有监督学习(Supervised Learning)是指这样的一种场景:
有一组数量较多的历史样本集,其中每个样本有一组特征(features)和一个或几个标示其自身的类型或数值的标签(label);对历史样本学习得到模型后,可以用新样本的特征预测其对应的标签。
- 场景
在有监督学习中可以将每条数据看成是一条由特征到标签的映射,训练的目的是找出映射的规律。根据标签的类型可以将有监督学习再分为两个子类:
分类(Classification):标签是可数的离散类型,比如疾病诊断(疾病的类型有限)、图像文字识别(文字的总量有限)。
回归(Regression):标签是不可数的连续类型、有大小关系,比如房价预测(值无法枚举)。
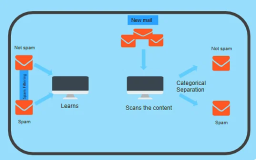
图1-8是一个胸科诊断的分类案例。
图1-8 分类学习示例
图1-8中的年龄、血液PH值、是否吸烟就是模型的特征,诊断结果(肺气肿/正常)是学习的标签。
注意:图1-8中分类问题的特征变量也可以是连续类型(年龄、PH值)。
- 算法
有监督学习是机器学习中最易理解、发展最成熟的一个领域,其应用最广泛算法可以分成以下几类:
线性分析(Linear Analysis):来源于统计学,这其中众所周知的最小二乘法(Ordinary Least Squares,OLS)是优化目标最易理解的回归学习算法;通过对优化目标的调整还衍生了Ridge Regression、Lasso Regression等算法。此外还包括线性判别分析(Linear Discriminant Analysis)。
梯度下降法(Gradient Descent):用于寻找函数最小值或最大值问题。主要包括三个分支:批量梯度下降法BGD、随机梯度下降法SGD、小批量梯度下降法MBGD。
朴素贝叶斯(Naïve Bayes):基于概率论的分类方法。在贝叶斯理论中,该方法要求所有特征之间相互独立,但2004年Harry Zhang的论文《The Optimality of Naive Bayes》中阐述了特征之间有比较平和的关联时朴素贝叶斯也能达到很好效果。
决策树(Decision Tree):源自风险管理的辅助决策系统,是一个利用树状模型的决策支持工具,根据其建分支的策略不同派生了很多子算法,如ID3、C4.5、CART等。其优点是学习结果易于人类理解,缺点是当数据集变化时决策图变化较大。
支持向量机(Support Vector Machine,SVM):上世纪六十年代就被提出,直到1992由Bernhard E.Boser等人改进为可以应用于非线形问题后被广泛应用,在本世纪初期的很长时间里被认为是最好的分类器。
神经网络(Neutral Network,NN):由名称可知源于生物神经学,具有较长历史,可以处理复杂的非线形问题。传统神经网络的研究曾一度停滞,但随着计算机计算能力的提升和卷积网络结构的提出,由其发展而来的深度学习(Deep Learning)已经成为当前机器学习中最强大的工具。
集成学习(Ensemble Learning):是一种利用若干个基础分类器共同执行决策的方法。此方法近来被广泛应用,其中的随机森林(Random Forrest)正在逐步取代SVM的地位;此外还有以AdaBoost为代表的提升方法(Boosting Methods)。
所有的有监督学习算法都有一定的容错性,即不要求所有历史样本绝对正确、可以有部分标签被错误分配的样本。当然,样本中的错误越多越不容易训练出正确的模型。
- 回归与分类的关系
读者应该已经发现:虽然有监督学习的适用场景可以分成两类,但介绍算法时并没有区分哪些适用于回归,哪些适用于分类。其实大多数的算法都可以同时处理这两类问题。如图1-9,假设某算法可以处理回归问题,那么当然可以将其值域划分成可数的几段用以表征分类问题。
图1-9 回归模型可以解决分类问题
图1-9中,左图是训练的原始样本;用线性回归学习后可得到中图的回归线,回归线上的点就是之后的预测点;右图示意对回归结果设置阀值可以用来表达分类问题。从这个角度看,回归与分类的区别只不过是从不同角度分析学习结果而已。
另一方面,如果一个模型可以解决分类问题,则在分类类别之间作线性插值就是一种最简单的将分类模型转化为回归模型的方法。
因此,与很多教程书籍不同,本书不刻意区分它们,将有监督学习算法详细原理与实践的介绍统一在了第3章。此外考虑内容的连贯性将神经网路方面的内容放在深度学习章节一起讲解。
**从机器学习,到深度学习
从深度学习,到强化学习
从强化学习,到深度强化学习
从优化模型,到模型的迁移学习
一本书搞定!**