第一章
一、简介
Solr是一个开源的,企业级搜索服务器。她已经是一个成熟的产品,用于强化网络站点的搜索功能,包括内部局域网。
她是用Java语言编写。使用HTTP和XML进行数据传输,Java的掌握对于学习Solr不是必须的。除了能返回搜索
结果外,还有包括高亮搜索关键字,方位导航(已广泛用于电子商务网站),查询关键字拼写校验,自动查询建议
和 “类似”查询 帮助更好定位搜索。
二、Lucene,solr的基础引擎
在相信介绍Solr前,我们先从Apache Lucene开始,Solr的核心基础引擎。Lucene是一个开源的,高效的
文本搜索引擎。Lucene是由Doug Cutting在2000年开发的,并且伴随着强大的在线社区不断进化和成熟。
Lucene不是一个服务器,也不是一个网络爬虫。这一点非常重要,她没有任何配置文件。我们需要编写代码来
存贮和查询在磁盘上的索引。
下面是Lucene的一些主要特征:
- 通过建立基于文本的反向索引来快速查询文件。
- 通过丰富的文本分析器(analyzers),将字符串形式的文本信息转换为一系列terms,来联系索引和搜索。
- 一个查询分析器,还有很多能 支持从简单查询到模糊查询 的查询类型(query types)
- 一个听上去叫Information Retrieval(IR)的得分算法,以产生更多可能的候选结果,有很多灵活的方式来设置得分策略。
- 在上下文中高亮显示被找到的查询关键字
- 根据索引内容 来 检查 查询关键字拼写(更多关于查询关键字拼写 可以参考Lucene In Action)
三、Solr,是Lucene的服务器化产物
在对Lucene的了解后,Solr可以理解为Lucene的服务器化产品。但她不是对Lucene的一次简单封装,Solr的大多数特征都与Lucene不同。Solr 和 Lucene 的界限经常是模糊的。以下是Solr的主要特性:
- 通过HTTP请求来 建立索引和搜索索引
- 拥有数个缓存 来 加快搜索速度
- 一个基于web的管理员控制台
运行时做性能统计,包括缓存 命中/错过 率
查询表单 来 搜索索引。
以柱状图形式 展示 频繁被查询的关键字
详细的“得分计算和文本解析”分析。
- 用XML文件的方式 配置搜索计划和服务器
通过配置XML 来添加和配置 Lucene的文本分析库
引入“搜索字段类型”的概念(这个非常重要,然而在Lucne中没有)。类型用作表示日期和一些特殊的排序问题。
- 对最终用户和应用成素,disjunction-max 查询处理器比Lucene基础查询器更实用。
- 查询结果的分类
- 拼写检查用于寻找搜索关键字 的类似词,优化查询建议
- “更类似于”插件用以列出 于查询结果类似的 备选结果。
- Solr支持分布式来应对较大规模的部署。
以上特征都会在下面的章节内详述。
四、Solr 于数据库技术的比较
对于开发人员而言,数据库技术(特别是关系数据库)已经成为一个必须学习的知识。数据库和Lucene的搜索索引并没有显著的不同。假设我们已经非常熟悉数据库知识,现在来描述下她和Lucene有什么不同。(这里来帮助更好了解Solr)
最大的不同是,Lucene可以理解为一个 只有一张简单表格 的数据库,没有任何的关系查询(即JOINS)。这听上去很疯狂,不过记住索引只是为了去支持搜索,而不是去标识一条数据。所以数据库可以去遵守“第三范式”,而索引就不会如此,表格中尽可能多的包含会被搜索到的数据而已。用来补充单表的是,一个域(列)中可以有多值。
其他一些显著的不同:
- 更新(Update):整个文档可以被删除,然后再添加,但不能被更新。
- 子字符串搜索与文本搜索:例如“Books”,数据库的Like匹配出“CookBooks”、“MyBooks”。Lucene基于查询分析器的配置,可以查到更多形式的词匹配“Books”,比如book(这里是大小写被忽略),甚至发音相似的词。运用ngram技术,她可以提取部分搜索条件的词干进行匹配。
- 结果打分:Lucene的强大在于她可以根据结果的匹配程度来打分。例如查询条件中有部分是可选的(OR search),那匹配程度高的文档会得到更多的分。有一些其他因素,可以调整打分的方式。然而,数据库就没有这个功能,只是匹配或不匹配。Lucene也可以在需要的时候对结果进行排序。
- 延迟提交:Solr的搜索速度通过建立缓存得以优化。当一个完成的文档需要被提交,所有的缓存会重新构建,根据其他一些因素,这可能花费几秒到一分钟。
五、正式开始Solr
Solr是用Java编写的,不过我们不需要对Java非常了解。如果需要扩展Solr的功能,那我们需要了解Java。
我们需要掌握的是命令行操作,包括Dos和Unix。
在正式开始前,我们可能需要安装以下一些包:
- A Java Development Kit(JDK) v1.5 or later.
- Apache Ant: Any recent version
- Subversion or Git for source control of Solr: svn 或 git
- Any Java EE servlet Engine app-server:Sole 已经自带了Jetty。
- Solr:http://lucene.apache.org/solr ,现在官方是1.4版本。也可以去取源代码获得最新版本。(经过单元和集成测试,也是非常稳定和可靠的),通过 svn co http://svn.apache.org/repos/asf/lucene/solr/trunk/ solr_svn 将最新的源代码下载到本地solr_svn目录下。
Solr 发布包下的目录结构:
- client::包含特定的编程语言与Solr通信。这里其实只有Ruby的例子。Java的客户端在src/solrj
- dist:这里包含Solr的Jar包和War包
- example:这里有Jetty安装所需要的包(Solr自带Jetty),包括一些样本数据和Solr的配置文件。
example/etc:Jetty的配置文件。可以修改监听端口(默认8983)
example/multicore:多核环境下,solr的根目录(后面会具体讨论)
example/solr:默认环境下的solr根目录
example/webapps:Solr的WAR包部署在这里
- lib:所有Solr依赖的包。一大部分是Lucene,一些Apache常用的工具包,和Stax(XML处理相关)
- src:各种源码。可以归为以下几个重要目录:
src/java:Solr的源代码,用Java编写。
src/scripts:Unix的bash shell脚本,应用与在大型应用中部署多个Solr服务。
src/solrj:Solr Java的客户端。
src/webapp:Solr web端的管理员用户界面,包括Servlets和JSP。这些其实也都是War中的内容。
注意:要看Java源码的话,src/java下是主要的Solr源码;src/common下是一部分通用类,供server端和solrj客户端;src/test中是测试代码;src/webapp/src下是servlet代码;
六、Solr的根目录
Solr的根目录下包括Solr的配置和运行Solr实例需要的数据。
Sole有一个样例根目录,在example/solr下,我们将会使用这个
另一个更技术层面的,在example/solr下,也是Solr的一个根目录不过是用在多核的环境下,稍后讨论。
让我们来看下根目录下有些什么:
- bin:如果想自己设置Solr,这里可以放脚本。
- conf:配置文件。下面的2个文件很重要,这个文件夹下还包括一些其他文件,都是被这2个文件引用,为了一些其他配置,比如文本分析的细节。
conf/schema.xml:这里是索引的概要,包括 域类型(field type)定义和相关分析器链。
conf/sorconfig.xml:这是Solr配置的主文件。
conf/xslt:这个目录薄厚一些XSLT文件,用来把Solr搜索结果(XML)转换为其他形式,例如Atom/RSS。
- data:包含Lucene的索引数据,Solr自动生成。这些都是二进制数据(binary),我们基本不会去动它,除非需要删除。
- lib:一些额外的,可选的Java Jar包,Solr会在启动时调用。当你不是通过修改Solr源码 强化Solr的一些功能,可以将包放在这里。
七、Solr如何找到自己的根目录
Solr启动后的第一件事是从根目录加载配置信息。这可以通过好几种方式来指定。
- Solr先从Java的系统环境变量中搜寻 solr.solr.home这个变量。通常通过命令行设置,如启动Jetty时:java -Dsolr.solr.home = solr/ -jar start .jar ;也可以用JNDI 绑定路径到java:comp/env/solr/home,可以设置web.xml来让app-server维护这个变量(src/web-app/web/WEB-INF)
- <env-entry>
- <env-entry-name>solr/home</env-entry-name>
- <env-entry-value>solr/</env-entry-value>
- <env-entry-type>java.lang.String</env-entry-type>
- </env-entry>
这里修改了web.xml,需要使用ant dist-war重新打包部署。这里仅仅如此还不够,需要设置JNDI,这里就不深入了。
PS:JNDI需要设置2个环境变量,具体查看EJB相关笔记。
- 如果根目录没有设置在环境变量或JNDI中,默认地址是 solr/。我们后面会沿用这个地址。(具体产品还是需要配置来设定,比较安全,可以使用绝对或相对路径)
设置完根路径后,在Solr启动中的log会显示:
Aug 7, 2008 4:59:35 PM org.apache.solr.core.Config getInstanceDir
