标签(空格分隔): Impala
Impala是什么
Impala对存储在HDFS,HBase的Apache Hadoop数据和存储在Amazon S3上的数据提供快速,交互式的SQL查询。 除了使用相同的统一存储平台外,Impala还使用了与Apache Hive相同的元数据、SQL语法(Hive SQL)、ODBC驱动程序和UI(Hue中的Impala查询UI)。
这为实时查询或面向批处理的查询提供了熟悉且统一的平台。
Impala是可用于查询大数据的工具的补充。Impala不会取代构建在MapReduce上的批处理框架,如Hive。 基于MapReduce构建的Hive和其他框架最适合
长时间运行的批处理作业,例如涉及批处理ETL类型的作业。。
使用Impala的好处
Impala提供:
- 数据科学家和分析师熟悉的SQL界面。
- 能够在Apache Hadoop中查询大量数据(“大数据”)。
- 在集群环境中进行分布式查询,以便于扩展和使用具有成本效益的普通硬件。
- 能够在不同组件之间共享数据文件,无需复制或导出/导入步骤; 例如,可以使用Pig写数据,使用Hive进行转换并使用Impala进行查询。 Impala可以读取和写入Hive表,也支持使用Impala进行简单的数据内部交换,以便对Hive生成的数据进行分析。
- 用于大数据处理和分析的单一系统,因此客户可以避免昂贵的建模和ETL
分析。
Impala如何工作在Hadoop上
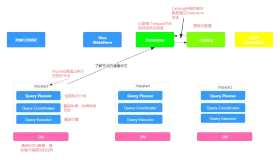
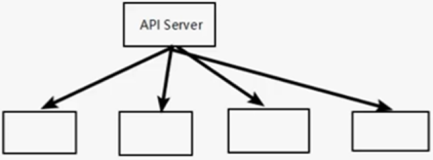
Impala解决方案由以下组件组成:
- 客户端Clients - 实体包括Hue,ODBC客户端,JDBC客户端和Impala Shell都可以与Impala进行交互。
这些界面通常用于发出查询或完成管理任务,例如连接到Impala。 - Hive Metastore - 存储有关Impala可用数据的信息。例如,Metastore让Impala知道可用的数据库以及这些数据库的结构。比如你可以通过Impala SQL语句创建、删除和更改schema,将数据加载到表中等等,相关的元数据更改都是通过Impala 1.2中引入的专用目录服务自动向所有Impala节点广播。
- Impala - 此进程在DataNode上运行,协调和执行查询。Impala的每个实例都可以从Impala客户端接收、计划和协调查询。查询分布在Impala节点上,
这些节点然后充当worker执行并行查询片段。 - HBase和HDFS - 要查询的数据的存储。
使用Impala执行的查询处理如下:
- 用户应用程序通过ODBC或JDBC向Impala发送SQL查询,这些驱动提供标准化查询接口。用户应用程序可以连接到群集中的任何impalad。这个impalad成了查询的协调员。
- Impala解析查询并对其进行分析,以确定impalad实例需要执行哪些任务在整个集群。计划执行以实现最佳效率。
- 本地impalad实例访问HDFS和HBase等服务以提供数据。
- 每个impalad将数据返回给协调impalad,后者将这些结果发送给客户端client。
基本的Impala特性
Impala为以下方面提供支持:
- Hive查询语言(HiveQL)的最常见SQL-92功能,包括SELECT,join和aggregate函数。
-
HDFS,HBase和Amazon Simple Storage System(S3)存储,包括:
- HDFS文件格式:CSV,Parquet,Avro,SequenceFile和RCFile。
- 压缩编解码器:Snappy,GZIP,Deflate,BZIP。
-
通用数据访问接口,包括:
- JDBC驱动程序。
- ODBC驱动程序。
- Hue Beeswax和Impala Query UI。
- impala-shell命令行界面。
- Kerberos身份验证。