热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
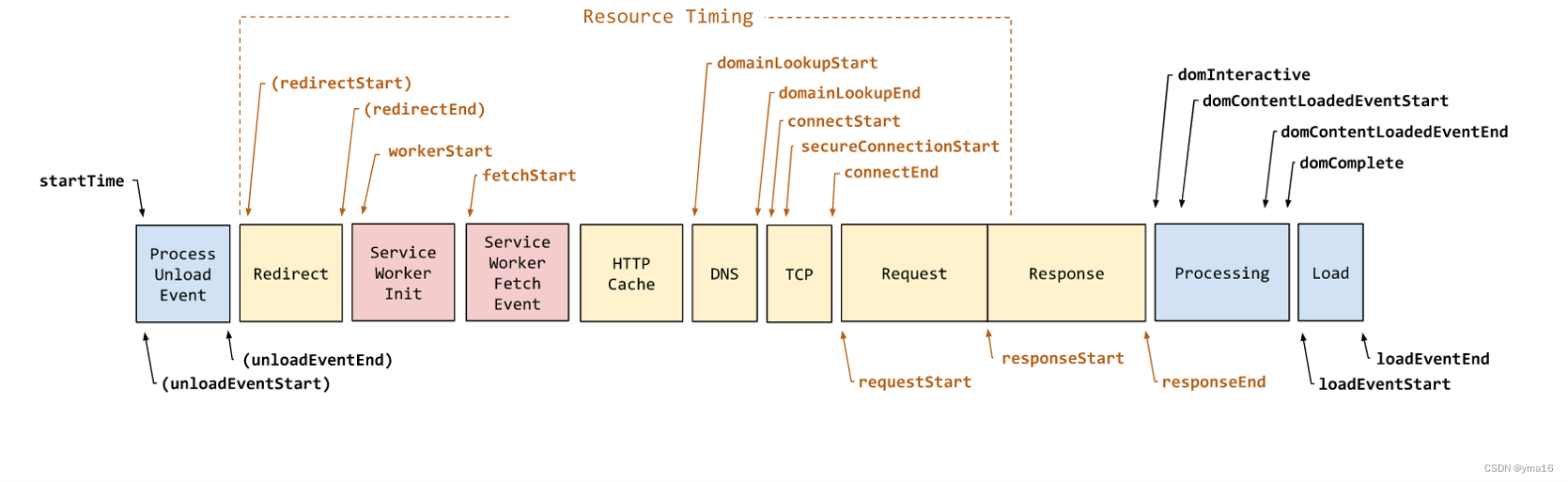
前端vite+vue3——可视化页面性能耗时指标(fmp、fp)
知识图谱算法有哪些
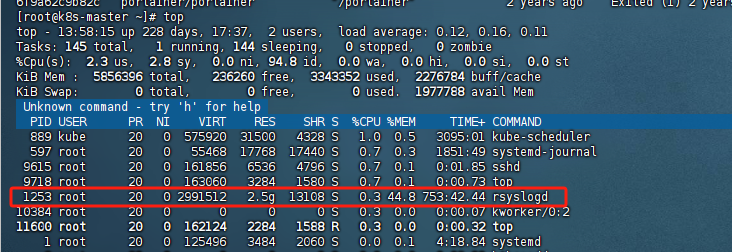
Linux rsyslog占用内存CPU过高解决办法
每天解析一个脚本(52)
Java Exception打印及输出到日志
前端vite+vue3结合后端node+koa——实现代码模板展示平台(支持模糊搜索+分页查询)
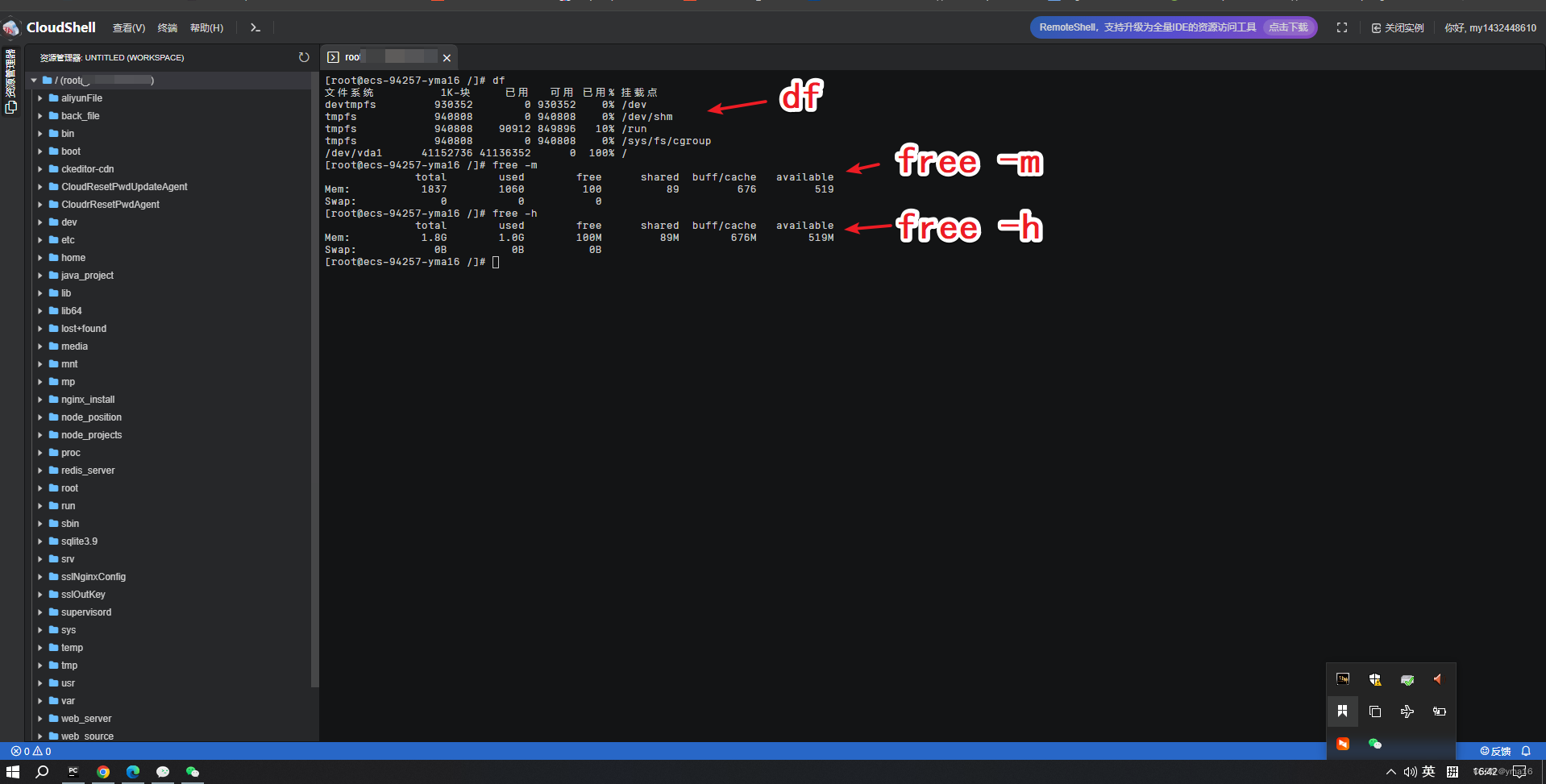