INFO: Solr home defaulted to 'null' (could not find system property or JNDI)
Aug 7, 2008 4:59:35 PM org.apache.solr.core.Config setInstanceDir
INFO: Solr home set to 'solr/'
八、部署和运行Solr
部署就是apach-solr-1.4.war。这里不包含Solr的根目录。
这里我们以自带的Jetty为例子,进入example目录
cd example
java -jar start.jar
看到下面这句日志,即启动完成:
2010-07-09 15:31:06.377::INFO: Started SocketConnector @ 0.0.0.0:8983
在控制台点击Ctrl-C 可以关闭服务器。
0.0.0.0表示她监听来自任务主机的请求,8983是端口号。
此时,可以进入连接:http://localhost:8983/solr,如果启动失败会显示原因,如果成功即可看到管理员入口(http://localhost:8983/solr/admin/)。
九、简单浏览下Solr
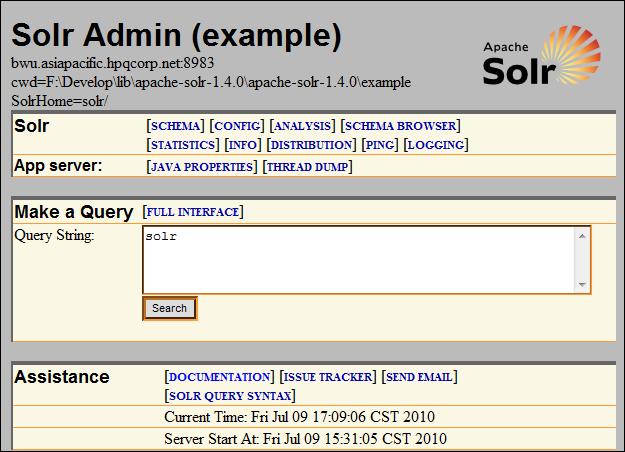
顶部灰色部分:
- 头部信息,当启动多个Solr实例时,可以帮助了解在操作哪个实例。IP地址和端口号都是可见的。
- example(Admin旁边)是对这个schema的引用,仅仅是标识这个schema。如果你有很多schema,可以用这个标识去区分。
- 当前工作目录(cwd) ,和Solr的根目录(SolrHome)。
导航栏上的功能:
- SCHEMA:显示当前的schema的配置文件。(不同浏览器显示可能不同,Firefox会高亮显示语法关键字)
- CONFIG:显示当前的Solr config文件。
- ANALYSIS:她用来诊断潜在的 文本分析 的查询/索引问题。这是高级功能,稍后做讨论。
- SCHEMA BROWSER:这是一个简洁的 反映当前索引中实际存放数据的 视图,稍后做讨论。
- STATISTICS:这里是 时间和缓存命中率统计。稍后做讨论。
- INFO:她列出了Solr当前应用组件的版本信息,不是很常用。
- DISTRIBUTION:这里包含了分布式/复制的状态信息,稍后讨论。
- PING:可以忽略,她用来在分布式模式下提供健壮性检查。
- LOGGING:可以在这里设置Solr不同部分的Logging levels。在Jetty下,输出的信息都在控制台。(Solr使用SLF4j)
- JAVA PROPERTIES:列出了JAVA系统环境变量。
- THREAD DUMP:这里显示了Java中的线程信息,帮助诊断问题。
- FULL INTERFACE:一个更多选择的查询表单,可以帮助诊断问题。这个表单也是能力有限的,只能提交一小部分搜索选项给Solr
Assistance 部分包括一些在线的帮助信息。
十、装在示例数据
Solr有一些示例数据和装载脚本,在example/exampledocs下。
进入example/exampledoce下,输入:
java -jar post.jar *.xml (如果在unix环境下,就运行post.sh)
post.jar是一个简单的程序,会遍历所有的参数(这里就是*.xml),然后对本机正运行的Solr(example)服务器的默认配置(http://localhost:8983/solr/update) 发送post请求(HTTP)。这里可以看下post.sh,就可以了解在干什么了。
可以在控制台命令行中看到发送的文件:
SimplePostTool: POSTing files to http://localhost:8983/solr/update..
SimplePostTool: POSTing file hd.xml
SimplePostTool: POSTing file ipod_other.xml
SimplePostTool: POSTing file ipod_video.xml
SimplePostTool: POSTing file mem.xml
SimplePostTool: POSTing file monitor.xml
SimplePostTool: POSTing file monitor2.xml
SimplePostTool: POSTing file mp500.xml
SimplePostTool: POSTing file payload.xml
SimplePostTool: POSTing file sd500.xml
SimplePostTool: POSTing file solr.xml
SimplePostTool: POSTing file utf8-example.xml
SimplePostTool: POSTing file vidcard.xml
SimplePostTool: COMMITting Solr index changes..
最后一行会执行commit操作,保证之前的文档都被保存,并可见。
理论上post.sh 和 post.jar是可以用在产品脚本上的,但这里仅仅用作示例。
这里取其中一个文件monitor.xml 看下:
- <add>
- <doc>
- <field name="id">3007WFP</field>
- <field name="name">Dell Widescreen UltraSharp 3007WFP</field>
- <field name="manu">Dell, Inc.</field>
- <field name="cat">electronics</field>
- <field name="cat">monitor</field>
- <field name="features">30" TFT active matrix LCD, 2560 x 1600,
- .25mm dot pitch, 700:1 contrast</field>
- <field name="includes">USB cable</field>
- <field name="weight">401.6</field>
- <field name="price">2199</field>
- <field name="popularity">6</field>
- <field name="inStock">true</field>
- </doc>
- </add>
这个发送给Solr的文件非常简单。这里只用了一些简单的标签,不过都是非常重要的。
<add>标签中可以放置多个<doc>标签(一个doc代表一个document),在大量数据装载时这样做能提高性能。
Solr在每个POST请求中都会收到一个<commit/>标签。更多的一些特性会在之后介绍。
十一、一次简单的搜索。
在管理员界面,让我们运行一次简单的搜索。
在管理员界面,点击查询按钮,或进入FULL INTERFACE再作更详细的查询。
在我们查看XML输出文件之前,先看下URL和参数信息:
http://localhost:8983/solr/select/?q=monitor&version=2.2&start=0&rows=10&indent=on.
然后浏览器中会显示输出的用XML标识的搜索结果,如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <response>
- <lst name="responseHeader">
- <int name="status">0</int>
- <int name="QTime">3</int><!--查询耗时(毫秒)Solr有一些缓存(保存过去的搜索结果),提高了搜索效率-->
- <lst name="params"><!--查询的参数-->
- <str name="indent">on</str><!--是否缩进XML文件-->
- <str name="rows">10</str><!--返回的结果条数-->
- <str name="start">0</str><!--搜索结果的开始位置-->
- <str name="q">monitor</str>
- <str name="version">2.2</str><!--版本信息-->
- </lst>
- </lst>
- <!--numFound是找到几条,start从第几条开始显示-->
- <!--这里并没有显示得分情况(非full interface),但结果其实已经按照得分排序了(Solr默认)-->
- <!--如果是full interface查询,result会包括maxScore属性,标识最高得分-->
- <result name="response" numFound="2" start="0">
- <doc>
- <!--如果是full interface查询,这里会有得分情况(默认)
- <float name="score">0.5747526</float>
- -->
- <!--默认情况Solr会列出所有存储的fields
- (不是所有field都需要存储,虽然可能根据它来查索引,但不用包含在就结果中)
- -->
- <!--
- 注意,某些field是多值的,由arr标签标记的
- -->
- <arr name="cat"><str>electronics</str><str>monitor</str></arr>
- <arr name="features"><str>30" TFT active matrix LCD, 2560 x 1600,
- .25mm dot pitch, 700:1 contrast</str></arr>
- <str name="id">3007WFP</str>
- <bool name="inStock">true</bool>
- <str name="includes">USB cable</str>
- <str name="manu">Dell, Inc.</str>
- <str name="name">Dell Widescreen UltraSharp 3007WFP</str>
- <int name="popularity">6</int>
- <float name="price">2199.0</float>
- <str name="sku">3007WFP</str>
- <arr name="spell"><str>Dell Widescreen UltraSharp 3007WFP</str>
- </arr>
- <date name="timestamp">2008-08-09T03:56:41.487Z</date>
- <float name="weight">401.6</float>
- </doc>
- <doc>
- ...
- </doc>
- </result>
- </response>
这只是一个简单的查询结果,可以加入例如高亮显示等查询条件,然后在result标记后会有更多信息。
十二、一些统计信息
进入http://localhost:8983/solr/admin/stats.jsp。
在这里,当我们没有加载任何数据时,numDocs显示0,而现在显示19。
maxDocs的值取决于当你删除一个文档但却没有提交。
可以关注以下的一些handler:
/update,standard。
注意:这些统计信息都是实时的,不在磁盘上做保存。
十三、solrconfig.xml
这里包含很多我们可以研究的参数,现在先让我们看下<requestHandler>下定义的 request handers。
- <requestHandler name="standard" class="solr.SearchHandler"
- default="true">
- <!-- default values for query parameters -->
- <lst name="defaults">
- <!--是否显示参数,none(都不显示),all(全显示,可以看到一些隐藏参数)-->
- <str name="echoParams">explicit</str>
- <!--
- <int name="rows">10</int>
- <str name="fl">*</str>
- <str name="version">2.1</str>
- -->
- </lst>
- </requestHandler>
当我们通过POST通知Solr(如索引一个文档)或通过GET搜索,都会有个特定的request hander做处理。
