春节假期结束了,大家在与家人亲戚欢聚的同时,不知道有没有留意春节期间的空气质量呢?没留意也没关系,下面就由DataV带大家一起回顾下春节期间的空气质量变化吧。
大屏体验地址(移动端慎点!)
提醒下大家1月27日是除夕哦,通过时序播放我们可以很明显的看到春节前后空气质量的全国分布变化,我就不在这里分析具体原因了,我这里仅仅是抛个砖。
那么如何制作这样一块时序大屏呢?接下来为大家揭秘下制作过程。
君欲善其事,必先利其器。
利器一之数据获取:
数据是可视化的原材料,正所谓巧妇难为无米之炊,我们首先要获取春节期间全国的空气质量数据。
这里推荐一个全国空气质量历史数据,感兴趣的同学可以去上面下载数据。
这里笔者下载了2017年1月1日至2017年2月2日的全国1497个监测点的数据。

我们打开china_sites_20170101.csv看下数据文件内容:

由上图可以看出这里横坐标是各个监测站点编号,纵坐标是一天24个时间段对应的各种空气质量指标,也就是说我们可以通过每个csv文件获取一天内每个小时的各个描述空气质量指标的值。
这里只有监测站点的编号,没有监测站点的信息,比如我们关心的监测站点的位置信息,不要着急,上面那个网站也为我们提供了每个监测站点的经纬度信息和站点名信息(点这里预览)。
我们下载该文件打开看一下:(注意图中有条数据没有经纬度信息,这里需要补全或者过滤掉)

这样我们已经下载好所需要的数据(稍后讲如何对数据进行处理)。
利器二之等值面组件:
相信大家在看天气预报时经常看到类似下面的图(这里截取中国气象网的一张图)。

这张图就是根据地面上若干位置的气象观测站的数据利用空间插值的方法制作出来的一张等温面图。
看下百度百科的空间插值解释:
空间插值:空间插值常用于将离散点的测量数据转换为连续的数据曲面,以便与其它空间现象的分布模式进行比较。
也就是说根据这些已知的监测站点监测出的数据去推算其他任意空间位置的数据,再根据值处在的不同区间范围去映射对应的颜色就可以得到上面这样的一张图。
一张图读懂什么是空间插值(下面的图是使用datav制作的哦):

可以很清楚的看到空间插值就是根据离散的已知点去插值出连续的面数据的这样一个过程。
DataV提供了一个轻分析的等值面地图组件来帮助大家来将已知的矢量点数据制作成栅格区域图,这里我们可以利用其来实时插值出全国的空气质量图,可以应对一些气象等行业的可视化需求。

