雷锋网 AI 科技评论按:在计算机视觉领域,图像分类其实是一个最基本的问题,然后一旦遇到极端长尾、开放式的数据集时,即便是最基本的图像识别任务,也难以很好地实现。伯克利 AI 研究院基于对某段相关的经历的思考提出了「开放长尾识别」(OLTR)方法,据介绍,该方法可同时处理庞大、稀有、开放类别的视觉识别,是目前视觉识别系统评价中更全面、更真实的一种检验标准,它可以被进一步扩展到检测、分割和强化学习上。这一成果也在伯克利 AI 研究院上进行了发表,雷锋网(公众号:雷锋网) AI 科技评论编译如下。
现有的计算机视觉环境 VS 现实世界场景
有一天,一位生态学家来找我们。因为他用摄像机拍摄了很多野生动物的照片,希望运用现代计算机视觉技术,基于这些照片的数据库自动辨识拍到了哪些动物。这听起来是一个基本的图像分类问题,所以我们当时很自信,觉得肯定没问题。然而结果我们却失败了。那位生态学家提供的数据库是极端长尾且开放式的。通常,只要无法得到足够的训练数据,我们就会问对方,有没有可能提供更多的尾部类别数据,而忽略可能在测试数据中出现的一些开集类别。遗憾的是,要解决那位生态学家的问题,我们无法采用收集更多数据的做法。由于这些生态学家可能要花相当长的时间,才会在野外拍到他们计划拍摄的珍稀动物。为了拍到一些濒危动物,他们甚至必须等几年才能拍到一张照片。如此同时,新的动物物种不断出现,旧的物种同时正在消失。在这样一个动态变化的系统之内,类别的总数永远无法固定。而且,从动物保护的意义上说,识别新发现的稀有动物比识别数量还很多的动物更有价值。如果我们只能在数量众多的类别中很好地识别动物,那我们的方法永远都不会有什么实用价值。我们尝试了所有可能采用的方法,能想到的都试过了,比如数据增强、采样技术、小样本学习、不平衡分类,但没有一种现有的方法可能同时处理庞大的类别、稀有的类别和开放的类别(如图 1)。

图1:现有的计算机视觉环境和现实世界的场景差距相当大。
自此以后,我们就一直在思考,现有的计算机视觉方法和现实世界的场景存在这么大的差距,最主要的原因是什么?不止是野生动物摄影数据存在这样的问题,在现实生活中,这种问题一再出现,工业和学界都有。假如卷积神经网络可以在庞大的 ImageNet 图像数据集中非常顺利地将图片分门别类,那为什么在开放的世界中却仍然无法解决图片分类的问题?在视觉识别领域,几乎所有的问题都有成功的解决之道,如小样本学习和开集识别。可似乎没有人把这些问题当作一个整体来看待。在现实世界的应用中,不论是头部类别还是尾部类别,分类有时不止面临单独一种问题。因此,我们认为,这种理论和实践的差距可能源于视觉识别设置自身。
开放长尾识别(Open Long-Tailed Recognition,OLTR)
在现有的视觉识别环境中,训练数据和测试数据在封闭世界(比如 ImageNet 数据集)的设置下都是均衡的。但这种设置并没有很好地模拟现实世界的场景。例如,生态学家永远都无法收集到均衡的野生动物数据集,因为动物的分布是不均衡的。同样地,从道路标示、时装品牌、面孔、天气环境,到街道环境等等,各种类型数据集的不均衡开放分布都会干扰人。为了如实地反映这些方面,我们开始正式研究源自自然数据集的「开放长尾识别」(OLTR)。一个实用的系统应该能够在少数共性的类别和多个稀有类别之中分类,从极少数已知的例子之中总结归纳单独一个类别的概念,基于某个过去从未见过的类别存在的一个例子,去了解这个类别的独特性。我们将 OLTR 定义为,从长尾和开放的分布式数据中学习,并且基于一个平衡测试数据集评估分类的准确性,而这个测试数据集要包括在一个连续谱内的头部、尾部和开集类别(如图 2)。