这些handers可以通过URL来注册。之前我们加载文档时,Solr通过以下注册的handler做处理:
<requestHandler name="/update" class="solr.XmlUpdateRequestHandler" />
而当使用搜索时,是使用solr.SearchHandler(上面的XML定义了)
通过URL参数或POST中的参数,都可以调用这些request handler
也可以在solrconfig.xml中通过default,appends,invariants来指定。
这里的一些参数等于是默认的,就像已经放在了URL后面的参数一样。
十四、一些重要的Solr资源
- Solr's Wiki:http://wiki.apache.org/solr/ 有很多文档,以wiki的方式陈列。
- mailling lists of Solr:http://www.lucidimagination.com/search/ 很多有价值的信息。(建议订阅Solr-users mailing list)
- Solr's issue tracker:http://issues.apache.org/jira/browse/SOLR,安装JIRA。可以看到一些bug和能力增强信息。
十五、查询参数
fl=*,score&q.op=AND&start=0&rows=16&hl=true&hl.fl=merHeading&hl.snippets=3&hl.simple.pre=<font color=red>&hl.simple.post=</font>&facet=true&facet.field=merCategory&q=+(merHeading%3A%E4%BD%A0%E5%A5%BD+AND+merHeadingWithWord%3A%E6%BD%98 ) +merActualendTime:[1239264030468 TO 1240473630468]&sort=merActualendTime asc
fl表示索引显示那些field(*表示所有field, score 是solr 的一个匹配热度)
q.op 表示q 中 查询语句的 各条件的逻辑操作 AND(与) OR(或)
start 开始返回条数
rows 返回多少条
hl 是否高亮
hl.fl 高亮field
hl.snippets 不太清楚(反正是设置高亮3就可以了)
hl.simple.pre 高亮前面的格式
hl.simple.post 高亮后面的格式
facet 是否启动统计
facet.field 统计field
q 查询语句(类似SQL) 相关详细的操作还需lucene 的query 语法
sort 排序
十六、删除索引
post "<delete><id>42</id></delete>"
第二章

现在我们开始研究载入的数据部分(importing data)
在正式开始前,我们先介绍一个存储了大量音乐媒体的网站http://musicbrainz.org ,
这里的数据都是免费的,一个大型开放社区提供。
MusicBrainz每天都提供一个数据快照(snapshot)的SQL文件,这些数据可以被导入PostgreSQL数据库中。
一、字段配置(schema)
schema.xml位于solr/conf/目录下,类似于数据表配置文件,
定义了加入索引的数据的数据类型,主要包括type、fields和其他的一些缺省设置。
1、先来看下type节点,这里面定义FieldType子节点,包括name,class,positionIncrementGap等一些参数。
- name:就是这个FieldType的名称。
- class:指向org.apache.solr.analysis包里面对应的class名称,用来定义这个类型的行为。
- <schema name="example" version="1.2">
- <types>
- <fieldType name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
- <fieldType name="boolean" class="solr.BoolField" sortMissingLast="true" omitNorms="true"/>
- <fieldtype name="binary" class="solr.BinaryField"/>
- <fieldType name="int" class="solr.TrieIntField" precisionStep="0" omitNorms="true"
- positionIncrementGap="0"/>
- <fieldType name="float" class="solr.TrieFloatField" precisionStep="0" omitNorms="true"
- positionIncrementGap="0"/>
- <fieldType name="long" class="solr.TrieLongField" precisionStep="0" omitNorms="true"
- positionIncrementGap="0"/>
- <fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" omitNorms="true"
- positionIncrementGap="0"/>
- ...
- </types>
- ...
- </schema>
必要的时候fieldType还需要自己定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤,如下:
- <fieldType name="text_ws" class="solr.TextField" positionIncrementGap="100">
- <analyzer>
- <tokenizer class="solr.WhitespaceTokenizerFactory"/>
- </analyzer>
- </fieldType>
- <fieldType name="text" class="solr.TextField" positionIncrementGap="100">
- <analyzer type="index">
- <!--这个分词包是空格分词,在向索引库添加text类型的索引时,Solr会首先用空格进行分词
- 然后把分词结果依次使用指定的过滤器进行过滤,最后剩下的结果,才会加入到索引库中以备查询。
- 注意:Solr的analysis包并没有带支持中文的包,需要自己添加中文分词器,google下。
- -->
- <tokenizer class="solr.WhitespaceTokenizerFactory"/>
- <!-- in this example, we will only use synonyms at query time
- <filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt"
- ignoreCase="true" expand="false"/>
- -->
- <!-- Case insensitive stop word removal.
- add enablePositionIncrements=true in both the index and query
- analyzers to leave a 'gap' for more accurate phrase queries.
