HBase用户福利
新用户9.9元即可使用6个月云数据库HBase,更有低至1元包年的入门规格供广大HBase爱好者学习研究,更多内容请参考链接
概览
BDS针对开源HBase目前存在的同步迁移痛点,自主研发的一套数据迁移的平台。有关于BDS的基本介绍,可以查看《BDS-HBase数据迁移同步的利器》。本文主要介绍目前在阿里云上,BDS是如何进行HBase集群之间的数据迁移和数据的实时同步的。
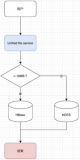
架构

- BDS采用分布式的架构,由BDSMaster节点生成、调度任务给各个BDSWorker节点
- BDSWorker节点负责具体的任务执行,是无状态的,方便扩容、升级
- Reader 和 Writer 插件化,支持跨版本,异构数据源的迁移和实时数据同步
历史数据迁移方案
对于历史存量数据的迁移,我们是通过拷贝文件的方式,将数据文件拷贝到目标集群,然后统一对文件进行Bulkload,将数据装载到目标表中
迁移流程:
- 客户提交历史数据迁移的任务
- BDSMaster获取原表的Region分区情况,针对每一个Region分区生成一个Task,平均下发给各个BDSWorker节点
- BDSWorker节点接收到Task任务之后,会迁移指定Region分区下的HFile文件,HFile的拷贝走的是字节流的拷贝,并且能够自动处理Region的Split、Merge、Compaction等操作导致HFile文件的变化,保证文件迁移过程中的不丢失
- BDSMaster在迁移过程中会对各个BDSWorker上执行的任务进度、详情进行监控,对于超时的任务,异常任务进行重试
- 所有的任务都迁移完成之后,BDSMaster会通知目标集群进行数据的装载,将数据装载到目标表中
BDSWorker 宕机的处理
BDSMaster通过ZK监听各个BDSWorker的状态,当某个BDSWorker宕机,BDSMaster会将宕机BDSWorker上正在执行的Task,重新下发给其他的BDSWorker,其他BDSWorker接收到重试的Task,会从中断的地方开始重试,防止重复迁移已经迁移完成的数据
对Region的Split、Merge、Compaction的处理
Region的Split、Merge、Compction会导致HFile文件在迁移的过程中不断的发生的变化
- 某个文件在迁移的时候被Compaction合并了,文件就不存在了
- 某个Region在迁移的时候发生了split,Region不存在了
- 迁移的时候HFile是个引用文件,不包含实际的数据,只是对源文件的引用
针对HFile文件是个引用文件、HFile文件被合并了,BDSWorker会自动处理,保证数据的不丢失,针对Region的Split、Merge,BDSMaster会感知原表的变化,获取新生成的Region生成新Task,下发给BDSWorker去执行
Bulkload优化

数据文件拷贝完成,在对数据进行装载的时候需要对HFile排序、切分和分组,当原表和目标表的分区很不一致,就会导致大量的HFile被切分,从而影响bulkload的速度。
因此,我们在拷贝文件的时候BDS会自动对要分区的文件进行拆分,在Bulkload的时候就可以直接load各个HFile文件到对应的Region分区中。
数据本地化率的优化

数据迁移完,RegionServer在读取文件数据的时候,可能存在大量的远程读(数据不落在本地的DN上,需要访问远端的DN),会导致读RT变高。
BDS在迁移文件的时候,会尽可能的将数据写到对应RegionServer所在的DN上。
BDS vs 开源方案
- 在迁移过程中,几乎不会和集群的HBase交互,只和集群的HDFS进行交互,尽可能的避免了对在线业务的影响
- 文件的迁移走的是文件字节流的拷贝,因此比通常API层的数据迁移通常能节省50%以上的流量
- 迁移不需要修改源集群目标的配置,也不需要在集群上做什么操作,不占用HBase集群的存储、计算、内存等资源
- 数据迁移考虑本地化率,可以保证迁移完之后目标集群有更好的读rt
- 迁移的文件根据目标表的分区情况自动拆分,大大提高了大表数据装载的速度
- 有完善的failover机制,支持异常任务重试,断点续传
- BDSWorker无状态,升级、扩容非常容易,便于运维
- 支持配置的热更新,可以设置每个BDSWorker启动的线程数以及每个线程迁移的速度
实时数据同步方案