linux优化空间&完全卸载mysql——centos7.9
万字综述:2023年多模态检索增强生成技术(mRAG)最新进展与趋势-图片、代码、图谱、视频、声音、文本
每天解析一个脚本(51)
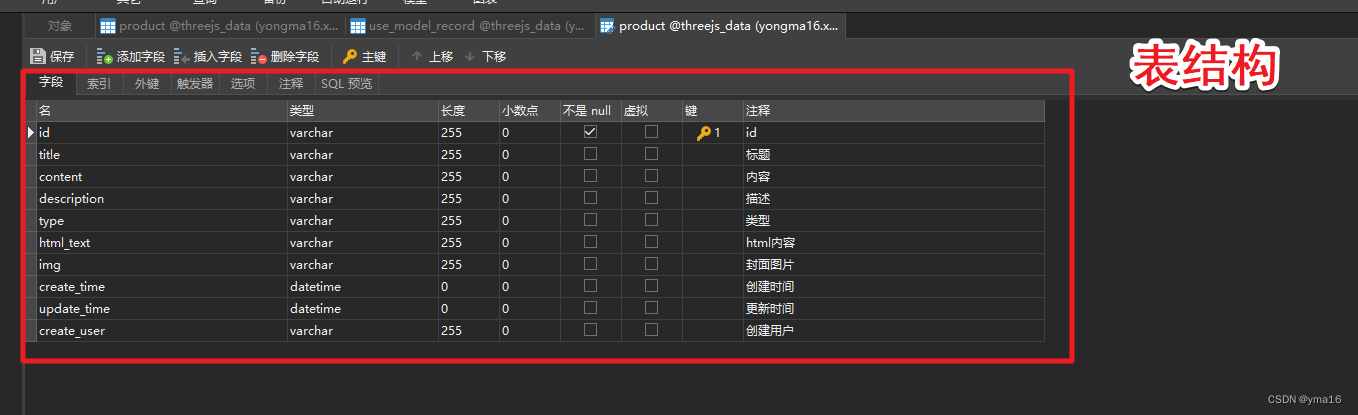
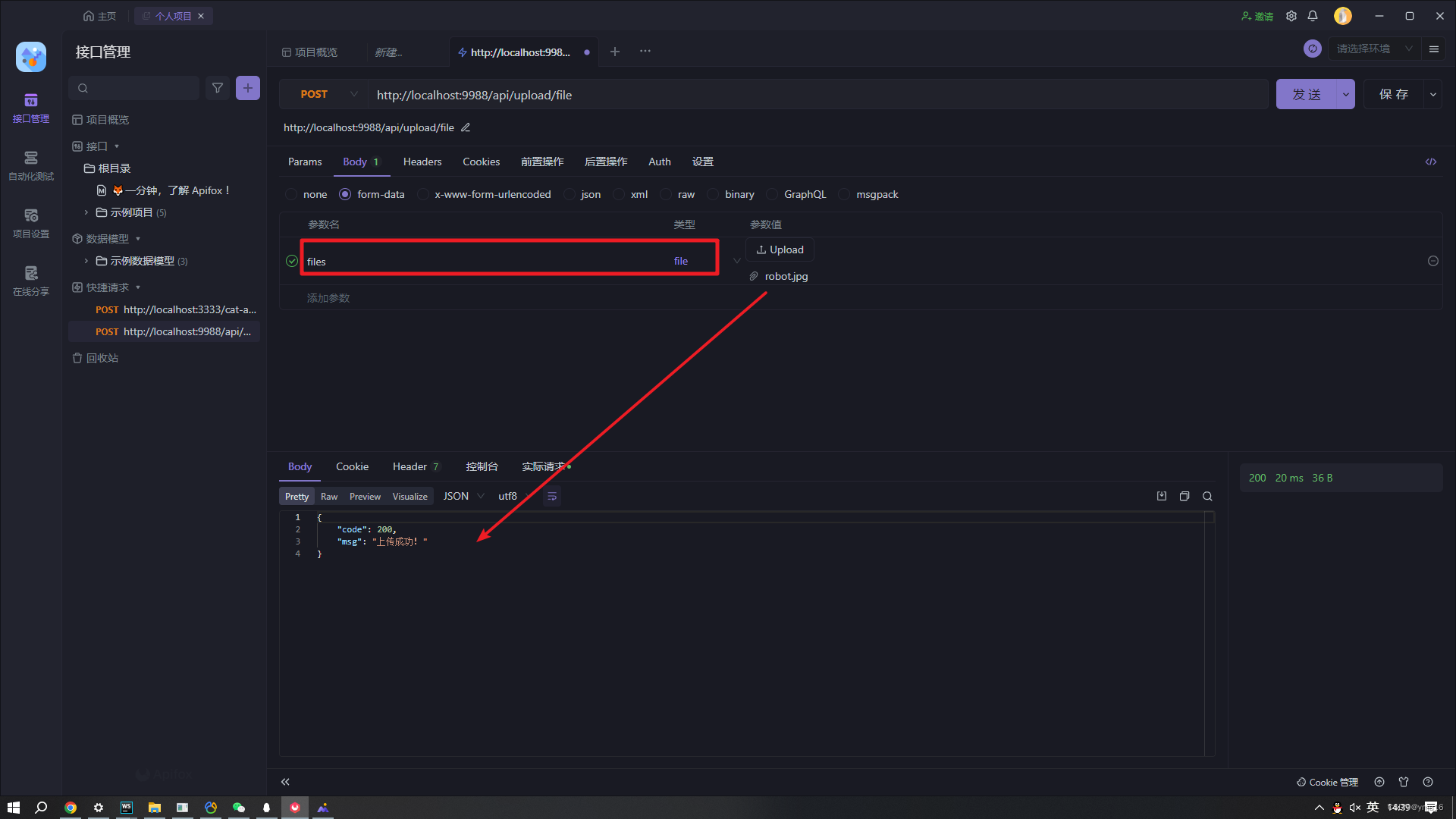
vue3+threejs+koa可视化项目——模型文件上传(第四步)
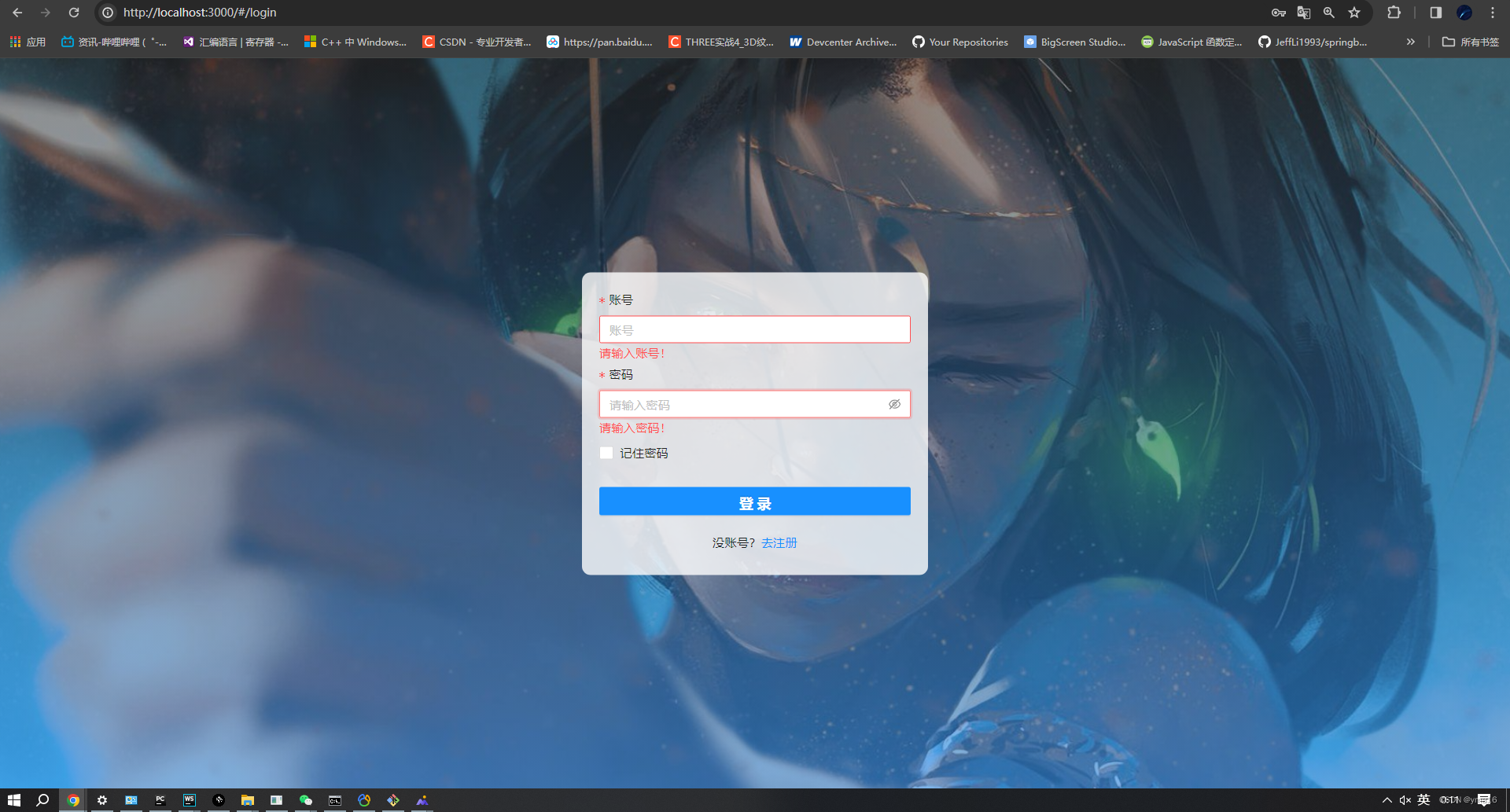
vue3+threejs+koa可视化项目——实现登录注册(第三步)
深入学习Synchronized各种使用方法
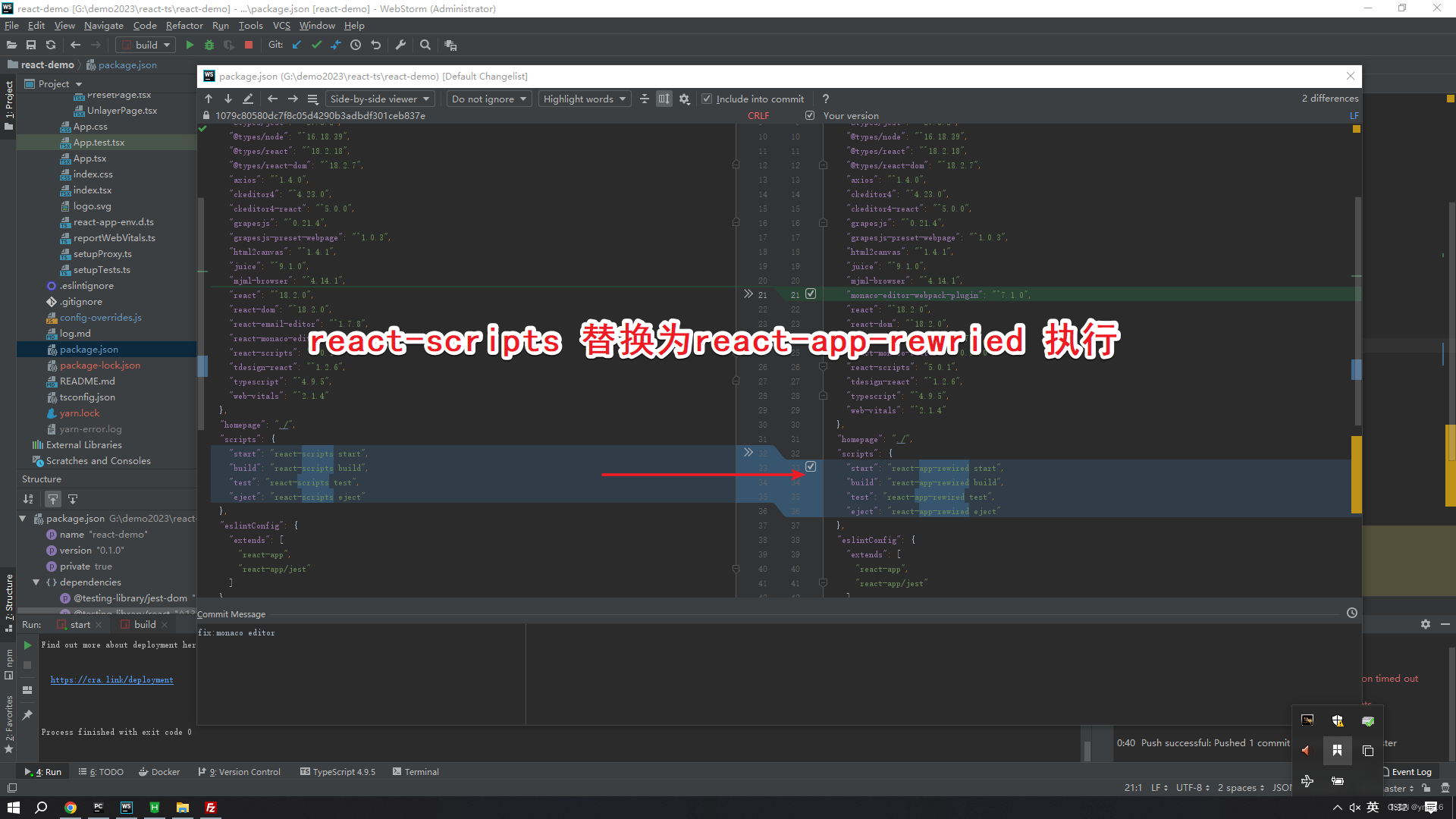
react-app框架——使用monaco editor实现online编辑html代码编辑器
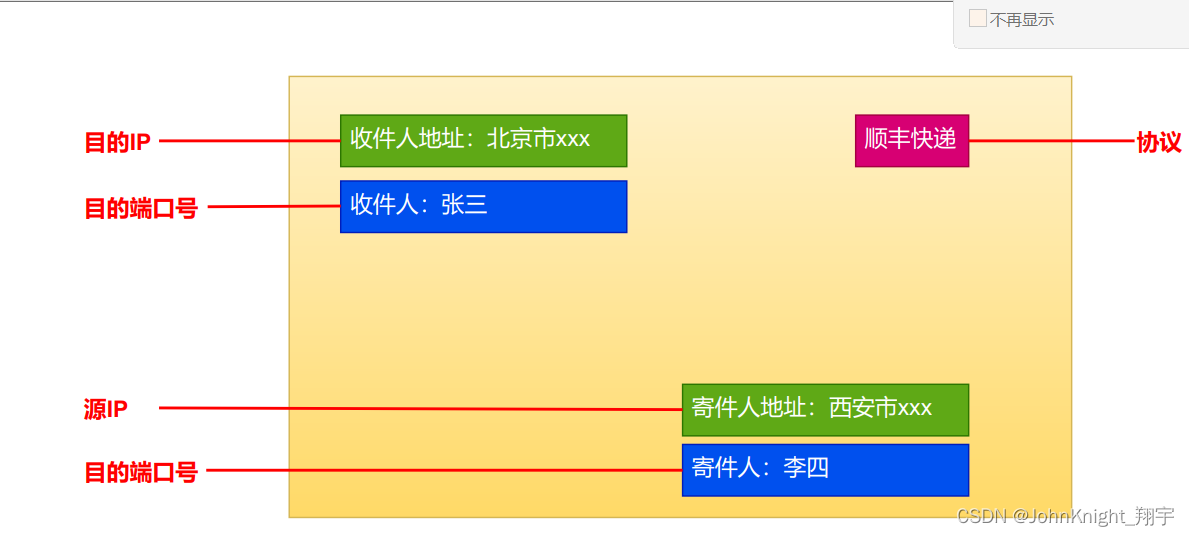
TCP/IP五层(或四层)模型,IP和TCP到底在哪层?
ISO 专家解读 | 什么是 GQL 国际标准图查询语言
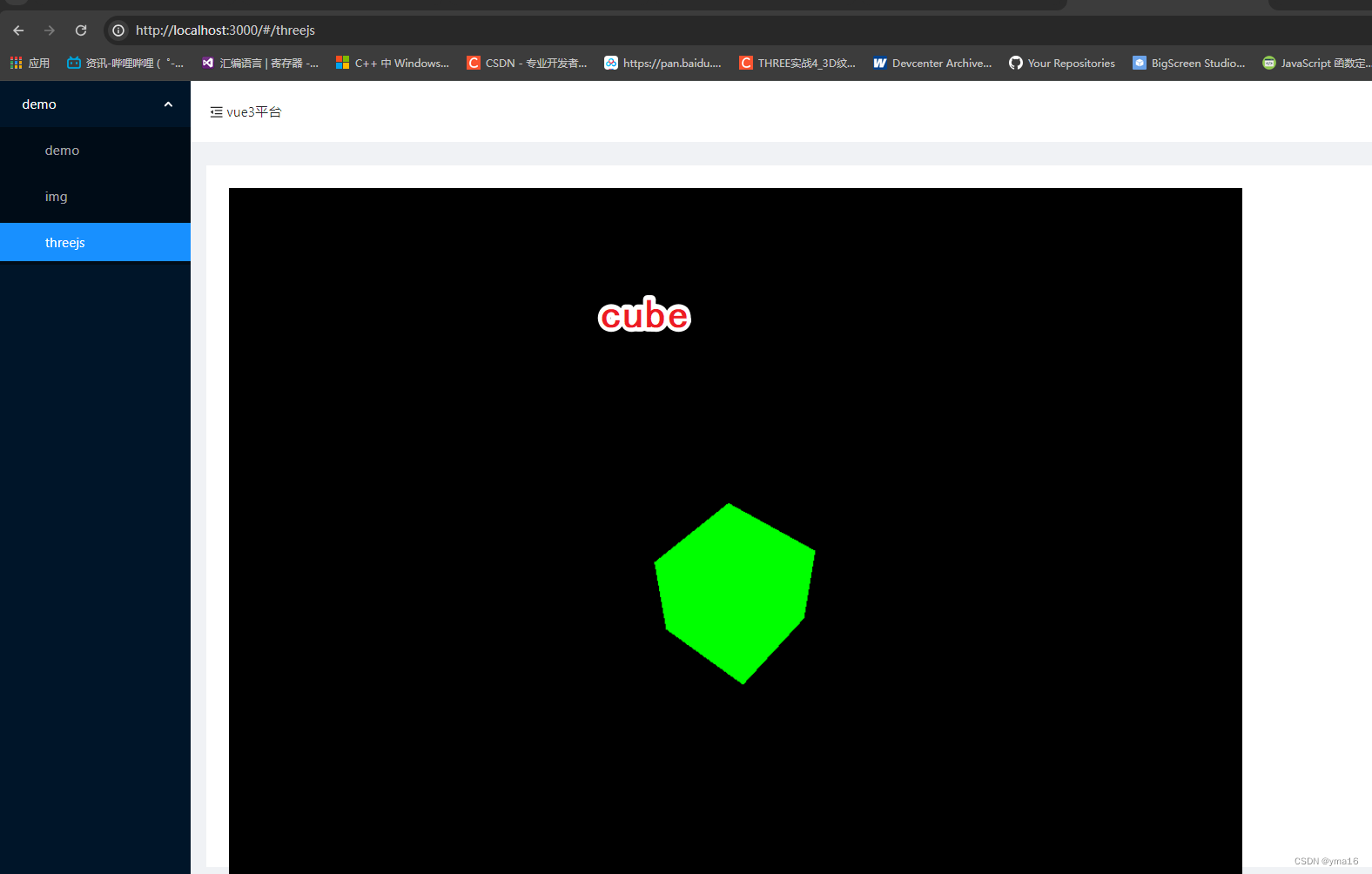
vue3+threejs可视化项目——引入threejs加载钢铁侠模型(第二步)
网络初识:局域网广域网&网络通信基础
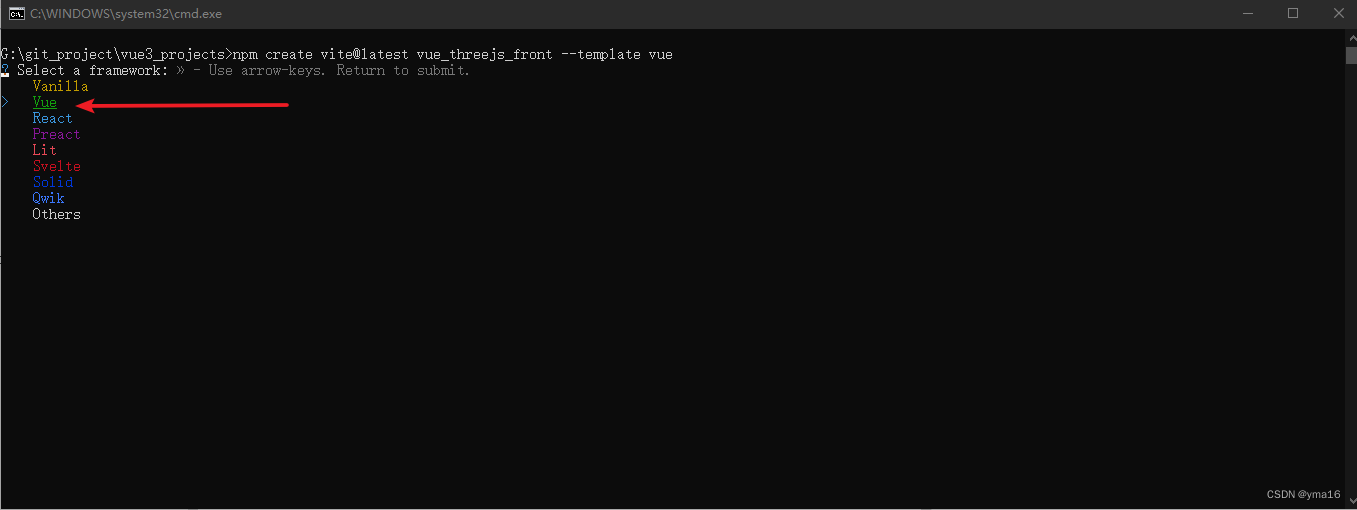
vue3+threejs可视化项目——搭建vue3+ts+antd路由布局(第一步)
前端舞台上的优雅独舞:代码规范的奥秘
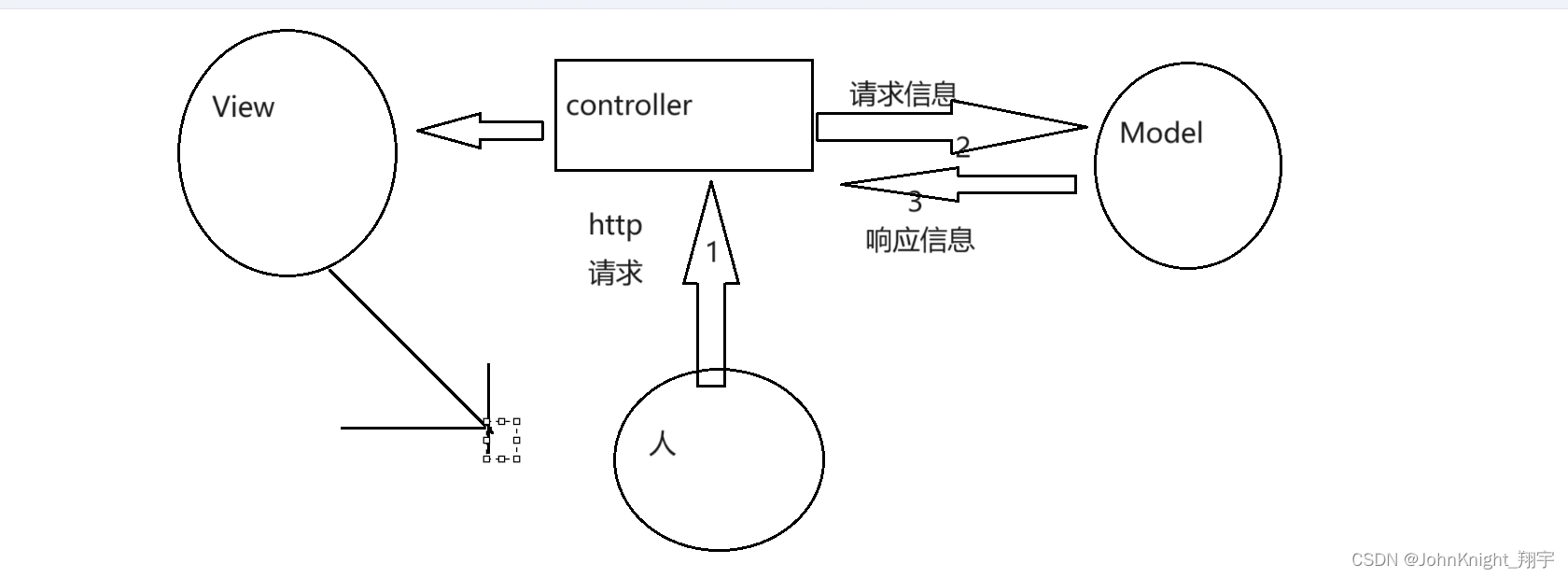
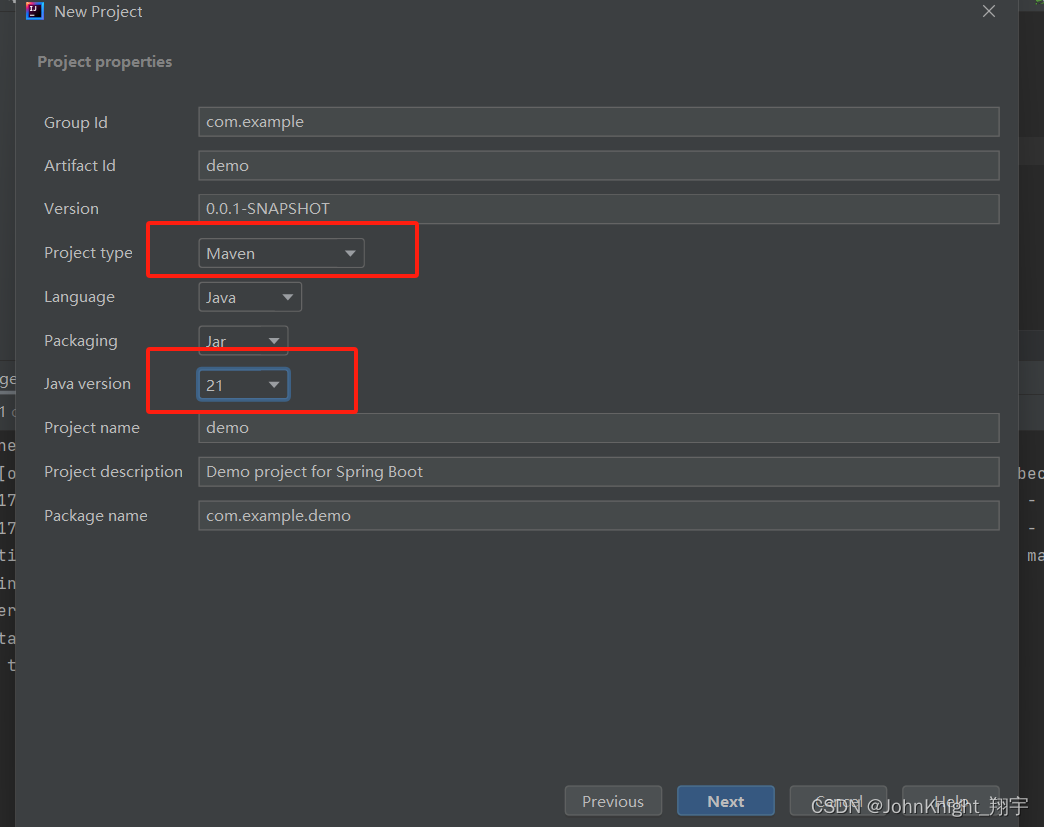
SpringBoot:SpringMVC(上)
