摘要:在中国HBase技术社区第十届meetup--HBase生态实践 (杭州站)上,阿里云技术专家郭泽晖为大家介绍了云HBase之时序引擎OpenTSDB的介绍及压缩优化,向大家展示了使用OpenTSDB所遇到的一些问题及优化方案,并对云OpenTSDB的集中使用模式进行了相应的介绍。
本文根据演讲视频以及PPT整理而成。
本文将主要围绕以下四个方面进行分享:
- OpenTSDB的介绍
- OpenTSDB的常见问题
- OpenTSDB的压缩优化
- 云OpenTSDB的使用模式
本文首先会对OpenTSDB简单介绍,以及使用OpenTSDB时所遇到的常见问题,之后则会重点介绍相对于社区版的OpenTSDB所做的相应改进,最后介绍云OpenTSDB的几种使用模式。
一、OpenTSDB的介绍
OpenTSDB是一款基于HBase构建的时序数据库,时序数据具有以下特点:
(1)数据为数值类型,常用于监控。
(2)数据通常按照时间顺序抵达。
(3)数据基本不会被更新。
(4)写入较多,读入较少。目前用户在阿里云上部署时序数据库所选择的架构通常为对SLB进行挂载后,对一定数量的OpenTSDB进行部署,最后底层与HBase相关联。

OpenTSDB对时序数据具有如下定义,首先在数据存储过程中会创建Metric,可以理解为一个监控的group,并用Tags对数据进行进一步的标识,Metric+Tags的组合代表一个具体的时间线,每一条时间线上会存储多个数据点,其中数据点是一个包含时间和值的二元组,每一条时间线会不断的产生相关数据并进行写入。对于时间精度,OpenTSDB支持秒级和毫秒级的时间精度,在写入的数据中如果数据点的时间戳为10位,则时间精度为秒,如果写入的时间戳为13位,则时间精度为毫秒。接下来简单介绍一下OpenTSDB的存储结构,以写metric=host.cpu, timestamp=1552643656, tags={region:HangZhou,host:30,43,111,255}, value=100为例,这条数据到达HBase存储层后经过了如下转换,其中存储数据metric=host.cpu时,将其映射成唯一UID进行存储。为了减少存储空间,每条时间线每一小时存储一行。因此对于timestamp=1552643656,会将数据转换成小时的起始整秒,同样,对于tags的信息,也会映射成唯一UID进行存储。至此整个RowKey部分便存储完成,对于Column部分,将会记录和这个小时起始时间的偏移量,以及value的值。

下面对RowKey和Column的数据格式进行更为详细的介绍,实际上,为了避免同一个Metric拥有很多条时间线导致的写入热点问题,在Metric前面会有加盐的一位数据salt,来打散同一Metric下不同时间线的热点。同时Metric和Tag的默认长度为3个字节,即最多只能分配16777216个UID,为了防止UID超量的问题,可以通过修改相应的参数(tsd.storage.uid.width.metric, tsd.storage.uid.width.tagk, tsd.storage.uid.width.tagv)来进行调整,但需要注意的是,一旦集群已经写入数据后参数便无法再次进行修改。对于Column部分的数据格式来说,秒级和毫秒级的数据格式是有差异的,毫秒级的数据需要更多的空间来进行存储,
二、OpenTSDB的常见问题
接下来介绍OpenTSDB的常见问题,在上文提到,为了避免同一个Metric拥有很多条时间线导致的写入热点问题,会通过对数据加盐一位来将热点打散,但打散后会将Metric分到多个buckets中,此时在进行查询时,有多少个buckets便会并发多少个查询请求到HBase中,此时便有了写入热点与并发查询的权衡问题,过多的并发度很容易将HBase打爆,因此需要考虑实际的HBase的业务规模来进行参数的设置。同样需要注意的一点,该项设置写入数据后,也无法进行修改。

第二个问题是Tags的笛卡儿积影响查询效率,假设一个监控机器CPU情况的mertric=host.cpu有三个tag,分别是机房区域region,主机名host,cpu单核编号core。这三个tag的数量分别为10,100,8。那么该mertric会包含101008=8000条时间线,假使现在需要查询某一条时间线上的数据,也需要访问8000条时间线上的数据才能得到所需要的结果,其根本原因在于tag是没有索引的,目前常见的解决办法主要有两种,一种是将tag提至RowKey前,来进行索引的建立,另一种是在RowKey中拼接tag的部分信息来减少笛卡儿积。OpenTSDB还有一些其他的查询问题,比如数据不是流式处理,数据点要全部放入到TSDB内存后才会开始进行聚合处理,容易OOM;一个大的查询只会分配给一台TSDB上进行处理,不能分布式处理;即使只查询15分钟的数据,也需要遍历一小时的数据等。

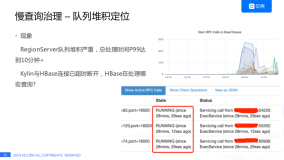
第三个问题便是OpenTSDB的压缩问题,即整点压缩对HBase产生流量冲击。为了节省存储空间,OpenTSDB会将离散的KV合成为一个大的KV,来减少重复字段,所以在整点时间便会有读取-压缩-重写-删除一系列的操作产生,这些操作会对HBase发起大量的IO请求,导致长时间的数倍流量波峰,很容易将HBase打爆。因此需要更高的机器规模来抵抗波峰。

三、OpenTSDB的压缩优化
事实上,如果能够消除流量波峰,可以极大的降低运营成本,提高系统的稳定性。传统数据压缩的步骤是先从HBase中读取上一个小时写入的所有数据,然后在OpenTSDB中压缩这些读出的数据,并将压缩好的数据写入HBase中,最后将旧的数据从HBase中删除,可以看出压缩数据中存在了大量的OpenTSDB对于HBase的IO请求。为了解决这一问题,需要对OpenTSDB的压缩进行优化,具体的实现思路是将OpenTSDB的压缩过程下沉到底层HBase中,因为HBaes自身压缩数据时便会对数据进行读写,在此时对数据进行处理,复用HBase压缩过程的流量,在合并HFile的时候将KV按照OpenTSDB的数据格式进行合并,便可以避免OpenTSDB对HBase发起大量的IO请求,从而避免了流量波峰。

四、云OpenTSDB的使用模式
最后介绍一下云OpenTSDB的几种使用模式,一种是独享模式,即完全独立部署的时序数据库,适合时序业务较重,需要分离部署的情况。

另一种是共享模式,可以复用已经购买的云HBase,适合时序业务较小,或者使用HBase云资源较小的情况,可以在一定程度上节约成本。