通过最佳实践帮助您实现上述案例效果
Step1:安装JDK和Flume
1.1 JDK:1.7及以上版本
1.1.1 下载Linux版本的JDK1.7安装包
下载地址为:
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
1.1.2 安装JDK
# cd /usr/local/src
# rpm -ivh jdk-7u79-linux-x64.rpm #安装,默认会安装在/usr/java下
# java --version #检查是否安装成功1.1.3 配置环境变量
# vi /etc/profile在最后加入以下几行:
export JAVA_HOME=/usr/java/jdk1.7.0_71
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile #执行命令生效1.2 Flume:Flume-NG 1.x版本
1.2.1 下载Flume安装包
#cd /user/local
# wget http://apache.fayea.com/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz# 使用wget命令下载1.2.2 安装Flume
# tar -xf apache-flume-1.6.0-bin.tar.gz #解压
# mv apache-flume-1.6.0-bin flume #重命名目录1.2.3 修改环境变量
# vi /etc/profile
export FLUME_HOME=/usr/local/flume
在PATH里添加::$FLUME_HOME/bin
#source /etc/profile1.2.4 测试是否安装成功
#flume-ng versionStep2:开通MaxCompute和Datahub
2.1 开通MaxCompute
阿里云实名认证账号访问https://www.aliyun.com/product/odps ,开通MaxCompute,选择按量付费进行购买。
https://img.alicdn.com/tps/TB1TxkNOVXXXXaUaXXXXXXXXXXX-1124-472.png" width="836">
https://img.alicdn.com/tps/TB1qRw3OVXXXXX_XFXXXXXXXXXX-1243-351.png" width="836">
https://img.alicdn.com/tps/TB1gvgQOVXXXXXUXVXXXXXXXXXX-1208-337.png" width="836">
2.2 数加上创建MaxCompute project
操作步骤:
步骤1: 进入数加管理控制台,前面开通MaxCompute成功页面,点击管理控制台,或者导航产品->大数据(数加)->MaxCompute 点击管理控制台。
https://img.alicdn.com/tps/TB1G7o4OVXXXXXEXFXXXXXXXXXX-1281-473.png" width="836">
步骤2: 创建项目。付费模式选择I/O后付费,输入项目名称:
https://img.alicdn.com/tps/TB1SY78OVXXXXcqXpXXXXXXXXXX-1347-590.png" width="836">
步骤3: 创建MaxCompute表。进入大数据开发套件的数据开发页面:
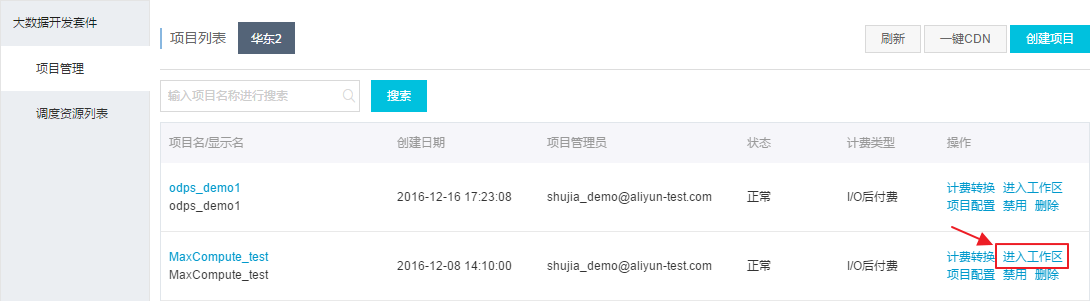
以开发者身份进入阿里云数加平台>大数据开发套件>管理控制台,点击对应项目操作栏中的进入工作区
创建脚本文件。点击顶部菜单栏中的数据开发,点击“新建”处新建脚本,也可直接点击“新建脚本”任务框
编辑建表语句
create table if not exists test(
id string,
url string,
urlname string,
title string,
chset string,
scr string,
col string,
ip string,
country string,
province string,
city string,
county string)
partitioned by (clientDate string)
INTO 1 SHARDS
HUBLIFECYCLE 1;Step3:下载并部署Datahub Sink插件
3.1 开通Datahub
进入Datahub WebConsole,创建project(注意:首次使用的用户需要申请开通)

3.2 下载插件压缩包
#wget https://github.com/aliyun/aliyun-odps-flume-plugin/releases/download/1.1.0/flume-datahub-sink-1.1.0.tar.gz3.3 解压插件压缩包
# tar -zxvf flume-datahub-sink-1.1.0.tar.gz
# ls flume-datahub-sink
lib libext{code}3.4 部署Datahub Sink插件
将解压后的插件文件夹flume-datahub-sink移动到Apache Flume安装目录下
# mkdir {YOUR_FLUME_DIRECTORY}/plugins.d
# mv flume-datahub-sink {YOUR_FLUME_DIRECTORY}/plugins.d/移动后,核验Datahub Sink插件是否已经在相应目录:
# ls { YOUR_APACHE_FLUME_DIR }/plugins.d
flume-datahub-sinkStep4:创建需要上传的本地文件
4.1 创建需要上传的本地文件test_basic.log
源数据:test_basic
注:每行为一条记录,字段间用逗号隔开,字段如下:
9999, #id
{nolink:http://mall.icbc.com.cn/searchproducts/pv.jhtml, }; #url
pv.jhtml # urlname
融e购 够容易, #title
utf-8, #chset
1366x768, #scr
32-bit, #col
58.210.33.238, #ip
中国,河南,南阳市, 内乡县 # country,province,city,county
2014-04-23, # clientDateStep5:创建Datahub Topic
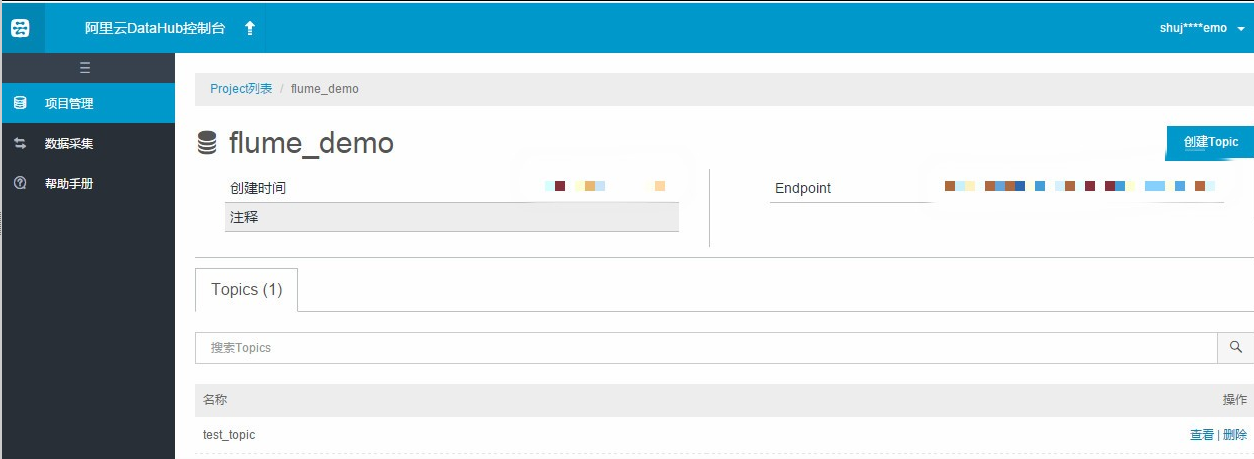
使用Datahub WebConsole,创建好Topic,schema为(string id,string url …) 下面假设建好的Topic名为flume_topic。
Step6:配置Flume作业配置文件
注:在Flume安装目录下的conf文件夹下创建datahub_basic.conf文件,并输入以下内容
#Name the components on this agent
#a1是要启动的agent的名字
a1.sources = r1 #命名agent的sources为r1
a1.sinks = k1 #命名agent的sinks为k1
a1.channels = c1 #命名agent的channels为c1