- BDSMaster会不停扫描源集群HDFS上的日志
- 针对新生成的log会生成对应的Task,下发给各个BDSWorker
- BDSWorker针对每个Task,会创建TaskTunnel,TaskTunnel 包含 Reader、Queue、Writer,Reader 负责读取 log并将读取的log数据丢到queue中,writer异步消费queue中的数据发往目标集群
支持跨版本、异构数据源的实时数据同步

TaskTunnel中的Reader和Writer我们采用的是插件化的方式,针对不同的源端和目标端,我们使用对应版本的Reader和Writer,BDS不仅支持跨版本HBase的同步,甚至支持异构数据源的数据同步
抗热点

对于原生的HBase Replication来说,写热点的RegionServer会生成更多的日志,同步压力也会更大,往往会导致这台RegionServer的数据同步不过来。遇到热点的问题,你可以用一些运维的方式去解决。比如从热点服务器移走Region,降低吞吐与负载,但热点并不保证是恒定的,可能会跳跃在各个服务器。

对于BDS,由BDSMaster统一获取源集群的日志,然后平均分配给各个BDSWorker,因此每个BDSWorker处理的日志数量基本是相同的。即使源集群RegionServer存在写热点,但热点RegionServer的日志也能被平摊到各个BDSWorker去执行,从而避免因热点导致的同步延迟。
同步积压
HBase Replication

对于HBase Replication来说,同步逻辑是集成在RegionServer中的,因此数据的同步和RegionServer本身的读写相互影响,又因为HBase服务于客户端的线程数,要远远大于Replication的线程数。面对高负载的写场景数据复制基本很难消化庞大的写吞吐,就会导致同步积压。面对数据的同步积压,通过开大线程数量不一定能解决问题,因为RegionServer此时的负载可能已经很高了。也不太容易通过横向扩展节点来解决同步积压的问题,因为扩展节点我需要扩展RegionServer节点以及DataNode节点,只能在业务低峰期的时候慢慢的消费。
BDS

对于BDS来说,BDS采用读写异步的方式,可以通过以下几种方式来解决同步积压的问题
- 增加BDSWorker节点,来提高整个迁移服务的吞吐
- 动态配置每个BDSWorker处理日志的线程数,来提升单个节点日志处理的并发度
- 动态配置每个TaskTunnel的Writer数量,从而提升单个日志的处理吞吐
同步监控

对于同步的监控,我们定义
同步延迟 = 数据被同步到目标集群的时间t2 - 数据被写入到源集群的时间t1
≈ 读延迟 + 读耗时 + 在队列等待耗时 + 写耗时读延迟:表示数据被写入HDFS上的HLog到我们从读取的HDFS上读到这条数据的时间间隔
读耗时:从文件中读取一批数据的耗时
队列等待时间:数据被读出来添加到队列中的等待时间
写耗时:数据被写入到目标集群的耗时
我们需要监控这几项指标,就能比较方便的定位同步过程中的问题
当写耗时增大,我们可以定位目标集群可能存在了一些问题或者网络存在问题
当队列等待的耗时较大,说明写入速度赶不上读取的速度,我们可以通过适当增加写线程数量,来提高写速度
读耗时变大,我们就能定位读取HLog存在一些问题,可能是网络延迟变大
读延迟不断变大,我们就可以定位BDS同步吞吐不够,同步不过来了,需要添加节点,调整同步并发
BDS vs HBase Replication
-
功能性
- 支持跨版本的同步
- 支持双向同步、环状同步
-
稳定性
- 抗热点,同步的任务平均分配到各个BDSWorker节点
-
对业务影响更小
- 独立于HBase,不受RegionServer读写影响
- 同步过程基本不会访问源HBase集群,只读取源HDFS上的日志
- 可以控制同步的线程数和节点的并发数
- 更加完善的failover机制
-
易运维
- BDSWorker stateless,便于扩展、系统升级
-
完善的监控、报警机制
- 监控同步时延,上下游流量,读写耗时等指标
- 任务失败,延迟过大报警
-
性能
- 可以通过扩展节点数量来提升迁移同步的速度
- 支持动态配置线程数
- 读写异步
总结
BDS已经在阿里云上线了,方便云上的客户在自建HBase、EMR HBase、Apsara HBase集群之间的无缝迁移,集群的升配,主备容灾,能够支持PB级别数据量的集群搬站。
云上有迁移需求的客户,可以查看《BDS服务介绍》,或者联系侧田
HBase技术交流
欢迎加群进一步交流沟通: