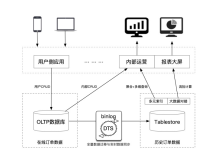
背景
订单系统在各行各业中广泛应用,为消费者、商家后台、促销系统等第三方提供用户、产品、订单等多维度的管理和查询服务。
为了挖掘出海量订单数据的潜能,丰富高效的查询必不可少。然而很多时候并不能给出完整准确的查询关键字,例如,只知道收货人姓氏,或是产品名称部分关键字,或是根据收货人手机尾号找到订单,我们将这类查询归为“模糊查询”。
需求分析
订单系统,作为电商系统的“核心”,管理着订单状态、商品信息、用户信息、收货地址和支付信息,联动库存更新,为下游的仓库物流系统提供依据。在订单表设计时,需要记录上述所有信息。本文仅以海量订单管理查询为背景,摘选部分重要字段,管窥多元索引(SearchIndex)在模糊查询时的一些典型使用,整理如下:
- 手机号前缀匹配
覆盖SQL like语义,满足前缀匹配、后缀匹配和通配符匹配查询。 - 产品名称模糊查询
用户输入产品名称中部分关键字即可查出包含相关产品的订单。 - 商品型号的实时查询提示
只输入少量查询关键字就可召回尽可能多的匹配结果,可用于“电影名称”、“产品型号”等字段的实时查询提示。
传统解法
MySql和PostgreSQL等关系型DB支持like语法进行模糊查询,其本质就是用查询关键词去扫描并匹配每条记录的字符串内容,只适用于小规模地检索,数据规模大了以后性能非常差。
TableStore解法
表格存储(TableStore)引入多元索引(SearchIndex)功能后,完全覆盖传统SQL所支持的前缀匹配和通配符匹配,并且提供针对不同场景的精细化模糊查询功能,性能优异。本节将以电商订单为背景逐一讲解。
手机号前缀匹配
定义手机号字段consumerCell为KEYWORD类型,创建多元索引,用PrefixQuery即可对原始字段进行前缀匹配查询。例如,查询consumerCell字段以'135'开头的行,等价于SQL中子句consumerCell like '135%'。
核心代码
//创建索引
indexSchema.addFieldSchema(new FieldSchema(CONSUMER_CELL, FieldType.KEYWORD));
//查询
PrefixQuery prefixQuery = new PrefixQuery();
prefixQuery.setFieldName(CONSUMER_CELL);
prefixQuery.setPrefix("13580");通配符查询
如同前缀查询(PrefixQuery),通配符查询(WildcardQuery)可以对原始字符串进行更灵活一些的匹配。例如,查询consumerCell字段中以'135'开头并且中间包含'8066'的行,类比SQL中子句consumerCell like '135%8066%'。在表格存储中可以把consumerCell定义为KEYWORD类型,建立多元索引,然后用WildcardQuery进行通配符匹配。要匹配的值可以是一个带有通配符的字符串,用星号("*")代表0个或多个任意字符,用问号("?")代表任意单个字符。
需要注意的是,不能以“*”开头,且模式字符长度不能超过10字节。
如何实现后缀匹配
通配符查询不能以“*”开头,若要实现后缀匹配,可将字符串翻转,再用PrefixQuery/WildcardQuery查询。
产品名称模糊查询
在订单场景中,“收货人姓名”、“产品名”和“收货地址”这类字段可能包含汉字、英文、数字等,查询时需要以“单个汉字”或“英文单词”为粒度切分字符串并建立索引。查询同理,以“单个汉字”或“英文单词”为粒度对查询关键词字符串进行分词,在索引中进行查找匹配。
例如,订单表中,某行的产品名称字段值为"Xiaomi/小米redmi note 7 pro 红米索尼4800万智能手机",期望用"xiaomi", "小米", "note", "pro"都能匹配到该条记录。可以使用默认分词器SingleWord分词器。
TEXT类型索引列默认使用SingleWord分词器,按“单个汉字”切分中文,按“单个单词”切分英文,大小写字母不敏感,且单词不会被拆分为子词。例如,字段值"Xiaomi/小米redmi note 7 pro 红米索尼4800万智能手机"会被切分为词条:"xiaomi", "小", "米", "redmi", "note", "7", "pro", "红", "米", "索", "尼", "4800", "万", "智", "能", "手", "机",并建立倒排索引。
SingleWord支持配置参数CaseSensitive设置是否大小写敏感;参数DelimitWord表示是否将单词拆成子词。例如,当设置SingleWord的参数DelimitWord=true, CaseSensitive=true,TEXT字段值"TableStore"会被切分为"Table"和"Store"。
查询时若不在乎查询关键词分词后的顺序,用MatchQuery即可满足需求。对于特定场景,对查询关键词被被分词后顺序敏感,可以考虑使用MatchPhraseQuery。
核心代码
//创建索引
//等价于:indexSchema.addFieldSchema(new FieldSchema(PRODUCT_NAME, FieldType.TEXT));
indexSchema.addFieldSchema(new FieldSchema(PRODUCT_NAME, FieldType.TEXT).setAnalyzer(FieldSchema.Analyzer.SingleWord));
//查询
MatchQuery matchQuery = new MatchQuery();