图2:我们这个开放长尾识别的问题必须从一个开放世界的长尾分布式训练数据中学习,处理整个谱的不平衡分类、小样本学习和开集识别。
OLTR 并没有局限于字面上的定义,目前有三个问题和它密切相关,分别是不平衡分类、小样本学习和开集识别,通常人们都是孤立地看待它们,分别独立研究。图 3 概括了它们之间的差异。在评估视觉识别系统方面,新提出的 OLTR 可以成为更广泛、更现实的检验标准。
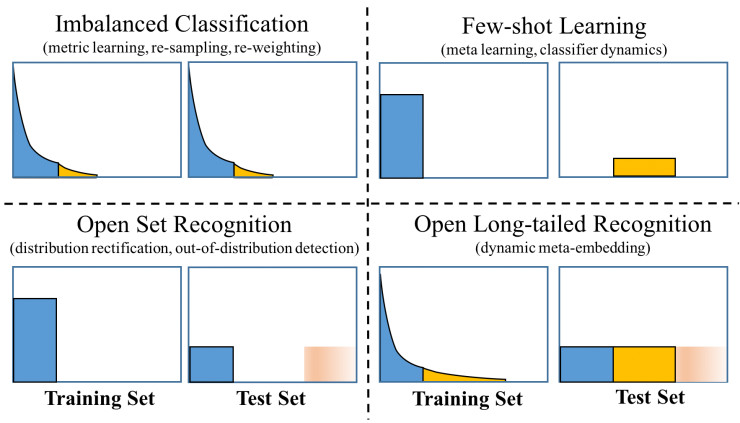
图3:不平衡分类、小样本学习、开集识别和开放长尾识别(OLTR)之间的差异。
注意力 & 记忆的重要性
我们提出将图像映射到一个特征空间,这样,视觉概念之间可以基于学习到的度量相互关联,并且这种度量既认可了封闭世界分类又承认了开放世界的新颖性。我们所提出的动态元嵌入层结合了直接图像特征和关联的记忆特征,同时,特征范数表示了对已知类别的熟悉程度,如图所示 4。
首先,我们通过聚集源自头部类别和尾部类别的知识获得了视觉记忆;然后将存储在内存中的视觉概念当作关联的记忆特征重新注入,以增强原来的直接特征。我们可以将其理解为利用诱导知识(即记忆特征)来帮助实现直接观察(即直接特征)。我们进一步学习了一个概念选择器来控制所要注入的记忆特征的数量和类型。由于头部类别知识已经获得了丰富的直接观察,所以它们只被注入了少量的记忆特征。相反,尾部类别获得的观察很少,于是记忆特征里的关联视觉概念就非常有用。最后,我们通过计算出获得视觉记忆的可达性,来调整开放类别的可信度。
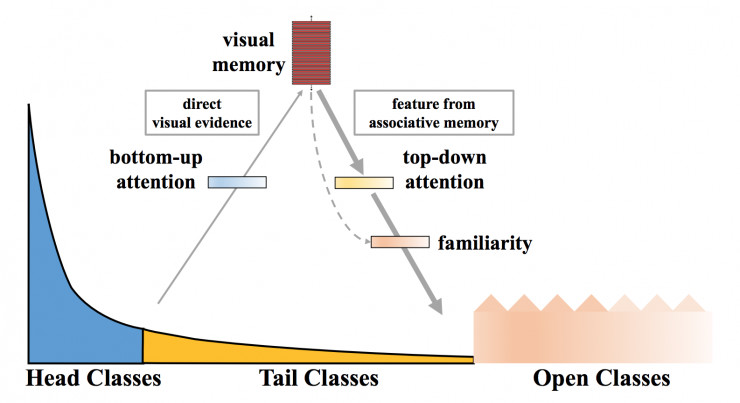
图4:关于文中方法的直观解释。我们提出的动态元嵌入层将直接图像特征和联想记忆特征结合在一起,用特征范数表示对已知类的熟悉度。
全面提升
如图 5 所示,本文方法对所有的多/中/小样本类别以及开放类别进行了综合处理,在各方面都取得了实质性的提升。

图5:本文方法相对于普通模型的绝对 F1 分数。本文方法在多/中/少量类别以及开放类别上取得了全面进步。
学习动态可视化
这里,我们通过将头部的激活神经元可视化,检查了记忆特征注入的视觉概念,如如图 6 所示。具体来说,对于每个输入图像,我们识别出了它在记忆特征中排名前 3 的迁移神经元。所有神经元都通过整个训练集上最高的一组激活补丁实现可视化。例如,为了将左上角的图像划分为尾部类别「公鸡」,我们的方法已经学会了依次迁移表示「鸟头」、「圆形」和「点状纹理」的视觉概念。在注入特征后,动态元嵌入层的信息丰富度和识别度变得更高。

图6:记忆特性里排前三的注入视觉概念案例。除了右下的失败情况(标记红色),其他 3 个输入图像都被普通模型错误分类,被我们的模型正确分类。例如,为了对属于尾部类别「公鸡」的左上角图像进行分类,本文方法学会了分别迁移表示「鸟头」、「圆形」和「点状纹理」的视觉概念。
重返现实
现在让我们回到真正的丛林,将我们在本文中提出的方法应用到生态学家在第一部分提到的野生动物数据中。幸运的是,我们的新框架在不牺牲丰富类别的情况下,在稀缺类别上获得了实质性的进步。具体而言,在图像数量少于 40 的类别上,我们让结果提升了大约 40%(从 25% 到 66%)。并且,在开放类别检测上,我们让结果提高了 15% 以上。
我们相信,在开放长尾识别环境下开发的计算方法最终可以满足自然分布数据集的需要。综上所述,开放式长尾识别(OLTR)是视觉识别系统评价中更全面、更真实的一种检验标准,它可以被进一步扩展到检测、分割和强化学习上。
致谢:感谢论文《开放世界中的大规模长尾识别》的所有共同作者在撰写这篇博文中所做的贡献和讨论。本文中所表达的观点均属于本文作者。
此博文基于将在 IEEE 计算机视觉和模式识别会议(CVPR 2019)作口头陈述的论文,如下:
《开放世界中的大规模长尾识别》(Large-Scale Long-Tailed Recognition in an Open World)
作者:Ziwei Liu*, Zhongqi Miao*, Xiaohang Zhan, Jiayun Wang, Boqing Gong, Stella X. Yu
Paper:https://arxiv.org/abs/1904.05160
Project Page:https://liuziwei7.github.io/projects/LongTail.html
Dataset:https://drive.google.com/drive/folders/1j7Nkfe6ZhzKFXePHdsseeeGI877Xu1yf
Code & Model:https://github.com/zhmiao/OpenLongTailRecognition-OLTR
via https://bair.berkeley.edu/blog/2019/05/13/oltr/ 雷锋网 AI 科技评论报道