- -->
- <filter class="solr.StopFilterFactory"
- ignoreCase="true"
- words="stopwords.txt"
- enablePositionIncrements="true"
- />
- <filter class="solr.WordDelimiterFilterFactory" generateWordParts="1"
- generateNumberParts="1" catenateWords="1" catenateNumbers="1"
- catenateAll="0" splitOnCaseChange="1"/>
- <filter class="solr.LowerCaseFilterFactory"/>
- <filter class="solr.SnowballPorterFilterFactory" language="English"
- protected="protwords.txt"/>
- </analyzer>
- <analyzer type="query">
- <tokenizer class="solr.WhitespaceTokenizerFactory"/>
- <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true"
- expand="true"/>
- <filter class="solr.StopFilterFactory"
- ignoreCase="true"
- words="stopwords.txt"
- enablePositionIncrements="true"
- />
- <filter class="solr.WordDelimiterFilterFactory" generateWordParts="1"
- generateNumberParts="1" catenateWords="0" catenateNumbers="0"
- catenateAll="0" splitOnCaseChange="1"/>
- <filter class="solr.LowerCaseFilterFactory"/>
- <filter class="solr.SnowballPorterFilterFactory" language="English"
- protected="protwords.txt"/>
- </analyzer>
- </fieldType>
2、再来看下fields节点内定义具体的字段(类似数据库的字段),含有以下属性:
- name:字段名
- type:之前定义过的各种FieldType
- indexed:是否被索引
- stored:是否被存储(如果不需要存储相应字段值,尽量设为false)
- multiValued:是否有多个值(对可能存在多值的字段尽量设置为true,避免建索引时抛出错误)
- <fields>
- <field name="id" type="integer" indexed="true" stored="true" required="true" />
- <field name="name" type="text" indexed="true" stored="true" />
- <field name="summary" type="text" indexed="true" stored="true" />
- <field name="author" type="string" indexed="true" stored="true" />
- <field name="date" type="date" indexed="false" stored="true" />
- <field name="content" type="text" indexed="true" stored="false" />
- <field name="keywords" type="keyword_text" indexed="true" stored="false" multiValued="true" />
- <!--拷贝字段-->
- <field name="all" type="text" indexed="true" stored="false" multiValued="true"/>
- </fields>
3、建议建立一个拷贝字段,将所有的 全文本 字段复制到一个字段中,以便进行统一的检索:
以下是拷贝设置:
- <copyField source="name" dest="all"/>
- <copyField source="summary" dest="all"/>
4、动态字段,没有具体名称的字段,用dynamicField字段
如:name为*_i,定义它的type为int,那么在使用这个字段的时候,任务以_i结果的字段都被认为符合这个定义。如name_i, school_i
- <dynamicField name="*_i" type="int" indexed="true" stored="true"/>
- <dynamicField name="*_s" type="string" indexed="true" stored="true"/>
- <dynamicField name="*_l" type="long" indexed="true" stored="true"/>
- <dynamicField name="*_t" type="text" indexed="true" stored="true"/>
- <dynamicField name="*_b" type="boolean" indexed="true" stored="true"/>
- <dynamicField name="*_f" type="float" indexed="true" stored="true"/>
- <dynamicField name="*_d" type="double" indexed="true" stored="true"/>
- <dynamicField name="*_dt" type="date" indexed="true" stored="true"/>
schema.xml文档注释中的信息:
1、为了改进性能,可以采取以下几种措施:
- 将所有只用于搜索的,而不需要作为结果的field(特别是一些比较大的field)的stored设置为false
- 将不需要被用于搜索的,而只是作为结果返回的field的indexed设置为false
- 删除所有不必要的copyField声明
- 为了索引字段的最小化和搜索的效率,将所有的 text fields的index都设置成field,然后使用copyField将他们都复制到一个总的 text field上,然后对他进行搜索。
- 为了最大化搜索效率,使用java编写的客户端与solr交互(使用流通信)
- 在服务器端运行JVM(省去网络通信),使用尽可能高的Log输出等级,减少日志量。
2、<schema name="example" version="1.2">
- name:标识这个schema的名字
- version:现在版本是1.2
3、filedType
<fieldType name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true" />
- name:标识而已。
- class和其他属性决定了这个fieldType的实际行为。(class以solr开始的,都是在org.appache.solr.analysis包下)
可选的属性:
- sortMissingLast和sortMissingFirst两个属性是用在可以内在使用String排序的类型上(包括:string,boolean,sint,slong,sfloat,sdouble,pdate)。
- sortMissingLast="true",没有该field的数据排在有该field的数据之后,而不管请求时的排序规则。
- sortMissingFirst="true",跟上面倒过来呗。
- 2个值默认是设置成false
StrField类型不被分析,而是被逐字地索引/存储。
StrField和TextField都有一个可选的属性“compressThreshold”,保证压缩到不小于一个大小(单位:char)
<fieldType name="text" class="solr.TextField" positionIncrementGap="100">
solr.TextField 允许用户通过分析器来定制索引和查询,分析器包括 一个分词器(tokenizer)和多个过滤器(filter)
- positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误。
<tokenizer class="solr.WhitespaceTokenizerFactory" />
空格分词,精确匹配。
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1"catenateAll="0" splitOnCaseChange="1" />
在分词和匹配时,考虑 "-"连字符,字母数字的界限,非字母数字字符,这样 "wifi"或"wi fi"都能匹配"Wi-Fi"。
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" />
同义词
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
在禁用字(stopword)删除后,在短语间增加间隔
stopword:即在建立索引过程中(建立索引和搜索)被忽略的词,比如is this等常用词。在conf/stopwords.txt维护。
4、fields
<field name="id" type="string" indexed="true" stored="true" required="true" />
- name:标识而已。
- type:先前定义的类型。
- indexed:是否被用来建立索引(关系到搜索和排序)
- stored:是否储存
- compressed:[false],是否使用gzip压缩(只有TextField和StrField可以压缩)
- mutiValued:是否包含多个值
- omitNorms:是否忽略掉Norm,可以节省内存空间,只有全文本field和need an index-time boost的field需要norm。(具体没看懂,注释里有矛盾)
- termVectors:[false],当设置true,会存储 term vector。当使用MoreLikeThis,用来作为相似词的field应该存储起来。
- termPositions:存储 term vector中的地址信息,会消耗存储开销。
- termOffsets:存储 term vector 的偏移量,会消耗存储开销。
- default:如果没有属性需要修改,就可以用这个标识下。
<field name="text" type="text" indexed="true" stored="false" multiValued="true" />
包罗万象(有点夸张)的field,包含所有可搜索的text fields,通过copyField实现。
<copyField source="cat" dest="text" />
在添加索引时,将所有被拷贝field(如cat)中的数据拷贝到text field中
作用:
- 将多个field的数据放在一起同时搜索,提供速度
- 将一个field的数据拷贝到另一个,可以用2种不同的方式来建立索引。
<dynamicField name="*_i" type="int" indexed="true" stored="true" />
如果一个field的名字没有匹配到,那么就会用动态field试图匹配定义的各种模式。
- "*"只能出现在模式的最前和最后
- 较长的模式会被先去做匹配
- 如果2个模式同时匹配上,最先定义的优先
<dynamicField name="*" type="ignored" multiValued="true" />
如果通过上面的匹配都没找到,可以定义这个,然后定义个type,当String处理。(一般不会发生)
但若不定义,找不到匹配会报错。
5、其他一些标签
<uniqueKey>id</uniqueKey>
文档的唯一标识, 必须填写这个field(除非该field被标记required="false"),否则solr建立索引报错。
<defaultSearchField>text</defaultSearchField>
如果搜索参数中没有指定具体的field,那么这是默认的域。
<solrQueryParser defaultOperator="OR" />
配置搜索参数短语间的逻辑,可以是"AND|OR"。
二、solrconfig.xml
1、索引配置
mainIndex 标记段定义了控制Solr索引处理的一些因素.
-
useCompoundFile:通过将很多 Lucene 内部文件整合到单一一个文件来减少使用中的文件的数量。这可有助于减少 Solr 使用的文件句柄数目,代价是降低了性能。除非是应用程序用完了文件句柄,否则
false的默认值应该就已经足够。 - useCompoundFile:通过将很多Lucene内部文件整合到一个文件,来减少使用中的文件的数量。这可有助于减少Solr使用的文件句柄的数目,代价是降低了性能。除非是应用程序用完了文件句柄,否则false的默认值应该就已经足够了。
- mergeFacor:决定Lucene段被合并的频率。较小的值(最小为2)使用的内存较少但导致的索引时间也更慢。较大的值可使索引时间变快但会牺牲较多的内存。(典型的 时间与空间 的平衡配置)
- maxBufferedDocs:在合并内存中文档和创建新段之前,定义所需索引的最小文档数。段 是用来存储索引信息的Lucene文件。较大的值可使索引时间变快但会牺牲较多内存。
- maxMergeDocs:控制可由Solr合并的 Document 的最大数。较小的值(<10,000)最适合于具有大量更新的应用程序。
- maxFieldLength:对于给定的Document,控制可添加到Field的最大条目数,进而阶段该文档。如果文档可能会很大,就需要增加这个数值。然后,若将这个值设置得过高会导致内存不足错误。
- unlockOnStartup:告知Solr忽略在多线程环境中用来保护索引的锁定机制。在某些情况下,索引可能会由于不正确的关机或其他错误而一直处于锁定,这就妨碍了添加和更新。将其设置为true可以禁用启动索引,进而允许进行添加和更新。(锁机制)
2、查询处理配置
query标记段中以下一些与缓存无关的特性:
- maxBooleanClauses:定义可组合在一起形成以个查询的字句数量的上限。正常情况1024已经足够。如果应用程序大量使用了通配符或范围查询,增加这个限制将能避免当值超出时,抛出TooMangClausesException。
- enableLazyFieldLoading:如果应用程序只会检索Document上少数几个Field,那么可以将这个属性设置为true。懒散加载的一个常见场景大都发生在应用程序返回一些列搜索结果的时候,用户常常会单击其中的一个来查看存储在此索引中的原始文档。初始的现实常常只需要现实很短的一段信息。若是检索大型的Document,除非必需,否则就应该避免加载整个文档。
query部分负责定义与在Solr中发生的时间相关的几个选项:
概念:Solr(实际上是Lucene)使用称为Searcher的Java类来处理Query实例。Searcher将索引内容相关的数据加载到内存中。根据索引、CPU已经可用内存的大小,这个过程可能需要较长的一段时间。要改进这一设计和显著提高性能,Solr引入了一张“温暖”策略,即把这些新的Searcher联机以便为现场用户提供查询服务之前,先对它们进行“热身”。
- newSearcher和firstSearcher事件,可以使用这些事件来制定实例化新Searcher或第一个Searcher时,应该执行哪些查询。如果应用程序期望请求某些特定的查询,那么在创建新Searcher或第一个Searcher时就应该反注释这些部分并执行适当的查询。
query中的智能缓存:
- filterCache:通过存储一个匹配给定查询的文档 id 的无序集,过滤器让 Solr 能够有效提高查询的性能。缓存这些过滤器意味着对Solr的重复调用可以导致结果集的快速查找。更常见的场景是缓存一个过滤器,然后再发起后续的精炼查询,这种查询能使用过滤器来限制要搜索的文档数。
- queryResultCache:为查询、排序条件和所请求文档的数量缓存文档 id 的有序集合。
- documentCache:缓存Lucene Document,使用内部Lucene文档id(以便不与Solr唯一id相混淆)。由于Lucene的内部Document id 可以因索引操作而更改,这种缓存不能自热。
- Named caches:命名缓存是用户定义的缓存,可被 Solr定制插件 所使用。
其中filterCache、queryResultCache、Named caches(如果实现了org.apache.solr.search.CacheRegenerator)可以自热。
每个缓存声明都接受最多四个属性:
- class:是缓存实现的Java名
- size:是最大的条目数
- initialSize:是缓存的初始大小
- autoWarmCount:是取自旧缓存以预热新缓存的条目数。如果条目很多,就意味着缓存的hit会更多,只不过需要花更长的预热时间。
对于所有缓存模式而言,在设置缓存参数时,都有必要在内存、cpu和磁盘访问之间进行均衡。统计信息管理页(管理员界面的Statistics)对于分析缓存的 hit-to-miss 比例以及微调缓存大小的统计数据都非常有用。而且,并非所有应用程序都会从缓存受益。实际上,一些应用程序反而会由于需要将某个永远也用不到的条目存储在缓存中这一额外步骤而受到影响。
第三章
一、在Tomcat中安装运行Solr
- 下载Solr包,找到dist文件夹中的appache-solr-1.4.0.war。将它拷贝到tomcat的webapps下,改名为solr.war(之后访问的路径为/solr)。
- 在webapp下建立同war包名一样的文件夹(这里就是solr),将example/solr下的所有文件拷贝到这个目录下(这里是一些样例的配置)
- 在tomcat的conf/Catalina/localhost文件夹下面建立solr.xml,设定solr的根目录。
- <!--其中的路径都是相对于tomcat的bin目录-->
- <Context docBase="../webapps/solr.war" debug="0" crossContext="true" >
- <Environment name="solr/home" type="java.lang.String"
- value="../webapps/solr" override="true" />
- </Context>
最后启动tomcat,访问http://localhost:8080/solr。
二、运行多个Solr
1、在/webapps/solr下建立solr.xml
- <?xml version="1.0" encoding="UTF-8" ?>
- <solr persistent="false">
- <cores adminPath="/admin/cores">
- <core name="core0" instanceDir="core0" />
- <core name="core1" instanceDir="core1" />
- </cores>
- </solr>
2、在/webapps/solr下,新建对应的core0,core1文件夹。
拷贝conf(示例的配置文件,正常产品中自己配置schema.xml等)到core0和core1中。
默认情况下索引文件将保存在同一个目录中(各自根目录的data中),也可以配置:
- <?xml version="1.0" encoding="UTF-8" ?>
- <solr persistent="false">
- <cores adminPath="/admin/cores">
- <core name="core0" instanceDir="core0" >
- <property name="dataDir" value="/data/core0"/>
- </core>
- <core name="core1" instanceDir="core1" />
- </cores>
- </solr>
3、启动Tomcat,访问http://localhost:8080/solr 看到以下2个实例即成功。