matchQuery.setFieldName(PRODUCT_NAME);
matchQuery.setText("Xiaomi/小米redmi note 7 pro 红米索尼4800万智能手机");商品型号的实时查询提示
某些场景下,当使用者在搜索框中键入部分关键字,就召回尽可能多的结果。这样,可以避免用户输入错误的关键字,将其引导到“意中有语中无”的正确结果,提升用户体验。例如,订单表中包含某手机型号为"HUAWEI P30PRO",一种良好的查询体验是:仅当键入"P30","30"或者"PRO"时,就可以查出这行记录并反馈用户。此时,您可以考虑使用Fuzzy分词器。
Fuzzy分词器可以对字符串进行最细粒度的拆分,可以提升查询召回率,但也造成多元索引存储量膨胀,因此需要谨慎使用。其原理是设置一个“最小字符串长度窗口(minChars)”和“最大字符串长度窗口(maxChars)”,遍历[minChars, maxChars]窗口大小对TEXT类型字段值进行切分,并对所有切分后的字符串建立倒排。minChars默认为1,maxChars默认为3。
对“产品型号”建立TEXT索引,并使用Fuzzy分词器以后,字段值"HUAWEI P30PRO"会被切分为词条:"h", "hu", "hua", "u", "ua", "uaw", "a", "aw", "awe", "w", "we", "wei", "e", "ei", "i", "p", "p3", "p30", "3", "30", "30p", "0", "0p", "0pr", "pr", "pro", "r", "ro", "o",并建立倒排索引。因此,用"p30", "P30", "30", "PRO", "pro"查询时都可以匹配到。同时也可以看出,Fuzzy分词后索引数据量急剧膨胀,因此限制maxChars和minChars的差值不超过6,如果您需要自定义minChars和maxChars时需谨慎。
核心代码
//创建索引
indexSchema.addFieldSchema(new FieldSchema(PRODUCT_TYPE, FieldType.TEXT)
.setAnalyzer(FieldSchema.Analyzer.Fuzzy)
.setAnalyzerParameter(new FuzzyAnalyzerParameter(1, 4)));
//查询
MatchQuery matchQuery = new MatchQuery();
matchQuery.setFieldName(PRODUCT_TYPE);
matchQuery.setText("P30");代码示例
订单表结构
以订单系统的订单表(表名order)为例,可能包含以下字段:
| 列名 | 数据类型 | 索引类型 | 字段说明 |
|---|---|---|---|
| order_id_md5 | string | - | 主键列:md5(order_id)避免热点 |
| order_id | string | KEYWORD | 主键列:订单id |
| order_status | long | LONG | 订单状态 |
| order_time | long | LONG | 下单时间 |
| pay_time | long | LONG | 支付时间 |
| deliver_time | long | LONG | 发货时间 |
| receive_time | long | LONG | 收货时间 |
| product_id | string | KEYWORD | 商品id |
| product_name | string | TEXT | 产品名 |
| product_type | string | TEXT | 产品型号 |
| consumer_id | string | KEYWORD | 收货人id |
| consumer_name | string | TEXT | 收货人姓名 |
| consumer_cell | string | KEYWORD | 收货人联系方式 |
| consumer_address | string | TEXT | 收货地址 |
项目代码
完整代码在这里找到:https://github.com/aliyun/tablestore-examples/tree/master/feature/FuzzySearch
附录
除了上文提到的SingleWord和Fuzzy分词器以外,多元索引还支持以下分词器——
MaxWord分词器
MaxWord分词器将英文切分成单词,将中文切分成尽可能多的词语/词组。对中文分词时,会做多层语义分词,一般为两层,第一层按最短语义切分,第二层按最长语义切分,并将两次切分后的数组合并。例如字符串"菊花茶",第一层切分为["菊花"、"花茶"],第二层切分为["菊花茶"],合并后为["菊花"、"花茶"、"菊花茶"]。
MinWord分词器
MinWord分词器将英文切分成单词,将中文切分为尽可能少的词语/词组。对中文分词时,只会按最长语义切分,例如字符串"菊花茶",会被切分为["菊花茶"]。
Split分词器
Split分词器允许您按照自定义分隔符对字符串进行分词。例如,用字符串内容用逗号(","),将Split分词器的分隔符设置为",",可以按照","切分并构建索引。
总结
表格存储多元索引(SearchIndex)为海量订单数据提供了丰富的查询类型,而模糊查询使得用户在不给出完整准确的查询关键字就能实现近似匹配,大大提升了订单数据的查询易用性,发挥出存储的更多潜在价值。
本文以海量电商订单管理为背景,通过几个具体案例,带您了解了多元索引强大的模糊查询功能。如有更多疑问,欢迎加入我们的技术支持群: