本篇开始,就进入到了asr当前的流行做法。 这里单独提到了CTC算法。 这个算法对当前asr使用deep learning的方法有重大影响。
总体感觉,写到本篇,工作量反而变得很小。因为进入deep learning时代后,神经网络模型基本都是那么几种,已经不再需要挨个详细介绍。而且看图就能理解的很明白。 所以本篇后半部分基本就是贴图了。。:D
一、CTC
在CTC之前,训练语料要配合上一篇中提到的方法,需要人工把音频中每个时间段对应的是哪个音素的信息标注清楚。 这个工作量和对人及金钱的需求是巨大的。基本都是百万级别手笔。 有个CTC之后, 给定一个音频,就只要告诉这个音频说的是什么文本就好了。 省掉了对齐的那一步。 由此,其重要性可自行判断。
关于CTC,感觉与其这里坑坑洼洼的介绍,不如直接参考这篇知乎的文章——https://zhuanlan.zhihu.com/p/36488476, 一看就懂。
这里就大概说明下CTC的大致原理,详情还是需要直接看下知乎的那篇文章。
CTC 大致原理
半定义性质的讲:CTC 要解决的问题是,算法输入序列的长度远大于输出序列长度的问题。语音识别问题的输入长度是远大于输出长度的,这是因为语音信号的非平稳性决定的,就比如说 “nihao”, 如果按时间片切分,就变成了"nnnnn iiiiii hhh aaa oo" ,但不论怎么表达,这句话最后的标签都是 “nihao”
CTC 为解决这个问题,做了两个操作:
其一是引入了blank 标签。 还记得wav音频的格式吗? 这里面声音有高峰也有趋近于0的时候。 CTC中认为, 高峰(spike)段的声音对应着音素的label,而归0的部分对应的label则是blank。 这个看起来好像没什么。
CTC引入的第二个操作是:
asr 的过程还是一帧MFCC39维向量进去,然后出一个label。 假设,“你好” 这个音频共有200个MFCC 特征帧。 这200个特征帧对应着200个输出结果,就结果空间而言,共有 音素数目^200 种可能。 而我们关心的,或者说模型训练时已知的, 就是这 所有这 音素数目^200 种可能中,可以达成 “n i h a o” 这5种结果的数目。
这里就定义了一种非常简单粗暴的映射方法——邻近去重, 比如 ,如果输出的200个结果是 {nnnniiiiii...hhhhhaaaaaooo} 那么就邻近去重 变成->{n i h a o },然后这个结果组合就是有效结果中的一种了。 而{wwwwooooocccccaaaooo} 会映射成{w o c a o} ,自然就无效的结果。
CTC认为,计算目标函数的时候,上例中的200个MFCC特征,得到的200个模型的结果, 每个小结果都对应着所有音素上的一个概率分布。 然后计算 所有能映射成 {n i h a o} 的结果的音素路径的概率值,让这个值越大越好就行了。
但是这样一来,计算量就非常的大,指数级的计算量。 CTC就使用了类似HMM推到的方法。发现求偏导进行反向传导的时候,每一帧MFCC对应的结果的导数,都可以利用前一时刻的两个状态的结果直接求到。 即 类似这样: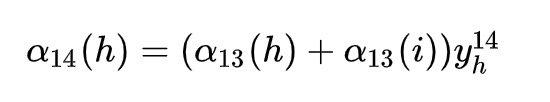
