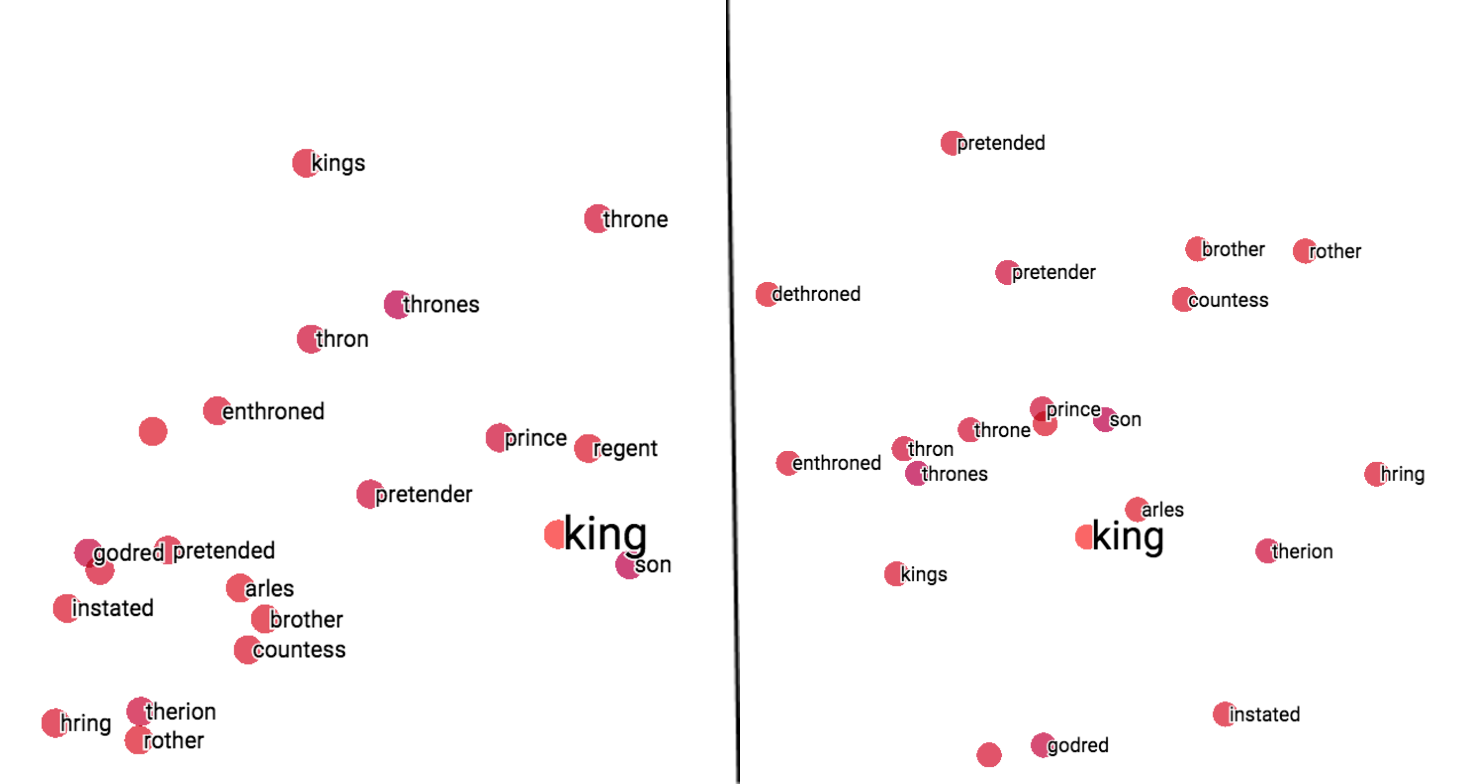
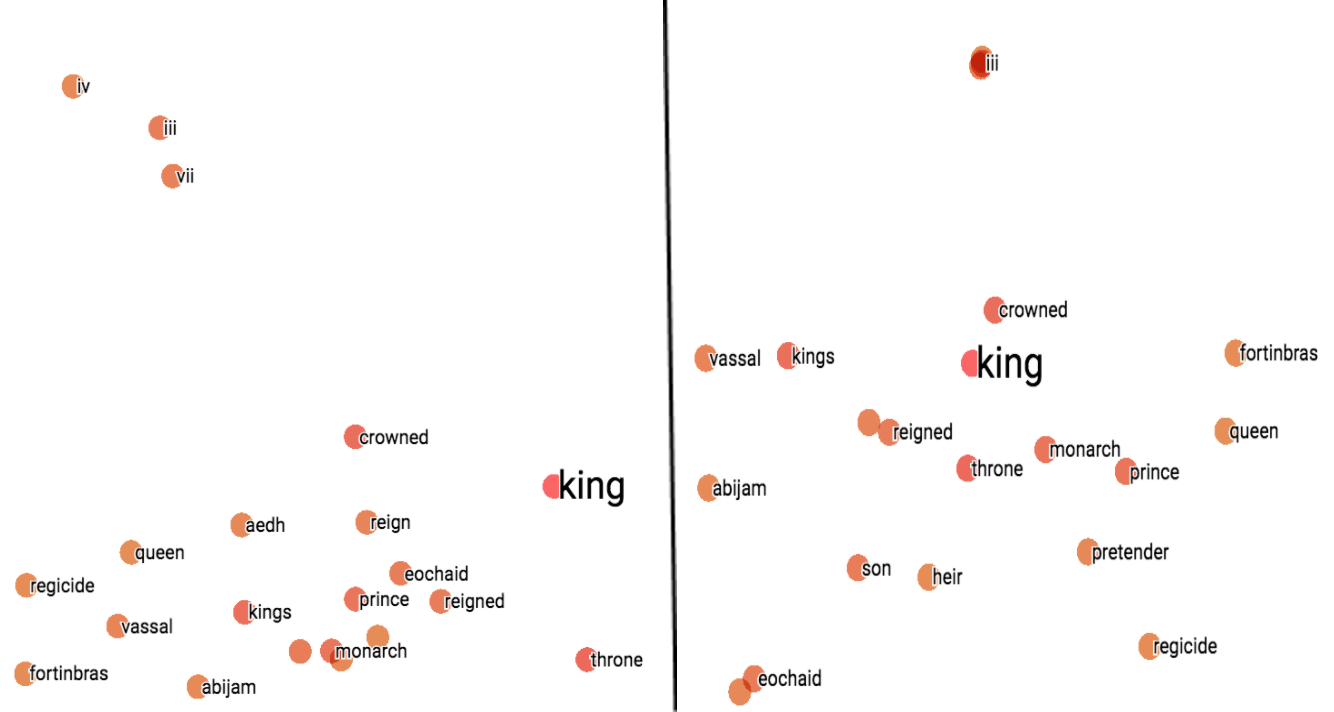
图3. 不同模型使用PCA与t-SNE的效果对比
从图3可以看出,在Word2Vec模型中,两种方法都表现不错。要注意的是,由于t-SNE是一种随机方法,所以即使是使用相同的参数设置,也可能得到不同结果。在FastText中,两种方法表现相似,稍次于Word2Vec。在WordRank模型上 ,t-SNE方法效果好于PCA,因为在PCA方法中,一些最相似的词反而在图中被置于较远的位置。
词频和模型性能
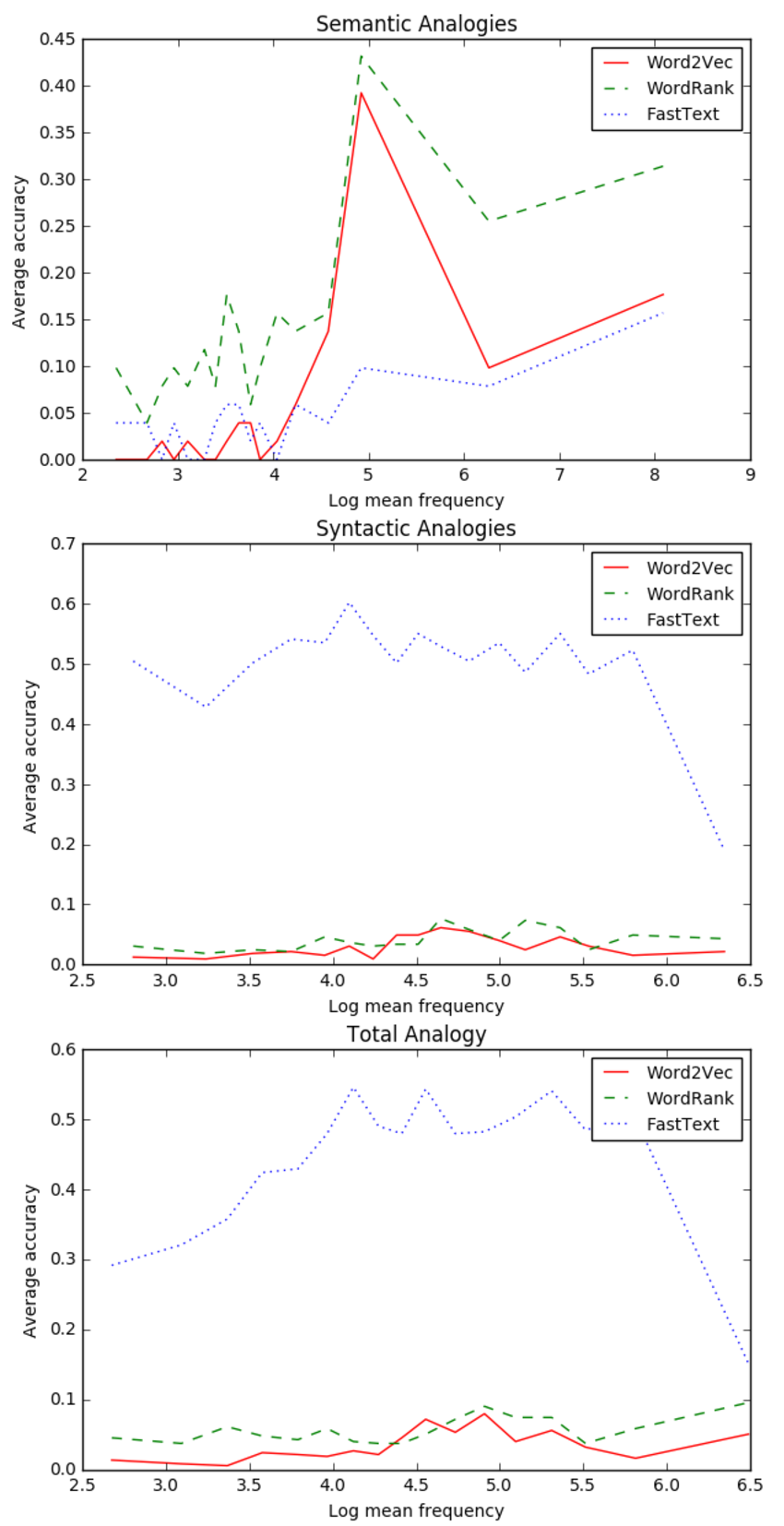
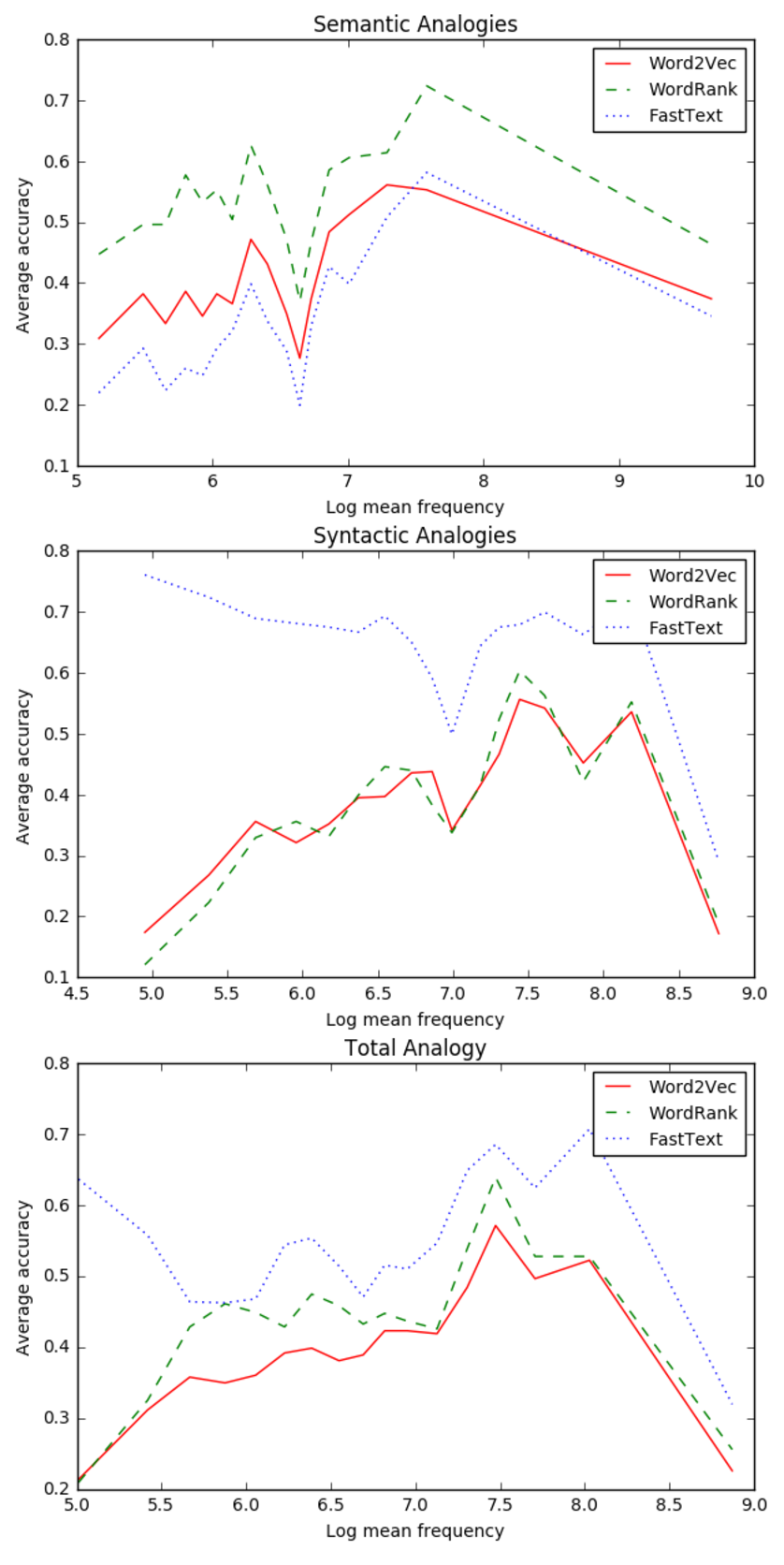
由图4和图5分析表明:
- 1.在语义类比中,三种模型在低频词语上表现相对较差,在高频词语上表现效果较好;
- 2.在语法类比中,FastText优于Word2Vec和WordRank 。FastText模型在低频词语上表现的相当好,但是当词频升高时,准确率迅速降低,而WordRank和Word2Vec在很少出现和很频繁出现的词语上准确率较低;
3. FastText在综合类比中表现更好,最后一幅图说明整体类比结果与语法类比的结果比较相似,因为语法类比任务的数量远远多于语义类比,所以在综合结果中语法类比任务的结果占有更大的权重;
综上,WordRank更适合语义类比,FastText更适合不同语料库下所有词频的语法类比。
三种模型词类比
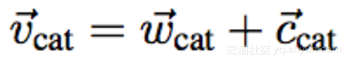
结论
1. 没有一种能够适用于不同NLP应用的词向量模型,应该根据你的具体使用场景选择合适的词向量模型。
2. 除了模型本身,词频也会对类比任务结果的准确率有重要影响。正如上面图中所示,语料库中词的频率不同,模型性能也不同,例如,如果词频很高,得到的精确度可能会比较低。
以上为译文
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《WordRank embedding: “crowned” is most similar to “king”, not word2vec’s “Canute”》 作者:Parul Sethi 译者:东东邪
文章为简译,更为详细的内容,请查看原文,
PS:如果网站打不开,请下载本文附件查看原网页或点击此处。