# Describe/configure the source
a1.sources.r1.type = exec #指定r1的类型为exec
a1.sources.r1.command =cat {your file directory}/test_basic.log #写入本地文件路径
# Describe the sink
a1.sinks.k1.type = com.aliyun.datahub.flume.sink.DatahubSink #指定k1的类型
a1.sinks.k1.datahub.accessID ={YOUR_ALIYUN_DATAHUB_ACCESS_ID}
a1.sinks.k1.datahub.accessKey ={YOUR_ALIYUN_DATAHUB_ACCESS_KEY}
a1.sinks.k1.datahub.endPoint = http://dh-cn-hangzhou.aliyuncs.com
a1.sinks.k1.datahub.project = flume_demo
a1.sinks.k1.datahub.topic =flume_topic
a1.sinks.k1.batchSize = 1
a1.sinks.k1.serializer = DELIMITED
a1.sinks.k1.serializer.delimiter = ,
a1.sinks.k1.serializer.fieldnames = id,url,urlname,title,chset,scr,col,ip,country,province,city,county,clientDate
a1.sinks.k1.serializer.charset = UTF-8 #文字编码格式为UTF-8
a1.sinks.k1.shard.number = 3
a1.sinks.k1.shard.maxTimeOut = 60
# Use a channel which buffers events in memory
a1.channels.c1.type = memory #指定channel的类型为memory
a1.channels.c1.capacity = 1000 #设置channel的最大存储数量为1000
a1.channels.c1.transactionCapacity = 1000 #每次最大可从source中拿到或送到sink中的event数量是1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
#将source,sink分别与channel c1绑定Step7:将数据上传至Datahub
配置完成后,启动Flume并指定agent的名称和配置文件路径,添加"-Dflume.root.logger=INFO,console"选项可以将日志实时输出到控制台。启动命令如下:
# cd {YOUR_FLUME_DIRECTORY}
#bin/flume-ng agent -n a1 -c conf -f conf/datahub_basic.conf -Dflume.root.logger=INFO,console写入成功后,在datahub即可查到数据。
Step8:数据归档至MaxCompute
操作流程:
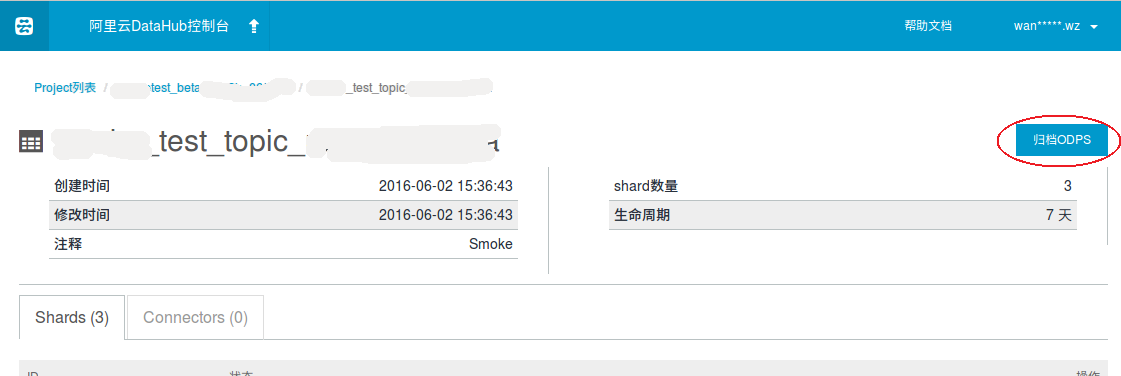
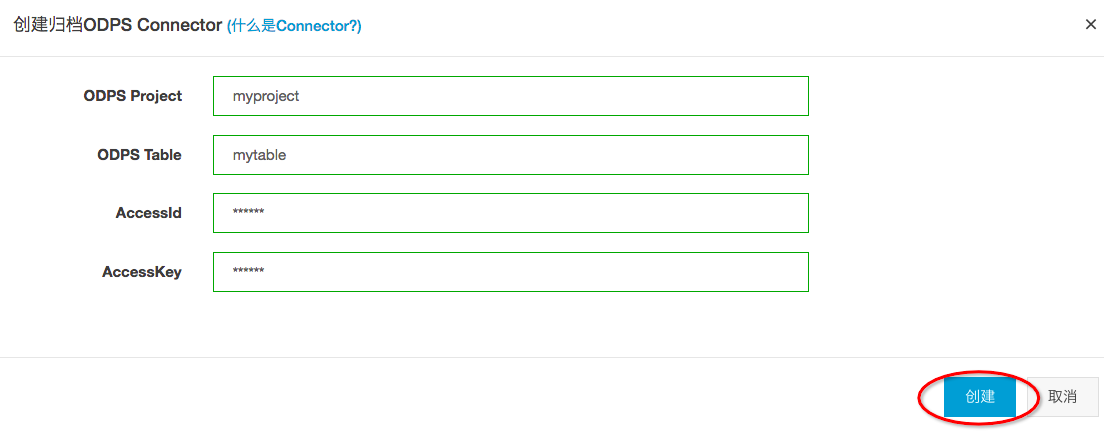
Project列表->Project查看->Topic查看->点击归档ODPS->填写配置,点击创建
8.1 进入topic详情页面
8.2 配置Connector并创建
8.3 在Connector页面查看数据归档状态