前端宝藏图:寻找技术之旅的星辰大海
VueX解耦:前端开发的音乐大师
Node.js在前端的妙用:打造更出色的Web体验
Vue 项目中的权限管理:让页面也学会说“你无权访问!
【SpringBoot】讲清楚日志文件&&lombok
UniApp状态管理:从深入理解到灵活运用
深度学习在图像识别中的应用和挑战
UniApp 中的路由守卫与拦截器:守护应用的每一步
代码之禅:高效编程的艺术
UniApp 中的路由魔法:玩转页面导航与跳转
探索云原生架构:为企业数字化转型插上翅膀
灯光开不了了,是不是NVIDIA的问题
UniApp 项目中的生命周期详解:从诞生到逝去
从零开始:UniApp 项目搭建指南
MyBatis的创建,简单易懂的一篇blog
解锁网页布局的秘密武器:探索 CSS Grid 布局的神奇魔力
遍历指南:JavaScript 中的 for、for-in、for-of 和 forEach 循环详解
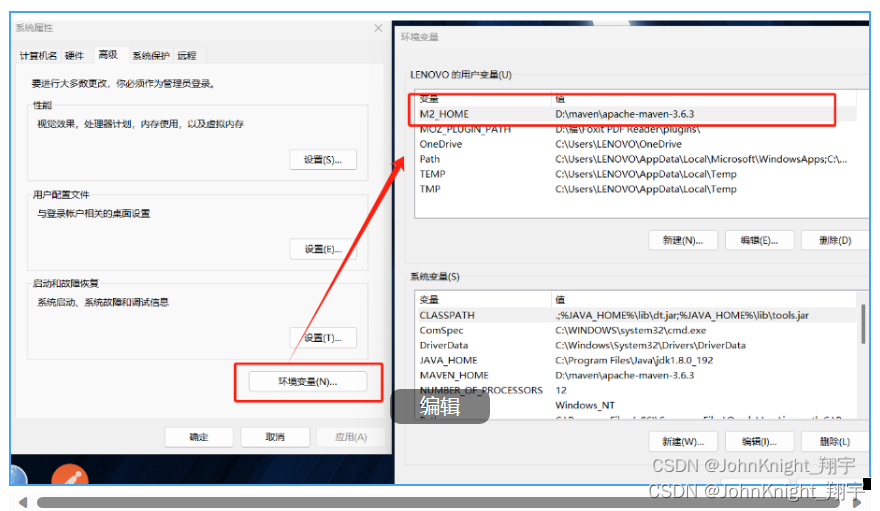
Maven的配置亲测有效
探索未来:2024年前端技术趋势解读
服务器数据恢复—Storwize V3700存储数据恢复案例
深度学习在图像识别中的应用与挑战
绚丽多彩的网页世界:深入探讨CSS动画的艺术与技巧
生命中的开关:深入探讨Deactivated和Activated生命周期
Python数据科学之旅从基础到深度学习
深度解析Vue中的插槽机制:打开组件设计的无限可能
深入了解Webpack:前端模块打包工具