更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
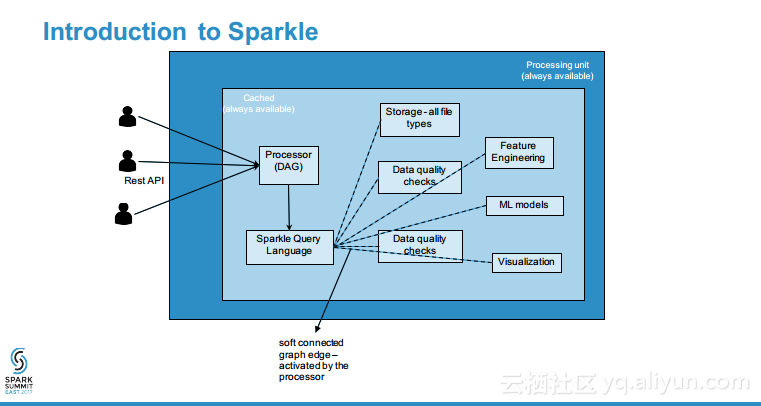
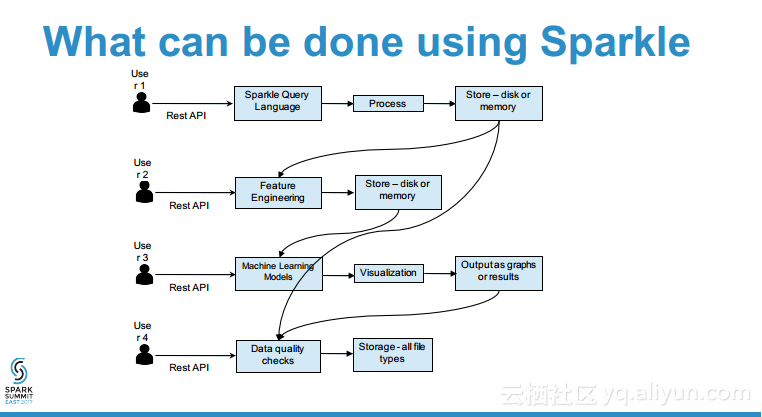
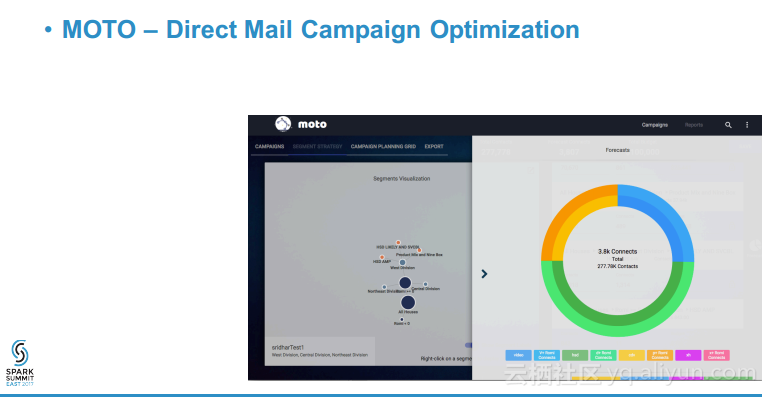
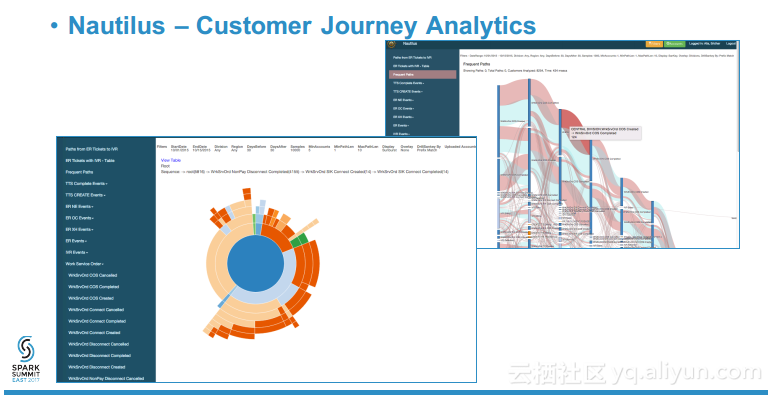
本讲义出自Sridhar Alla与Shekhar Agrawal 在Spark Summit East 2017上的演讲,演讲中展示了许多使用逻辑回归、随机森林、决策树、聚类以及NLP等等常用算法的常见用例,并介绍了comcast构建的平台,该平台提供了基于Spark上构建的带有REST API的DSaaS,这意味这对很多用户而言比较抽象的控制和提交等工作,用户可以不再需要考虑写作的严谨性而只需要关注实际需求。