
本文将通过一系列的天鹅图片来解释卷积神经网络(CNN)的概念,并使用CNN在常规多层感知器神经网络上处理图像。

图像分析
假设我们要创建一个能够识别图像中的天鹅的神经网络模型。
天鹅具有某些特征,可用于帮助确定天鹅是否在图片中存在,例如长颈、白色等。

天鹅具有某些可用于识别目的的特征
对于某些图像,可能难以确定是否存在天鹅,请看以下图像。

很难区分的天鹅形象
这些特征仍然存在于上图中,但我们却难以找出上文提出的特征。除此之外,还会有一些更极端的情况。

天鹅分类的极端情况
至少颜色是一致的,对吧? 还是......

不要忘记这些黑天鹅。
情况可以更糟吗?绝对可以。

最坏的情况
好的,现在已经有了足够多的天鹅照片。
我们来谈谈神经网络。
现如今,我们基本上一直在以非常天真的方式谈论检测图像中的特征。研究人员构建了多种计算机视觉技术来处理这些问题:SIFT,FAST,SURF,Brief等。然而,出现了类似的问题:探测器要么过于笼统,要么过于设计化,这使得它们太简单或难以概括。
· 如果我们学习了要检测的功能,该怎么办?
· 我们需要一个可以进行表征学习(或特征学习)的系统。
表征学习是一种允许系统自动查找给定任务的相关特征的技术。替换手动功能工程。有以下几种技巧:
· 无监督(K-means,PCA,......)
· 监督(Sup. 字典学习,神经网络!)
传统神经网络的问题
假设你已经熟悉了被称为多层感知器(MLP)的传统神经网络。如果你不熟悉这些内容,那么网络上有数百篇有关MLP工作方式的教程。这些是在人脑上建模的,其中神经元由连接的节点刺激,并且仅在达到特定阈值时才被激活。
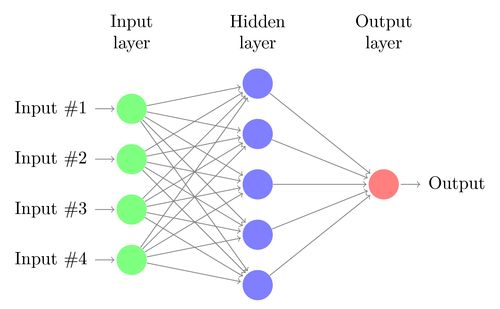
标准多层感知器(传统神经网络)
MLP有几个缺点,特别是在图像处理方面。MLP对每个输入使用一个感知器(例如,图像中的像素,在RGB情况下乘以3)。对于大图像,权重量迅速变得难以操纵。对于具有3个颜色通道的224 x 224像素图像,必须训练大约150,000个重量!结果,困难发生在训练和过度拟合的时候。
另一个常见问题是MLP对输入(图像)及其移位版本的反应不同——它们不是平移不变的。例如,如果猫的图片出现在一张图片的左上角和另一张图片的右下角,则MLP会尝试自我纠正并认为猫将始终出现在图像的这一部分中。
很明显,MLP不是用于图像处理的最佳思路。 其中一个主要问题是当图像变平为MLP时,空间信息会丢失。靠近的节点很重要,因为它们有助于定义图像的特征。
因此,我们需要一种方法来利用图像特征(像素)的空间相关性,这样我们就可以看到图片中的猫,无论它出现在何处。在下图中,我们正在学习冗余功能。这种方法并不健全,因为猫可能出现在另一个位置。