这样一来,整体计算量就急剧萎缩成了 7*T*音素个数。
使用CTC的一个展示:
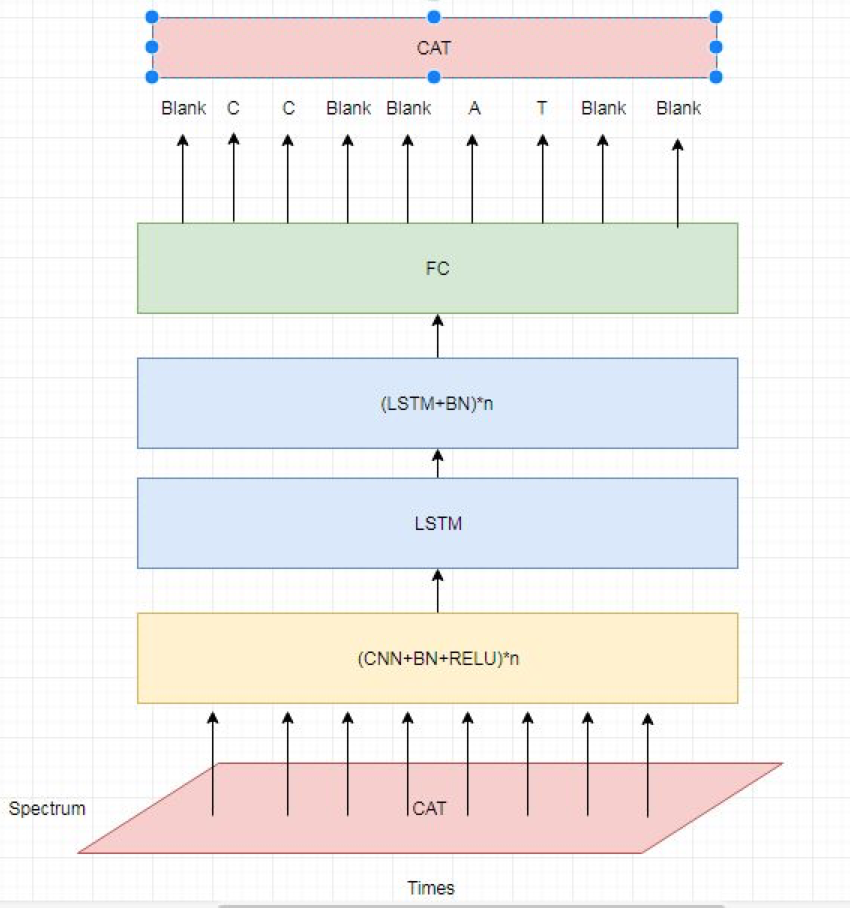
二、流行的模型
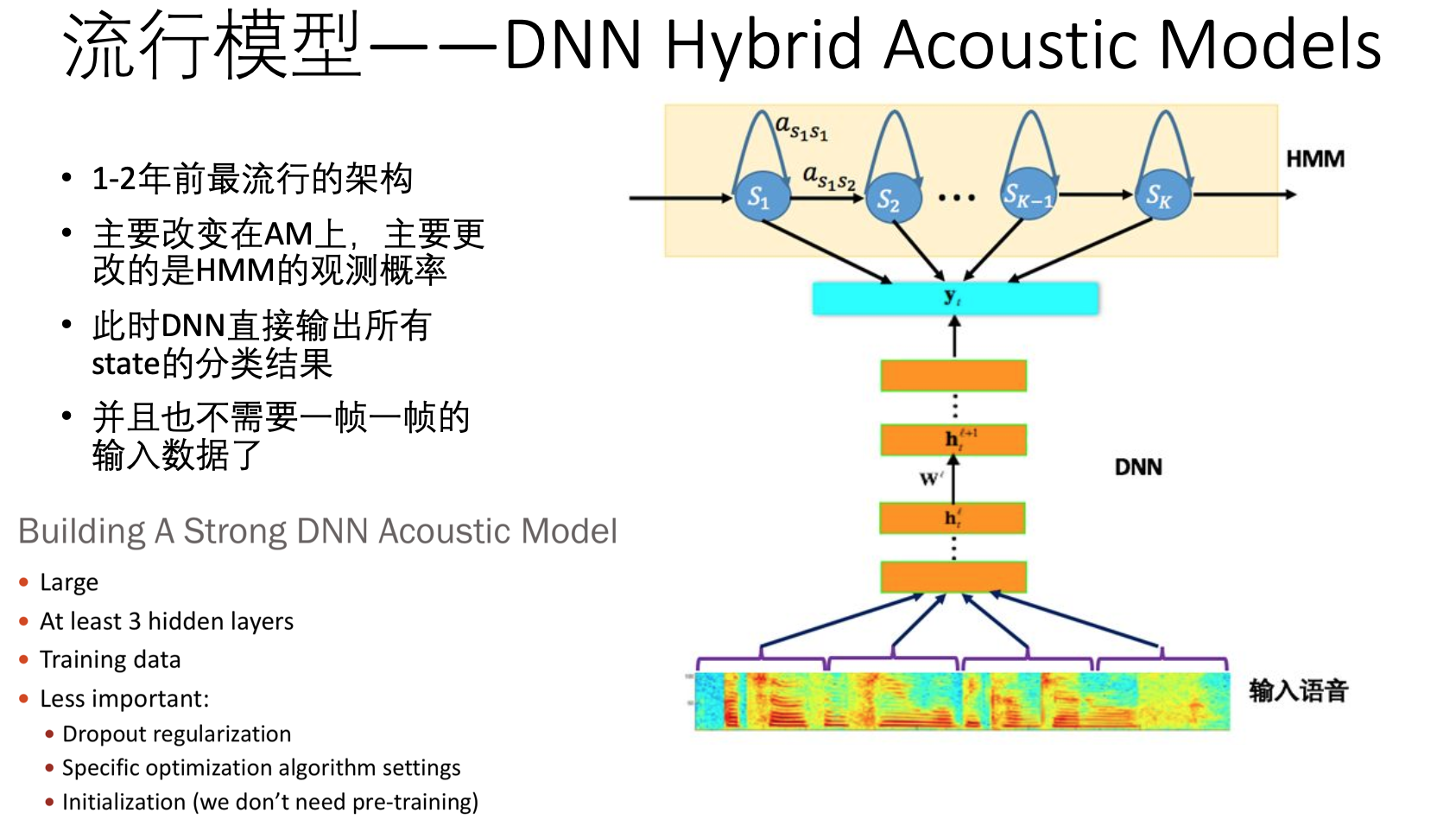
2012年,微软邓力和俞栋将前馈神经网络FFDNN(Feed Forward Deep Neural Network)引入到声学模型建模中,将FFDNN的输出层概率用于替换之前GMM-HMM中使用GMM计算的输出概率。 从这里开始, DNN-HMM混合系统的风潮起来了。
目前流行的方式大概以下几类(主要还是集中在语音模型领域,而且是直接端到端的):

1-2年前最流行的架构:
从下图模型可以看到,此时HMM仍然是主要的模型,只是把之前GMM的部分换成了DNN了。
然后,自然不能少了RNN系列的解决方案:
RNN解决方案
可以看到,最上层仍然是HMM,大致原理,基本可以直接从图中看出来。
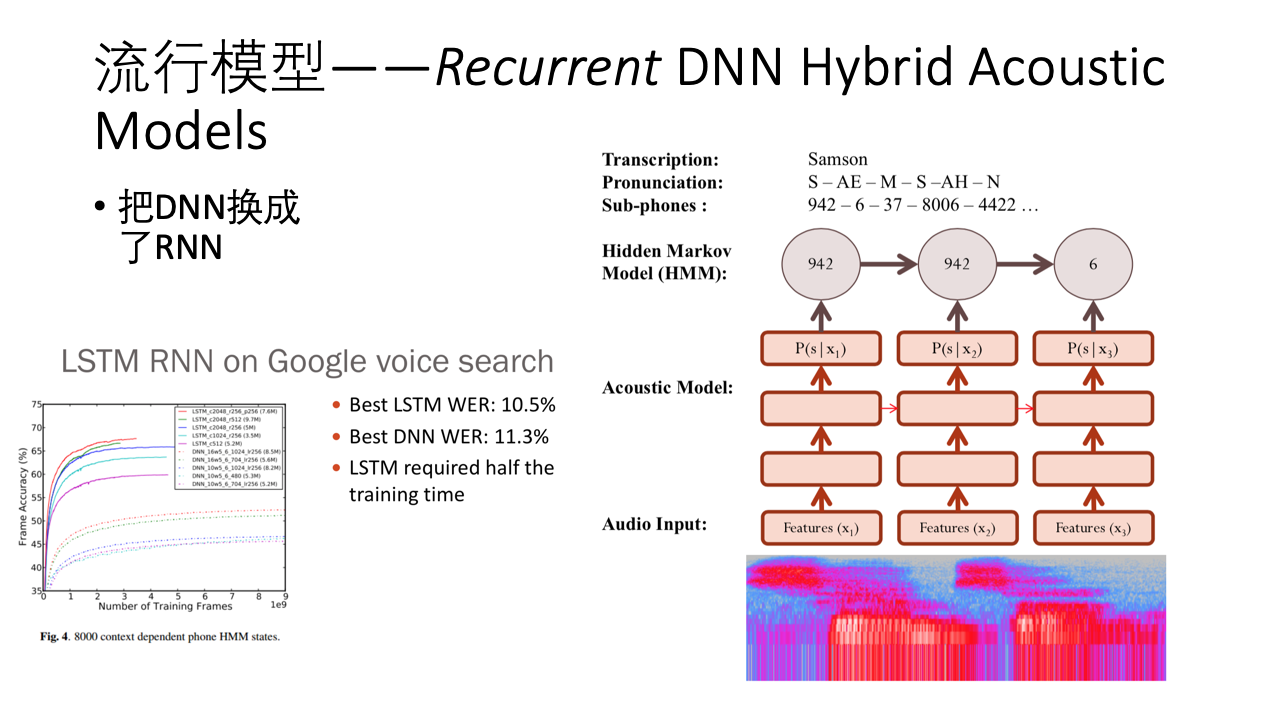
主流模型
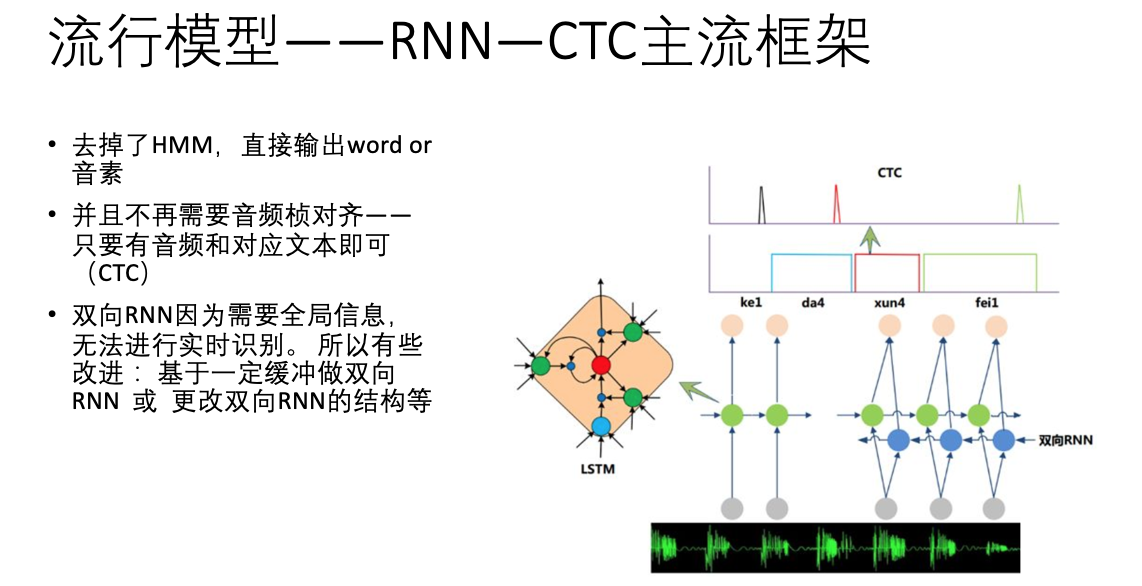
紧接着,HMM模型也给去掉了,进入了主流语音模型时代。
以下是几款流行的主要模型(以讯飞的模型居多),这个时候,已经可以直接从图上看出原理了。
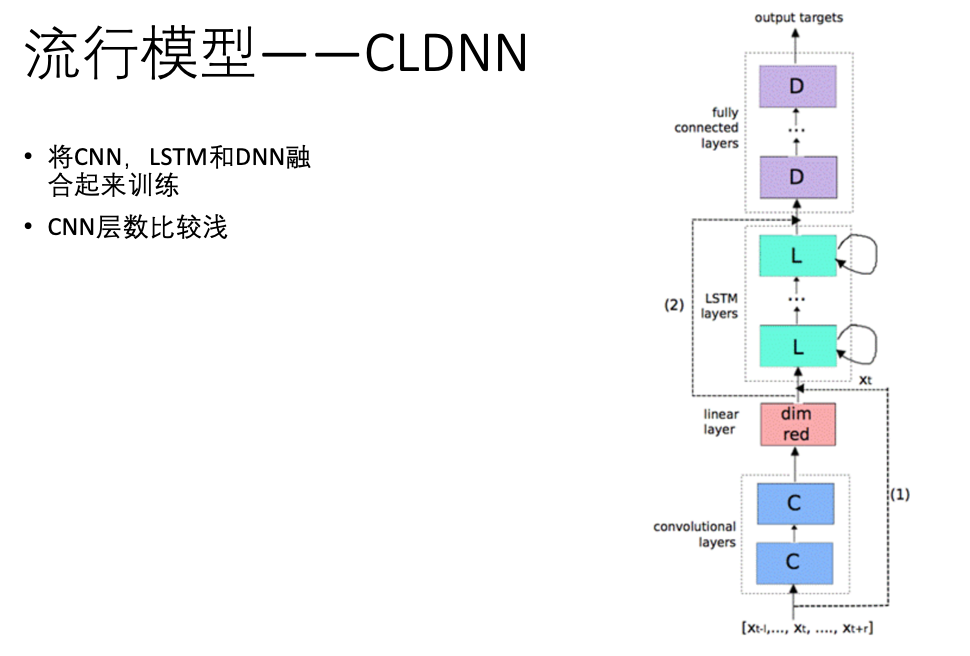

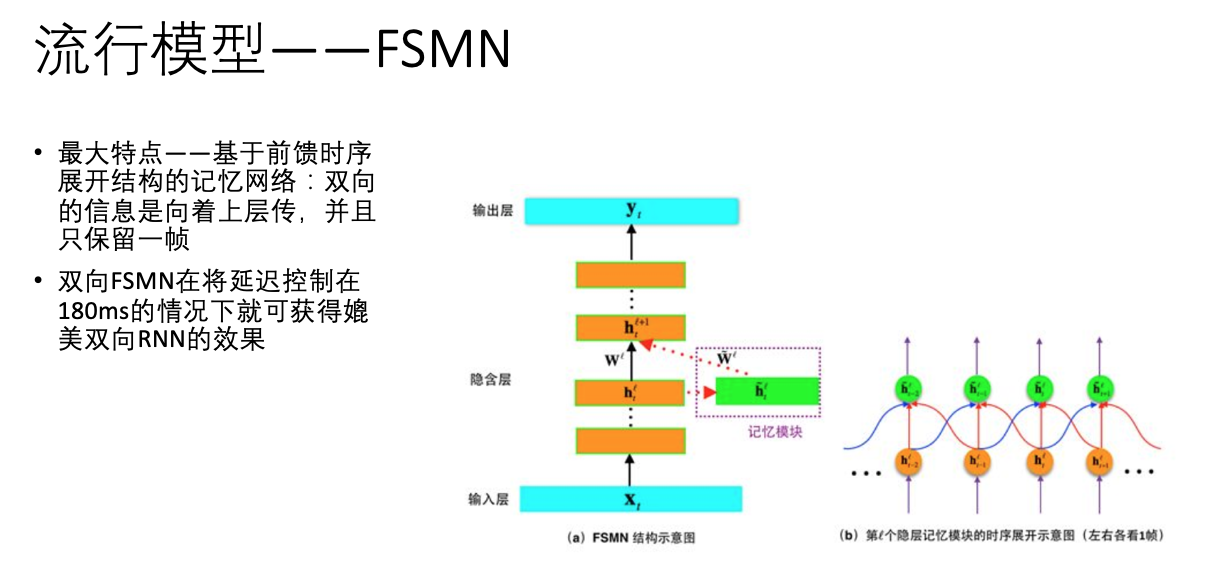
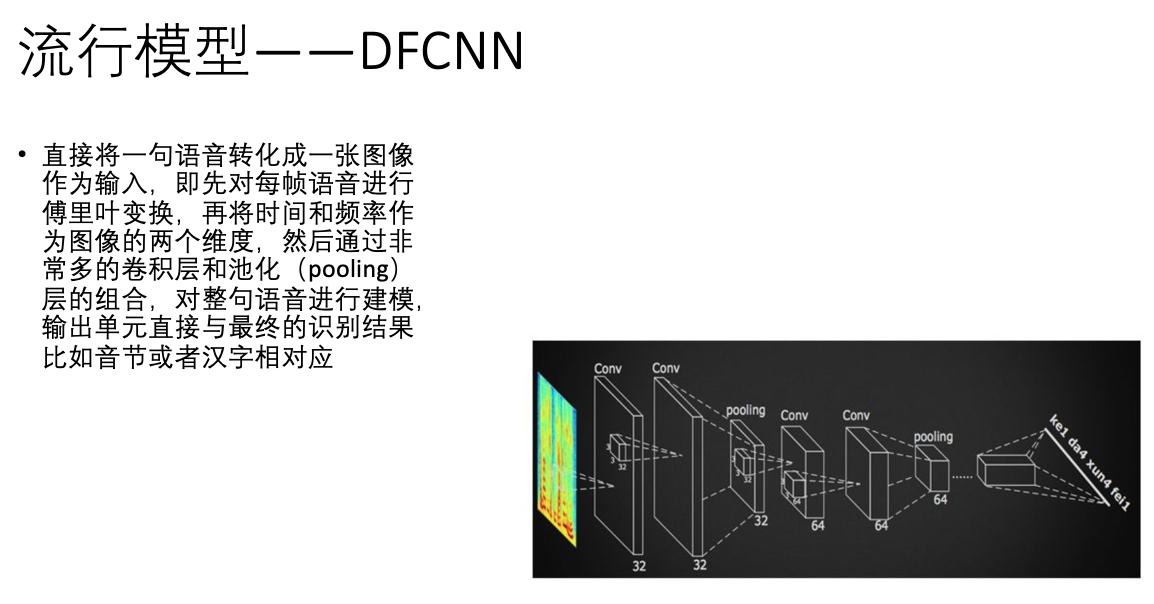
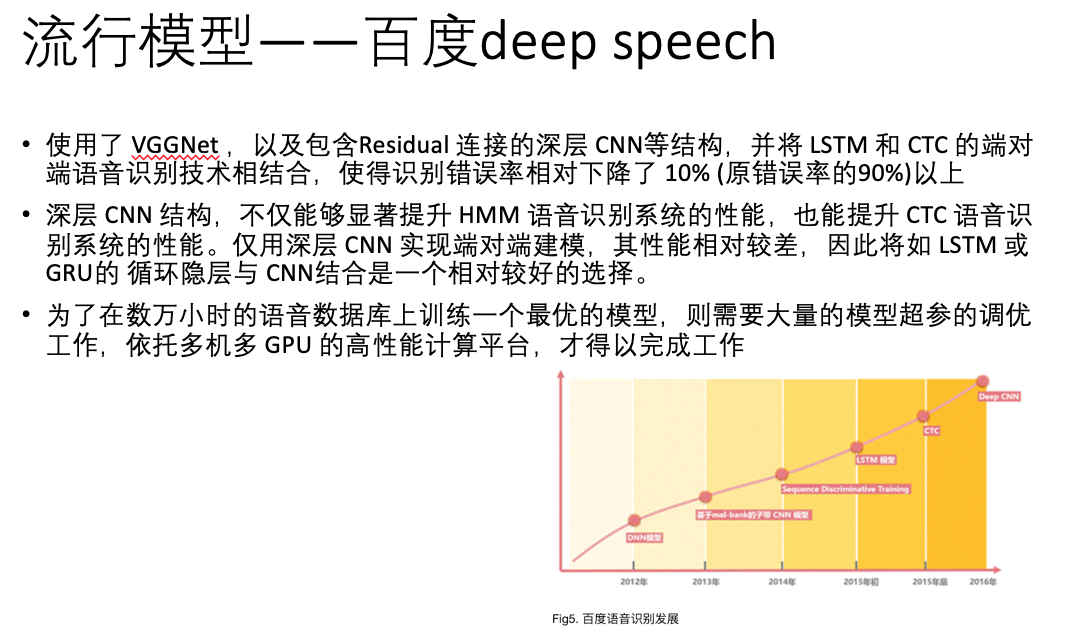
此前,百度语音每年的模型算法都在不断更新,从 DNN ,到区分度模型,到 CTC 模型,再到如今的 Deep CNN 。基于 LSTM-CTC的声学模型也于 2015 年底已经在所有语音相关产品中得到了上线。比较重点的进展如下:1)2013 年,基于美尔子带的 CNN 模型;2)2014年,Sequence Discriminative Training(区分度模型);3)2015 年初,基于 LSTM-HMM的语音识别 ;4)2015 年底,基于 LSTM-CTC的端对端语音识别;5)2016 年,Deep CNN 模型,目前百度正在基于Deep CNN 开发deep speech3,据说训练采用大数据,调参时有上万小时,做产品时甚至有 10 万小时。
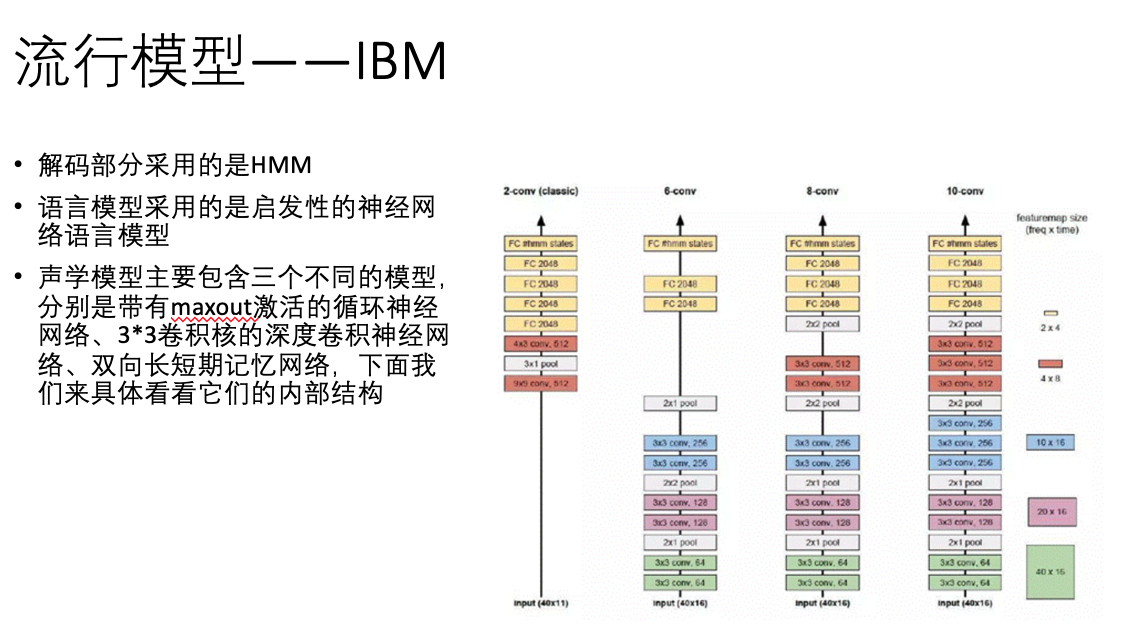
三 、其它相关技术
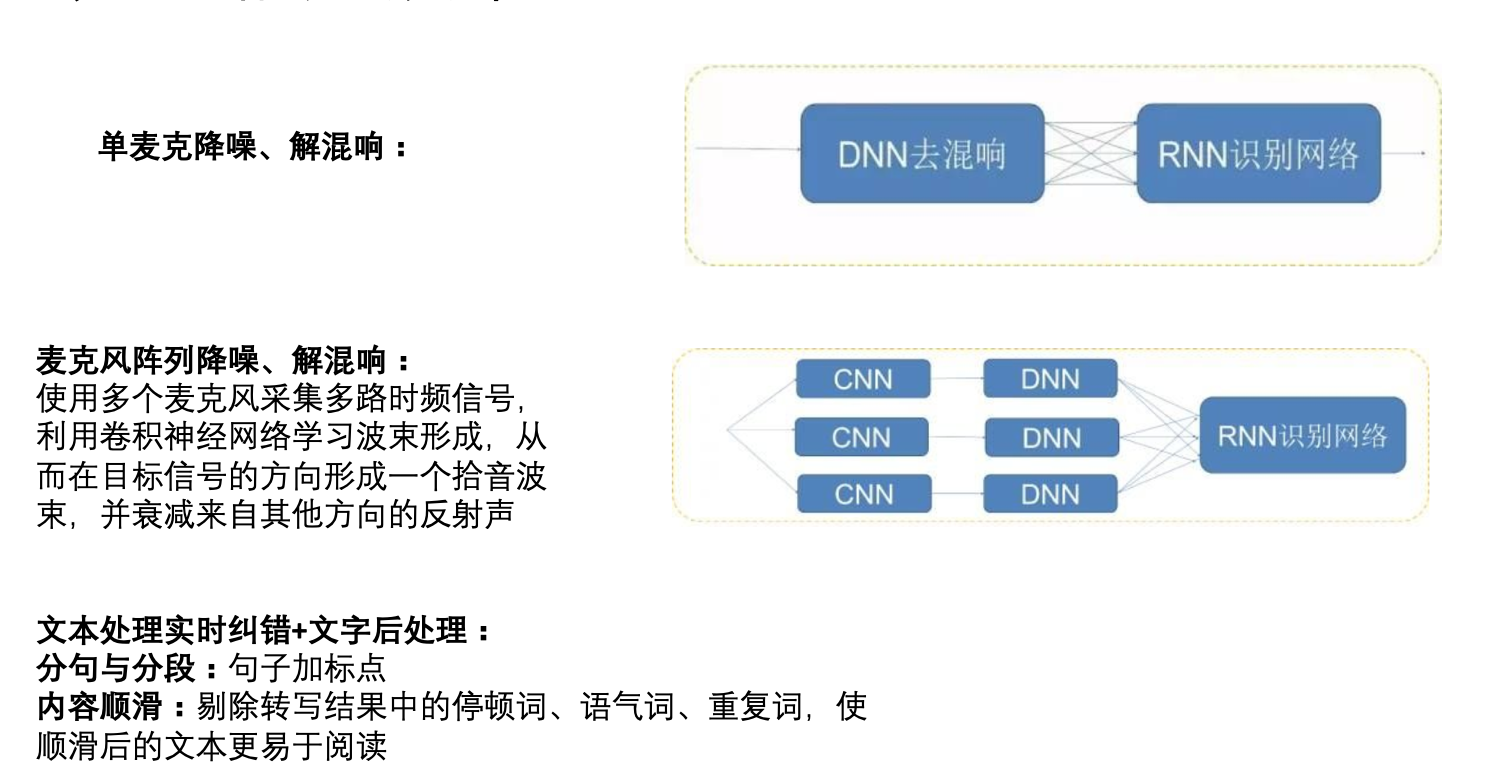
由于当今流行的模型大部分都是基于deep neural network的, 网络的形态基本在 CNN RNN 以及全连接上更换。 这些大都很通用。 所以这里没有再细讲原理,而是直接贴图展示。 具体哪种方案更好,恐怕要真实的投入并尝试才能得知了。 目前训练所需要的机器代价也是比较高的。开源的语音数据网上倒是不难搜到。如果是真感兴趣的同学,可以考虑租用云服务器的形式来自己做下测试。