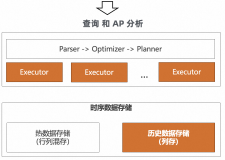
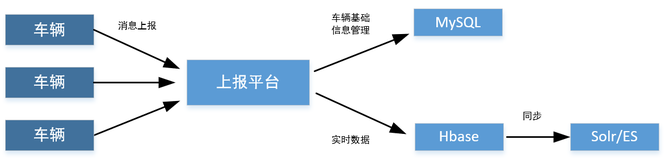
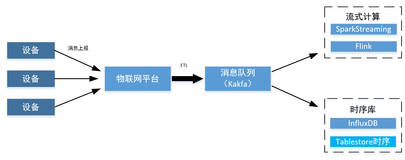
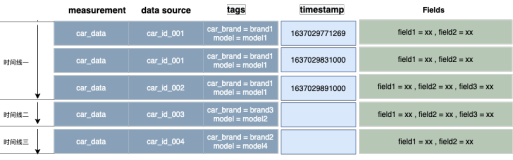
背景
互联网快速发展的今天,社交类应用、消息类功能大行其道,占据了大量网络流量。大至钉钉、微信、微博、知乎,小至各类App的推送通知,消息类功能几乎成为所有应用的标配。根据场景特点,我们可以将消息类场景归纳成三大类:IM(钉钉、微信)、Feed流(微博、知乎)以及常规消息队列。因此,如何开发一个简便而又高效IM或Feed流功能,成为了很多架构师、开发人员不得不面对的问题。
Timeline 1.0版模型
针对消息类场景,表格存储团队针对JAVA语言打造了一个TableStore-Timeline 1.0版数据模型模型(简称Timeline模型)。基于场景经验与理解,将消息场景封装成一个数据模型,提供了表结构设计,读写方式等解决方案供需求者使用。用户只需依托模型API,直接忽略Timeline到底层存储系统之间的架构方案,直接基于接口实现业务逻辑。它能满足消息数据场景对消息保序、海量消息存储、实时同步等特殊需求。Timeline 1.0是定义在表格存储之上抽象出来的数据模型,具体内容参见《TableStore Timeline:轻松构建千万级IM和Feed流系统》。
全文检索、模糊查询需求
在表格存储的Timeline模型受到广泛使用的过程中,我们也逐渐发现消息类数据的全文检索、模糊查询这一很强需求。而原有模型的在线查询能力存在一定短板。随着表格存储支持了SearchIndex能力,使得Timeline模型支持在线全文检索、模糊查询成为了可能。所以我们基于原有的架构设计,重新打造了Timeline 2.0模型,引入了强大的查询能力与数据管理新方案。
项目代码目前已经开源在了GitHub上:Timeline@GitHub。
2.0时代到来
此次推出的Timeline模型2.0版,没有直接基于1.X版本直接改造。而是在兼容原有模型架构之上,定义、封装了新的使用接口。重新打造升级新的模型,增加了如下功能:
- 增加了Timeline Meta的管理能力;
- 基于多元索引功能,增加了Meta、Timeline的全文检索、多维组合查询能力;
- 支持SequenceId两种设置方式:自增列、手动设置;
- 支持多列的Timeline Identifier设置,提供Timeline的分组管理能力;
- 兼容Timeline 1.X模型,提供的TimelineMessageForV1样例可直接读、写1.X版本消息,用户也可仿照实现。
架构解析

Timeline做为表格存储直接支持的一种数据模型,以『简单』为设计目标,其存核心模块构成比较清晰明了。Timeline尽量提升用户的使用自由度,让用户能够根据自身场景需求选择更为合适的实现方案。模型的模块架构如上图,主要包括如下重要部分:
- Store:存储库,类似数据库的表的概念,模型包含两类Store分别为Meta Store、Timeline Store。
- Identifier:用于区分Timeline的唯一标识,用以标识单行Meta,以及相应的Timeline Queue。
- Meta:用于描述Timeline的元数据,元数据描述采用free-schema结构,可自由包含任意列。
- Queue:Queue为单Identifier对应的所有消息队列,一个Timeline下Message按照Queue单元存储。
- SequenceId:Queue中消息体的序列号,需保证递增、唯一,模型支持自增列、自定义两种实现模式。
- Message:Timeline内传递的消息体,是一个free-schema的结构,可自由包含任意列。
- Index:基于SearchIndex实现的索引,针对不同Store分为Meta Index和Message Index两类,可对Meta或Message内的任意列自定义索引,提供灵活的多条件组合查询和搜索。
性能优势
Timeline 模型是基于Tablestore抽象、封装出的一类场景数据模型,因而具有Tablestore自身的所有优点。同时结合场景设计的接口,让用户更直观、清晰的实现业务逻辑,总结如下:
- 支撑海量数据存储:分布式架构,高可扩展,支持10PB级的消息。
- 低存储成本:表格存储提供低成本的存储方式,按量付费、资源包、预留Cu。
- 数据生命周期管理:不同类型(表级别)消息数据,可自定义不同生命周期。
- 极高的写入吞吐:具备极高的写入吞吐能力,可应对00M TPS的消息写入。
- 低延迟的读:查询消息延迟低,毫秒量级。
- 接口设计:可读性高,接口功能全面、清晰。
Maven地址
Timeline Lib
<dependency>
<groupId>com.aliyun.openservices.tablestore</groupId>
<artifactId>Timeline</artifactId>
<version>2.0.0</version>
</dependency>TableStore Java SDK
Timeline模型在TableStore Java SDK >= 4.12.1作为基本数据模型直接提供,表格存储老用户可升级SDK直接使用
<dependency>
<groupId>com.aliyun.openservices</groupId>
<artifactId>tablestore</artifactId>
<version>4.12.1</version>
</dependency>入手指南
初始化
初始化Factory
用户将SyncClient作为参数,初始化StoreFactory,通过工厂创建Meta数据、Timeline数据的管理Store。错误重试的实现依赖SyncClient的重试策略,用户通过设置SyncClient实现重试。如有特殊需求,可自定义策略(只需实现RetryStrategy接口)。
/**
* 重试策略设置
* Code: configuration.setRetryStrategy(new DefaultRetryStrategy());
* */
ClientConfiguration configuration = new ClientConfiguration();
SyncClient client = new SyncClient(
"http://instanceName.cn-shanghai.ots.aliyuncs.com",
"accessKeyId",
"accessKeySecret",
"instanceName", configuration);
TimelineStoreFactory factory = new TimelineStoreFactoryImpl(client);初始化MetaStore
构建meta表的Schema(包含Identifier、MetaIndex等参数),通过Store工厂创建并获取Meta的管理Store;配置参数包含:Meta表名、索引,表名、主键字段、索引名、索引类型等参数。
TimelineIdentifierSchema idSchema = new TimelineIdentifierSchema.Builder()
.addStringField("timeline_id").build();
IndexSchema metaIndex = new IndexSchema();
metaIndex.addFieldSchema( //配置索引字段、类型
new FieldSchema("group_name", FieldType.TEXT).setIndex(true).setAnalyzer(FieldSchema.Analyzer.MaxWord)
new FieldSchema("create_time", FieldType.Long).setIndex(true)
);
TimelineMetaSchema metaSchema = new TimelineMetaSchema("groupMeta", idSchema)
.withIndex("metaIndex", metaIndex); //设置索引
TimelineMetaStore timelineMetaStore = serviceFactory.createMetaStore(metaSchema);初始化TimelineStore
构建timeline表的Schema配置,包含Identifier、TimelineIndex等参数,通过Store工厂创建并获取Timeline的管理Store;配置参数包含:Timeline表名、索引,表名、主键字段、索引名、索引类型等参数。
消息的批量写入,基于Tablestore的DefaultTableStoreWriter提升并发,用户可以根据自己需求设置线程池数目。
TimelineIdentifierSchema idSchema = new TimelineIdentifierSchema.Builder()
.addStringField("timeline_id").build();
IndexSchema timelineIndex = new IndexSchema();
timelineIndex.setFieldSchemas(Arrays.asList(//配置索引的字段、类型
new FieldSchema("text", FieldType.TEXT).setIndex(true).setAnalyzer(FieldSchema.Analyzer.MaxWord),
new FieldSchema("receivers", FieldType.KEYWORD).setIndex(true).setIsArray(true)
));
TimelineSchema timelineSchema = new TimelineSchema("timeline", idSchema)
.autoGenerateSeqId() //SequenceId 设置为自增列方式
.setCallbackExecuteThreads(5) //设置Writer初始线程数为5
.withIndex("metaIndex", timelineIndex); //设置索引
TimelineStore timelineStore = serviceFactory.createTimelineStore(timelineSchema);Meta管理
Meta管理提供了增、删、改、单行读、多条件组合查询等接口。其中多条件组合查询功能基于多元索引,只有设置了IndexSchema的MetaStore才支持组合查询功能。索引类型支持LONG、DOUBLE、BOOLEAN、KEYWORD、GEO_POINT等类型,属性包含Index、Store和Array,其含义与多元索引相同。
TimelineIdentifer是区分Timeline的唯一标识,重复的Identifier会被覆盖。
/**
* 接口使用参数
* */
TimelineIdentifier identifier = new TimelineIdentifier.Builder()
.addField("timeline_id", "group")
.build();
TimelineMeta meta = new TimelineMeta(identifier)
.setField("filedName", "fieldValue");
/**
* 创建Meta表(如果设置索引则会创建索引)
* */
timelineMetaStore.prepareTables();
/**
* 插入Meta数据
* */
timelineMetaStore.insert(meta);
/**
* 根据id读取单行Meta数据
* */
timelineMetaStore.read(identifier);
/**
* 更新Meta数据
* */
meta.setField("fieldName", "newValue");
timelineMetaStore.update(meta);
/**
* 根据id删除单行Meta数据
* */
timelineMetaStore.delete(identifier);
/**
* 通过SearchParameter参数检索
* */
SearchParameter parameter = new SearchParameter(
field("fieldName").equals("fieldValue")
);
timelineMetaStore.search(parameter);
/**
* 通过SearchQuery参数检索(SearchQuery是SDK原生类型,支持所有多元索引检索条件)
* */
TermQuery query = new TermQuery();
query.setFieldName("fieldName");
query.setTerm(ColumnValue.fromString("fieldValue"));
SearchQuery searchQuery = new SearchQuery().setQuery(query);
timelineMetaStore.search(searchQuery);
/**
* 删除Meta表(如果存在索引,同时删除索引)
* */
timelineMetaStore.dropAllTables();Timeline管理
Timeline管理提供了消息模糊查询、多条件组合查询接口。消息的全文检索依托多元索引,用户只需将相应字段索引类型设置为TEXT,即可通过Search接口实现消息的全文检索。Timeline管理包含消息表的创建、检索、删除等。
/**
* 接口使用参数
* */
SearchParameter searchParameter = new SearchParameter(
field("text").equals("fieldValue")
);
TermQuery query = new TermQuery();
query.setFieldName("text");
query.setTerm(ColumnValue.fromString("fieldValue"));
SearchQuery searchQuery = new SearchQuery().setQuery(query).setLimit(10);
/**
* 创建Meta表(如果设置索引则会创建索引)
* */
timelineStore.prepareTables();
/**
* 通过SearchParameter参数检索
* */
timelineStore.search(searchParameter);
/**
* 通过SearchQuery参数检索(SearchQuery是SDK原生类型,支持所有多元索引检索条件)
* */
timelineStore.search(searchQuery);
/**
* 将Writer队列中未发的请求主动触发,同步等待直到所有消息完成存储
* */
timelineStore.flush();
/**
* 关闭Writer与Writer中的线程池
* */
timelineStore.close();
/**
* 删除Timeline表(如果存在索引,同时删除索引)
* */
timelineStore.dropAllTables();Queue管理
Queue是单个消息队列的抽象概念,对应一个Store下单个Identifier的所有消息。通过Queue实例管理相应Identifer的消息队列,支持基本的增、删、改、单行查、范围查等接口。
/**
* 接口使用参数
* */
TimelineIdentifier identifier = new TimelineIdentifier.Builder()
.addField("timeline_id", "group")
.build();
long sequenceId = 1557133858994L;
TimelineMessage message = new TimelineMessage().setField("text", "Timeline is fine.");
ScanParameter scanParameter = new ScanParameter().scanBackward(Long.MAX_VALUE, 0);
TimelineCallback callback = new TimelineCallback() {
@Override
public void onCompleted(TimelineIdentifier i, TimelineMessage m, TimelineEntry t) {
// do something when succeed.
}
@Override
public void onFailed(TimelineIdentifier i, TimelineMessage m, Exception e) {
// do something when failed.
}
};
/**
* 单个Identifier对应的消息队列
* */
timelineQueue = timelineStore.createTimelineQueue(identifier);
/**
* 存储消息
* */
//同步
timelineQueue.store(message);
timelineQueue.store(sequenceId, message);
//异步,支持callback
timelineQueue.storeAsync(message, callback);
timelineQueue.storeAsync(sequenceId, message, callback);
//异步批量
timelineQueue.batchStore(message);
timelineQueue.batchStore(sequenceId, message);
//异步批量,支持callback
timelineQueue.batchStore(message, callback);
timelineQueue.batchStore(sequenceId, message, callback);
/**
* 单行读取、获取最新一行、获取最新SequenceId
* */
timelineQueue.get(sequenceId);
timelineQueue.getLatestTimelineEntry();
timelineQueue.getLatestSequenceId();
/**
* 根据SequenceId更新消息
* */
message.setField("text", "newValue");
timelineQueue.update(sequenceId, message);
timelineQueue.updateAsync(sequenceId, message, callback);
/**
* 根据SequenceId删除消息
* */
timelineQueue.delete(sequenceId);
/**
* 根据范围参数、Filter获取批量消息
* */
timelineQueue.scan(scanParameter);专家服务
表格存储有一批精通Timeline领域的技术专家,在打造IM、Feed流场景方面有着独到的见解。如果您:
- 渴望寻觅Timeline领域高手过招;
- 调研Timeline场景解决方案;
- 准备入门Timeline场景;
- 对表格存储(Tablestore)产品感兴趣;
欢迎加入“表格存储公开交流群”。表格存储 (Tablestore) 提供专业的免费的技术咨询服务,期待为您服务。群号 : 23307953