0 相关源码
1 k-平均算法(k-means clustering)概述
1.1 回顾无监督学习
◆ 分类、回归都属于监督学习
◆ 无监督学习是不需要用户去指定标签的
◆ 而我们看到的分类、回归算法都需要用户输入的训练数据集中给定一个个明确的y值
1.2 k-平均算法与无监督学习
◆ k-平均算法是无监督学习的一种
◆ 它不需要人为指定一个因变量,即标签y ,而是由程序自己发现,给出类别y
◆ 除此之外,无监督算法还有PCA,GMM等
源于信号处理中的一种向量量化方法,现在则更多地作为一种聚类分析方法流行于数据挖掘领域。
k-平均聚类的目的是:把n 个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。
这个问题将归结为一个把数据空间划分为Voronoi cells的问题。
一般情况下,都使用效率比较高的启发式算法,它们能够快速收敛于一个局部最优解。
这些算法通常类似于通过迭代优化方法处理高斯混合分布的最大期望算法(EM算法)。
而且,它们都使用聚类中心来为数据建模;然而k-平均聚类倾向于在可比较的空间范围内寻找聚类,期望-最大化技术却允许聚类有不同的形状。
k-平均聚类与k-近邻之间没有任何关系(后者是另一流行的机器学习技术)。
2 k-平均算法原理
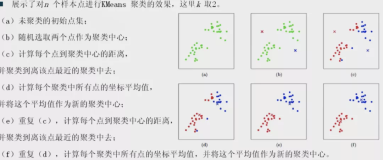
2.1 k-平均算法描述
◆ 设置需要聚类的类别个数K ,以及n个训练样本,随机初始化K个聚类中心
◆ 计算每个样本与聚类中心的距离,样本选择最近的聚类中心作为其
类别;重新选择聚类中心
◆ 迭代执行上一步,直到算法收敛
- 算法图示


3 Kmeans算法实战

k-means是最常用的聚类算法之一,它将数据点聚类成预定义数量的聚类
MLlib实现包括一个名为kmeans ||的k-means ++方法的并行变体。
KMeans作为Estimator实现,并生成KMeansModel作为基本模型。


- 代码

- 结果

4 LDA算法概述
4.1 LDA算法介绍
◆ LDA即文档主题生成模型 ,该算法是一种无监督学习
◆ 将主题对应聚类中心,文档作为样本,则LDA也是一种聚类算法
◆ 该算法用来将多个文档划分为K个主题 ,与Kmeans类似
隐含狄利克雷分布(英语:Latent Dirichlet allocation,简称LDA),是一种[主题模型],它可以将文档集中每篇文档的主题按照[概率分布]的形式给出。
同时它是一种[无监督学习]算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可。
此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。
LDA首先由 David M. Blei、吴恩达和迈克尔·I·乔丹 "迈克尔·乔丹 (学者)")于2003年提出,目前在[文本挖掘]领域包括文本主题识别、文本分类以及文本相似度计算方面都有应用。
5 LDA算法原理
5.1 LDA算法概述
◆ LDA是一种基于概率统计的生成算法
◆ 一种常用的主题模型,可以对文档主题进行聚类,同样也可以用在其他非文档的数据中
◆ LDA算法是通过找到词、文档与主题三者之间的统计学关系进行推断的
5.2 LDA算法的原理
◆ 文档的条件概率可以表示为

6 LDA算法实践

LDA实现为支持EMLDAOptimizer和OnlineLDAOptimizer的Estimator,并生成LDAModel作为基本模型。如果需要,专家用户可以将EMLDAOptimizer生成的LDAModel转换为DistributedLDAModel。

- 代码

- prediction.show()

- topics.show(false)