使用MLP的猫探测器,随着猫的位置改变而改变。
开始CNN之旅
现在让我们继续讨论CNN如何用于解决大多数问题。

CNN利用了附近像素与远距离像素相关性更强的事实
通过使用称为过滤器的东西,我们分析了附近像素的影响。采用指定尺寸的过滤器(经验法则为3x3或5x5),然后将过滤器从图像左上角移到右下角。对于图像上的每个点,使用卷积运算基于滤波器计算值。
过滤器可能与任何东西有关,对于人类的照片,一个过滤器可能与看到鼻子有关,而我们的鼻子过滤器会让我们看到鼻子在图像中出现的强度,以及多少次和在它们发生的位置。与MLP相比,这减少了神经网络必须学习的权重数量,并且还意味着当这些特征的位置发生变化时,它不会抛弃神经网络。
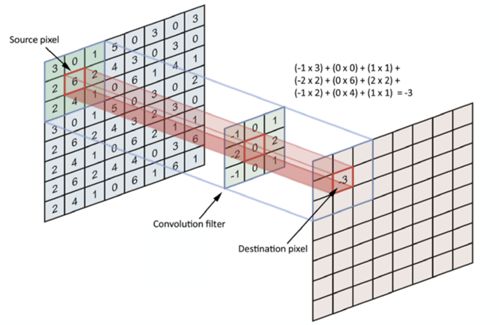
卷积运算
如果你想知道如何通过网络学习不同的功能,以及网络是否可能学习相同的功能(10个头部过滤器会有点多余),这种情况基本不会发生。在构建网络时,我们随机指定过滤器的值,然后在网络训练时不断更新。除非所选滤波器的数量极其大,否则产生两个相同的滤波器的可能性是非常非常小的。
下面给出了称之为过滤器或内核的示例。
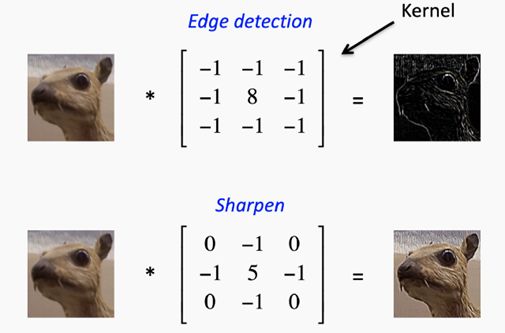
CNN的内核过滤器示例
在过滤器经过图像之后,为每个过滤器生成特征映射。然后通过激活函数获取这些函数,激活函数决定图像中给定位置是否存在某个特征。然后我们可以做很多事情,例如添加更多过滤层和创建更多特征映射。随着我们创建更深入的CNN,这些映射变得越来越抽象。我们还可以使用池化图层来选择要素图上的最大值,并将它们用作后续图层的输入。理论上,任何类型的操作都可以在池化层中完成,但实际上,只使用最大池,因为我们想要找到极端值——这就是我们的网络看到该功能的时候!
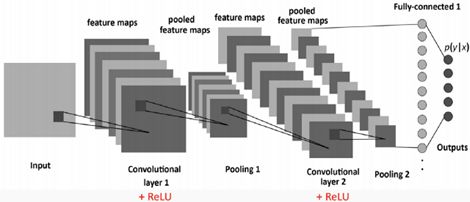
示例CNN具有两个卷积层,两个合并层和一个完全连接的层,它将图像的最终分类决定为几个类别之一。
只是重申我们迄今为止所发现的内容。我们知道MLP:
· 不能很好地缩放图像
· 忽略像素位置和邻居关联带来的信息
· 无法处理翻译
CNN的一般思维是智能地适应图像的属性:
· 像素位置和邻域具有语义含义
· 感兴趣的元素可以出现在图像的任何位置
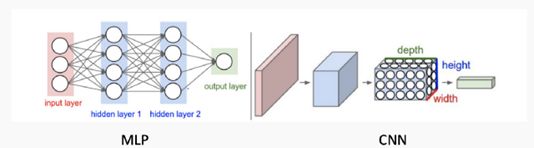
MLP和CNN的体系结构比较
CNN也由层组成,但这些层没有完全连接:它们具有滤镜,在整个图像中应用的立方体形状的权重集。过滤器的每个2D切片称为内核。这些过滤器引入了平移不变性和参数共享。它们是如何应用的?当然是卷积!
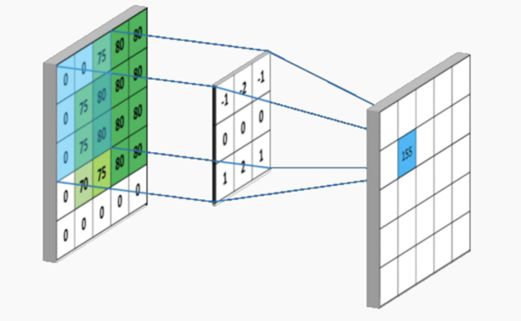
该示例表明了如何使用内核过滤器将卷积应用于图像
现在有一个问题是:图像边缘会发生什么?如果我们在正常图像上应用卷积,则结果将根据滤波器的大小进行下采样。如果我们不希望这种情况发生,该怎么办?可以使用填充。
填充
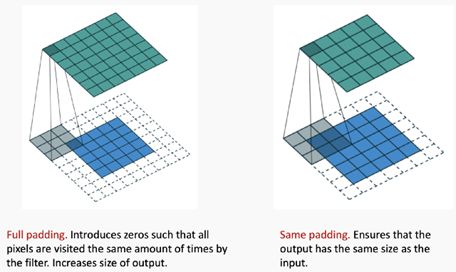
这幅图展现了如何将完全填充和相同的填充应用于CNN
填充本质上使得滤波器内核产生的特征映射与原始映像的大小相同。这对于深度CNN非常有用,因为我们不希望减少输出,为此我们只在网络末端留下一个2x2区域来预测结果。
我们如何将过滤器连接起来?
如果我们有许多功能图,那么这些功能如何在网络中结合起来帮助我们获得最终结果?
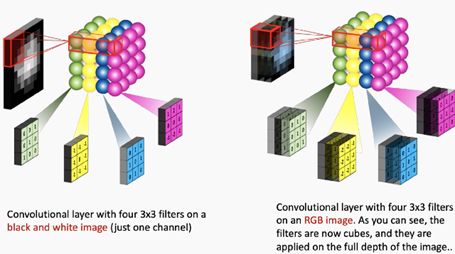
需要清楚的是,每个滤镜都与整个3D输入立方体进行卷积,但会生成2D要素贴图。
· 因为我们有多个滤镜,所以最终得到一个3D输出:每个滤镜一个2D特征贴图
· 特征贴图尺寸可以从一个卷积层大幅变化到下一个:输入一个32x32x16输入的图层,如果该图层有128个滤镜,则退出一个32x32x128输出。
· 使用滤镜对图像进行卷积会生成一个特征图,该特征图突出显示图像中给定要素的存在。
在卷积层中,我们基本上在图像上应用多个滤波器来提取不同的特征。但最重要的是,我们正在学习这些过滤器!我们缺少的一件事是:非线性。
介绍线性整流函数(ReLU)
CNN最成功的非线性是线性整流函数(ReLU),它可以解决sigmoids中出现的消失梯度问题。ReLU更容易计算并产生稀疏性(并不总是有益)。
不同层的比较
卷积神经网络中有三种类型的层:卷积层,池化层和完全连接层。这些层中的每一层都具有可以优化的不同参数,并且对输入数据执行不同的任务。
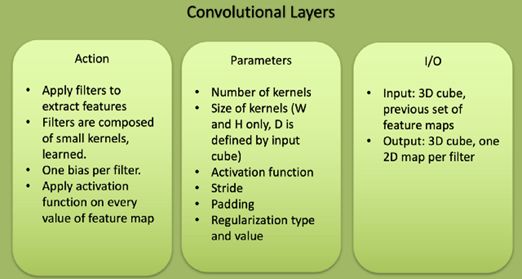
卷积层的特征
卷积层是将滤镜应用于原始图像或深CNN中的其他要素贴图的图层。这是大多数用户指定的参数在网络中的位置。最重要的参数是内核的数量和内核的大小。
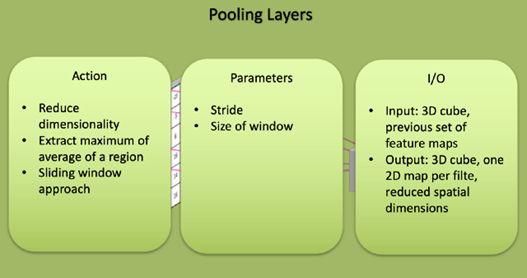
池化层的特征
池化层类似于卷积层,但它们执行特定功能,例如最大池,其取特定过滤区域中的最大值,或平均池,其取过滤区域中的平均值。这些通常用于降低网络的维度。
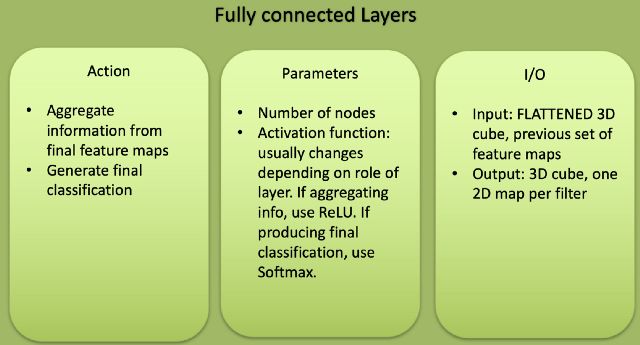
完全连接层的功能
完全连接的层放置在CNN的分类输出之前,并用于在分类之前展平结果。这类似于MLP的输出层。
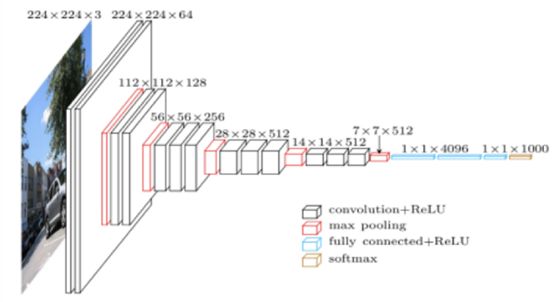
标准CNN的架构
CNN层学习什么?
· 每个CNN层都学习越来越复杂的过滤器。
· 第一层学习基本特征检测滤镜:边缘、角落等
· 中间层学习检测对象部分的过滤器。对于面孔,他们可能会学会对眼睛、鼻子等做出反应
· 最后一层具有更高的表示:它们学习识别不同形状和位置的完整对象。

CNN的示例经过训练以识别特定对象及其生成的特征映射

