本文转载自:https://zhuanlan.zhihu.com/p/49499385
我们在这篇文章介绍最新版本(1.8.1版本)的Alluxio如何通过使用指纹特性和底层存储批量操作加快Alluxio元数据操作。元数据操作是所有文件系统的重要组成部分。其性能对于像Alluxio这样一个经常管理几个大型底层文件系统的存储系统来说更加关键。本文详细介绍了我们最近在Alluxio 1.8.1版本中所做的两个优化,以显著地提升大规模递归加载元数据操作的性能。
概述
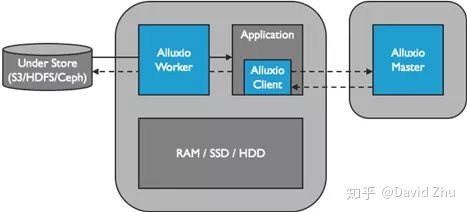
Alluxio的主要功能之一是提供简单而统一的接口,用来管理不同底层存储系统内的文件和目录。即使底层存储系统可能是具有不同接口类型的对象存储,Alluxio也可以充当中间层,并提供一个统一的文件接口供应用程序与多个底层存储系统进行交互。这在将应用程序从本地服务器迁移到云服务的场景中非常常见,本地部署的应用程序使用POSIX之类的文件接口处理本地存储,而云存储使用S3之类的对象存储接口访问数据。在应用程序和存储系统之间使用Alluxio可以节省大量开发时间,否则需要花费大量精力将应用程序从原始文件接口更改为对象存储接口。
挑战
与其他底层存储系统相比,对象存储通常是远程部署的,访问速度较慢。用户在使用Alluxio的文件系统接口时,可能会无意间频繁触发对这些对象储存的远程访问。当用户递归地调用某些涉及大量文件的元数据操作(ls或chmod / chgrp)时,由于会频繁调用底层对象存储接口,元数据访问速度将会更慢。本文关注了最近在Alluxio中针对加速这些元数据操作所做的一些优化。
加速Alluxio/底层存储同步
自从Alluxio v1.7问世以来,指纹串技术已经被用来检测文件或目录是否已经改变。这可以让Alluxio快速确定Alluxio中的文件与S3存储中的文件或其他对象存储(底层存储)中的文件是否同步。当用户不通过Alluxio而直接在底层存储中修改一个文件可能会发生这种不同步的情况。当指纹不同步时,将执行底层存储同步操作。1.8版本通过将指纹划分为两个组件(元数据组件和内容组件)改进了这一特性,从而进一步减少了Alluxio和底层存储之间所需的同步次数。
在此使用双组件指纹技术之前,如果底层文件系统(UFS)中文件/对象(所有者、模式等)的元数据发生更改,那么Alluxio则认为整个文件都不再同步,并认为对应的整个文件将无效。这可能会导致不必要的文件失效和数据的重新加载,从而增加大规模元数据操作的成本,比如在包含许多文件和目录的目录上递归地更改权限。元数据操作本身并不一定很慢,但是后续的文件内容操作会慢一些,因为在下一次读取操作中,Alluxio必须重新加载文件内容。
通过将文件元数据指纹和文件内容指纹分离开来,当文件只有元数据发生更改时,只有文件元数据的指纹是不同的,而文件内容的指纹并没有发生变化。因此,Alluxio不需要从底层存储重新加载数据,而是可以直接在内存中更新元数据。因此,在只有元数据发生更改的情况下,这是一种低成本的同步底层存储系统和Alluxio元数据的方法。
加速递归执行的命令ListStatus和DiskUsage
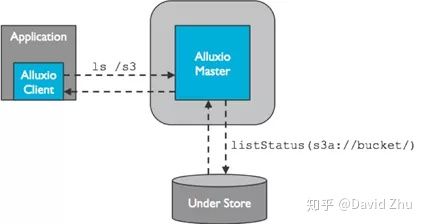
最常用的元数据操作之一是listStatus操作或ls命令。用户经常通过命令行以交互的方式使用这两个命令。从用户的角度来看,在交互过程中任何高延迟都是不可取的。此外,这些命令还用于许多分布式计算框架,如Spark和MapReduce,因此效率的提高可以加速计算任务的执行。listStatus的选项之一是递归选项。使用recursive选项,用户可以递归地查询整个文件夹的元数据信息。这通常会导致查询很多的文件和目录,因此会非常耗时。
实验结果表明,文件系统主节点为了查询元数据信息,需要调用底层存储系统接口,而事实上该过程是执行上述命令的瓶颈。对于将对象存储作为其底层存储进行部署来说,此问题更加严重。因为这些对象存储通常是远程部署的,因此listStatus等操作通常比在同一处部署的文件系统(如HDFS)慢。提高listStatus递归操作性能的关键是减少对底层存储的调用。
Alluxio最近引入了两个特性,改善了listStatus调用的性能。首先,Alluxio v1.8开始利用一些对象存储(如Amazon S3)支持递归listStatus调用这一特性。通过一次API调用,Alluxio可以获得整个文件和目录列表及其元数据。此外,Alluxio可以缓存从这个递归调用中获得的信息以用于其他场合,如指纹生成和验证。
此外,1.8.1版本的Alluxio还包含了另一项优化:当由于从底层存储系统加载元数据而在Alluxio空间中创建了一个文件时,因为文件是从底层存储系统端开始创建的,因此文件应该已经存在于底层存储系统中了,Alluxio将不会把文件信息持久化到底层存储系统中。
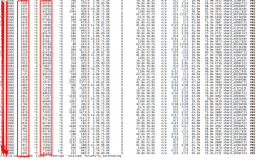
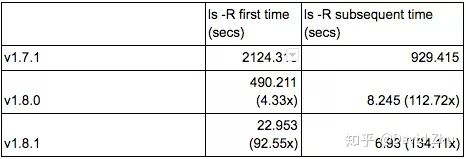
联合这两种优化的效果是,对底层存储系统的调用操作的时间复杂度将从O(n)减少至O(1),其中n代表被查询的文件数量。我们通过实验评估了该优化的效果。我们创建一个具有深层嵌套的目录结构,每一层有10个或4个目录,总共有10000个文件。实验在本地机器上部署了Alluxio并将Amazon S3作为底层存储。通过对比Alluxio 1.7.1版本和Alluxio 1.8.0版本的性能,首次运行listStatus递归操作时性能有了一定的改进,运行时间能够减少75%。第二次调用listStatus递归命令的运行时间则大大减少,时间从900秒减少到8秒。
Alluxio 1.8.1版本则显著提高了ls –R命令的首次运行耗时性能。联合优化后第一次ls –R命令的时间从2000秒以上降低到20秒左右,随后ls –R命令运行时间仅为7秒左右。下表总结了每次优化后递归执行listStatus的运行时间。
结论
元数据操作是所有文件系统的重要组成部分。其性能对于像Alluxio这样一个经常管理几个大型底层文件系统的存储系统来说更加关键。本文详细介绍了我们最近在Alluxio 1.8.1版本中所做的两个优化,以显著地提升大规模递归加载元数据操作的性能。该优化改善了在命令行界面使用ls和du查询Alluxio文件的用户体验。此外,这些优化还加快了一个名为UFS sync的进程的执行,该进程旨在保持UFS和Alluxio命名空间之间的文件同步。
未来的工作
元数据管理是Alluxio的关键部分,在本文中我们详细介绍了最近为提高元数据载入速度所做的一些优化。与此同时,我们还在研究如何更有效地同步底层存储系统元数据和存储在Alluxio master中的元数据。除了速度和效率之外,我们还致力于元数据管理的可扩展性。我们希望扩展元数据管理,以支持管理更大规模的文件数量。本文中介绍的改进和未来的改进工作如下:
- 在内容相关信息和元数据相关信息之间划分UFS指纹(ALLUXIO-3150, https://alluxio.atlassian.net/browse/ALLUXIO-3150)
- 在底层存储系统中使用递归listStatus实现loadMetadata (ALLUXIO-3205, https://alluxio.atlassian.net/browse/ALLUXIO-3205)
- 减少在loadMetadata中与底层存储系统交互的数量(ALLUXIO-3300, https://alluxio.atlassian.net/browse/ALLUXIO-3300)
在 Alluxio 1.8.1版本发布说明(https://www.alluxio.org/download/releases/alluxio-181-release)中阅读更多内容
作者简介:朱禹 (David Zhu) 是Alluxio的软件工程师。 加入Allxuio之前, 曾在Google, Intel Research从事分布式系统及系统安全性的研究。博士毕业于UC Berkeley计算机系,博士期间参与了众核操作系统Akaros以及分布式数据库的结构演变的研究与开发。