等值面组件特性:
- 支持自定义插值精度
- 支持自定义插值权重
- 支持线性渲染和分段渲染
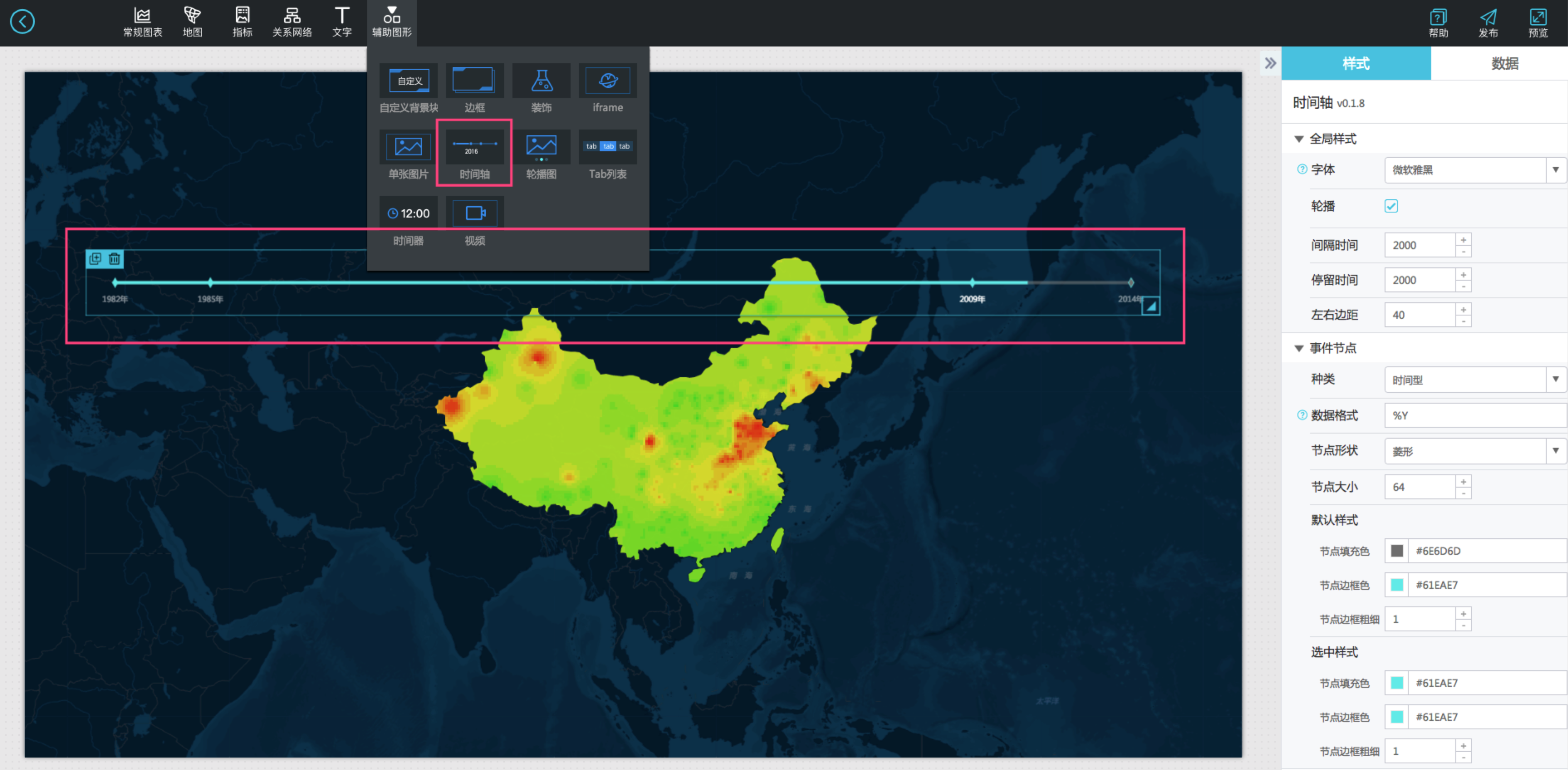
利器三之时间轴组件:
想要看到一段时间的空气质量随时序的变化,时间轴组件自然必不可少。
这种需求,细心的DataV君已经为大家想到了。

时间轴控件有个重要特性就是支持回调ID,利用好这个回调ID,我们可以跟其他组件进行联动,这样当时间轴的时间变化的同时可以触发其他组件的数据更新。
当你填写了正确的回调ID,他会在每次时间变化的时候重新触发一次数据请求,并自动在其他组件对应的API接口的参数列表加上当前回调ID及其对应的值。
例如:
初始接口地址:http://127.0.0.1:8888/aqi
回调触发后:http://127.0.0.1:8888/aqi?date=2017012722(这里回调ID填写的是date,2017012722对应的时间轴控件的时间序列当前时间段的date字段的值)
同样回调ID也可以对SQL语句生效,不过这里需要使用:加上回调ID名称作为占位。
例如:
初始SQL: select :date as value;
回调触发后:select '2017022722' as value;
磨刀不误砍柴工
磨数据
前面我们已经有了数据利器,这里我们需要打磨一下数据使其更符合我们使用。
首先分析下我们需要什么样的数据,我们看下我们的等值面组件需要的数据格式:

- 裁剪面:即研究区域的边界数据,这里是全国区域,是一个geojson的格式的数据(关于geojson是一种地理交换格式,感兴趣的可以看看geojson标准)。
- 插值点数据:这里可以看到示例数据是一个包含经度、纬度、值的一个数组,对应我们的需求就是监测站点的经纬度和监测站点对应的某个指标的值。
首先我们如果仅做一天的某个时段的这样一张等值面图,例如2017年1月20日的中午12点的关于AQI指标的等值面图,我们需要知道当天这个时段的每个监测站点的位置也就是经纬度信息和对应的AQI的值。
相信到这里大家应该知道要怎么去处理这些数据了。
写一段node脚本处理下上面下载的全国监测站点经纬度信息的csv文件。
var csv = require("fast-csv");
var fs = require('fs');
var map = {};
csv
.fromPath("./站点列表(含经纬度)-新-1497个.csv", { headers: true, objectMode: true })
.on("data", function (data) {
map[data['code']] = data;
})
.on("end", function () {
fs.writeFile('./站点列表经纬度映射.json', JSON.stringify(map));
console.log("done");
});得到监测站点编号为key,站点信息为value的字典。
截取一段看看:
{
"1001A": {
"code": "1001A",
"name": "万寿西宫",
"city": "北京",
"lng": "116.366",
"lat": "39.8673"
},
"1002A": {
"code": "1002A",
"name": "定陵",
"city": "北京",
"lng": "116.17",
"lat": "40.2865"
},
"1003A": {
"code": "1003A",
"name": "东四",
"city": "北京",
"lng": "116.434",
"lat": "39.9522"
},
...
}接下来我们再来处理下2017年1月20日的全国1497个监测点数据,也就是china_sites_20170120.csv这个文件。
再来一段脚本处理下这个csv,这个csv包含了当天24个小时每个监测站点各个空气质量指标的信息,我们将这些信息提取出来,并根据前面获取的站点列表经纬度映射表给站点加上经纬度信息。
var fs = require('fs');
var csv = require("fast-csv");
var mapdata = require('./站点列表经纬度映射.json');
var file = './站点_20170101-20170202/china_sites_20170120.csv';
var filename = file.replace(/^.*[\\\/]/, '').split('.')[0].split('_')[2];
var datas = {};
csv
.fromPath(file, { headers: true, objectMode: true })
.on("data", function (data) {
if (data.type === 'AQI') {
datas[data.hour] = [];
for (var key in data) {
if (mapdata[key]) {
datas[data.hour].push({
name: mapdata[key].name,
value: +data[key],
code: mapdata[key].code,
city: mapdata[key].city,
lng: +mapdata[key].lng,
lat: +mapdata[key].lat
})
}
}
}
})
.on("end", function () {
fs.writeFile('./data/' + filename + '.json', JSON.stringify(datas));
console.log("done");
});这里将每天的时间段作为key,每个时间段所对应的所有监测站点的AQI信息和位置等信息的数组作为对应的值。
看下格式示例:
{
"0": [{ "name": "万寿西宫", "value": 18, "code": "1001A", "city": "北京", "lng": 116.366, "lat": 39.8673 }, { "name": "定陵", "value": 25, "code": "1002A", "city": "北京", "lng": 116.17, "lat": 40.2865 }, ...],
"1": [{ "name": "万寿西宫", "value": 28, "code": "1001A", "city": "北京", "lng": 116.366, "lat": 39.8673 }, { "name": "定陵", "value": 65, "code": "1002A", "city": "北京", "lng": 116.17, "lat": 40.2865 }, ...],
"2": [{ "name": "万寿西宫", "value": 88, "code": "1001A", "city": "北京", "lng": 116.366, "lat": 39.8673 }, { "name": "定陵", "value": 95, "code": "1002A", "city": "北京", "lng": 116.17, "lat": 40.2865 }, ...]
...
}这样我们就可以方便的获取该天每个时间段的数据给等值面组件使用。
磨接口
根据前面介绍的时间轴的特性,我们如果想要时间轴变化的同时使得等值面的数据也发生变化,那么我们需要一个接口或者数据库能根据时间参数来获取不同时间段的全国各个监测站点的数据。
这里我们可以写一个简单的接口来完成这样的一个需求。
请求地址:/aqi
请求方式:GET
请求参数:
- 参数名称:
date - 参数类型:
string, 示例2017012722,时间格式为YYYYmmDDHH
这里需要提前处理好上面下载的所有数据,node提供了一个glob模块可以方便的对文件夹下数据进行批量处理。
var fs = require('fs');
var csv = require("fast-csv");
var glob = require('glob');
var mapdata = require('./站点列表经纬度映射.json');
glob("./站点_20170101-20170202/*.csv", function (err, files) {
files.forEach(function (file) {
var filename = file.replace(/^.*[\\\/]/, '').split('.')[0].split('_')[2];
var datas = {};
csv
.fromPath(file, { headers: true, objectMode: true })
.on("data", function (data) {
if (data.type === 'AQI') {
datas[data.hour] = [];
for (var key in data) {
if (mapdata[key]) {
datas[data.hour].push({
name: mapdata[key].name,
value: +data[key],
code: mapdata[key].code,
city: mapdata[key].city,
lng: +mapdata[key].lng,
lat: +mapdata[key].lat
})
}
}
}
})
.on("end", function () {
fs.writeFile('./data/' + filename + '.json', JSON.stringify(datas));
console.log("done");
});
});
});这样就批量提取出了每天的数据。

我们再利用glob模块对数据进行一次整合,将文件名也就是日期作为key,对应内容作为值。
//以下方式不适用大批量的数据
var fs = require('fs');
var csv = require("fast-csv");
var glob = require('glob');
glob("./data/*.json", function (err, files) {
var datas = {};
files.forEach(function (file) {
var filename = file.replace(/^.*[\\\/]/, '').split('.')[0];
datas[filename] = require(file);
});
fs.writeFile('./data/all.json', JSON.stringify(datas));
console.log('done');
});这样我们就得到了一个all.json这样一个整合后的文件。
下面再利用node的express框架初始化一个express项目,然后按照上面的接口需求增加一个简单的接口:

另外提醒下为了避免跨域请求的问题,需要使用cors模块,在app.js文件中增加cors模块。

这样接口已经完成,npm start一下,测试下接口访问:

万事俱备,只欠东风
我们已经成功处理好了数据,并写了对应的接口,接下来就是我们使用DataV产品来制作这样一块大屏。
- 打开DataV主面板,选择新建可视化。

- 新建一块空白大屏并取名。

- 选择地图,添加2D平面地图组件,删掉默认的子图层(保留底图层),然后添加等值面子组件,将地图组件大小拖拽至合适的大小,设置地图的中心点和缩放等级。


- 选择辅助图形,添加时间轴组件,调整至合适的位置和大小。
- 所需主要两个组件准备完毕,先来添加时间轴的数据吧,我们研究的时间区域选择2017年1月22日到2017年2月2日的每天的22点。
参照时间轴数据面板的示例数据,我们造出我们需要的数据。
[
{
"name": "2017年1月22日22时",
"date": 2017012222,
"value": 2017012222
},
{
"name": "2017年1月23日22时",
"date": 2017012322,
"value": 2017012322
},
{
"name": "2017年1月24日22时",
"date": 2017012422,
"value": 2017012422
},
{
"name": "2017年1月25日22时",
"date": 2017012522,
"value": 2017012522
},
{
"name": "2017年1月26日22时",
"date": 2017012622,
"value": 2017012622
},
{
"name": "2017年1月27日22时",
"date": 2017012722,
"value": 2017012722
},
{
"name": "2017年1月28日22时",
"date": 2017012822,
"value": 2017012822
},
{
"name": "2017年1月29日22时",
"date": 2017012922,
"value": 2017012922
},
{
"name": "2017年1月30日22时",
"date": 2017013022,
"value": 2017013022
},
{
"name": "2017年1月31日22时",
"date": 2017013122,
"value": 2017013122
},
{
"name": "2017年2月1日22时",
"date": 2017020122,
"value": 2017020122
},
{
"name": "2017年2月2日22时",
"date": 2017020222,
"value": 2017020222
}
]其中name事件或者时间节点名称也就是时间轴的轴点显示的内容,value是对应的时间,date是作为上面介绍的回调ID选项使用。
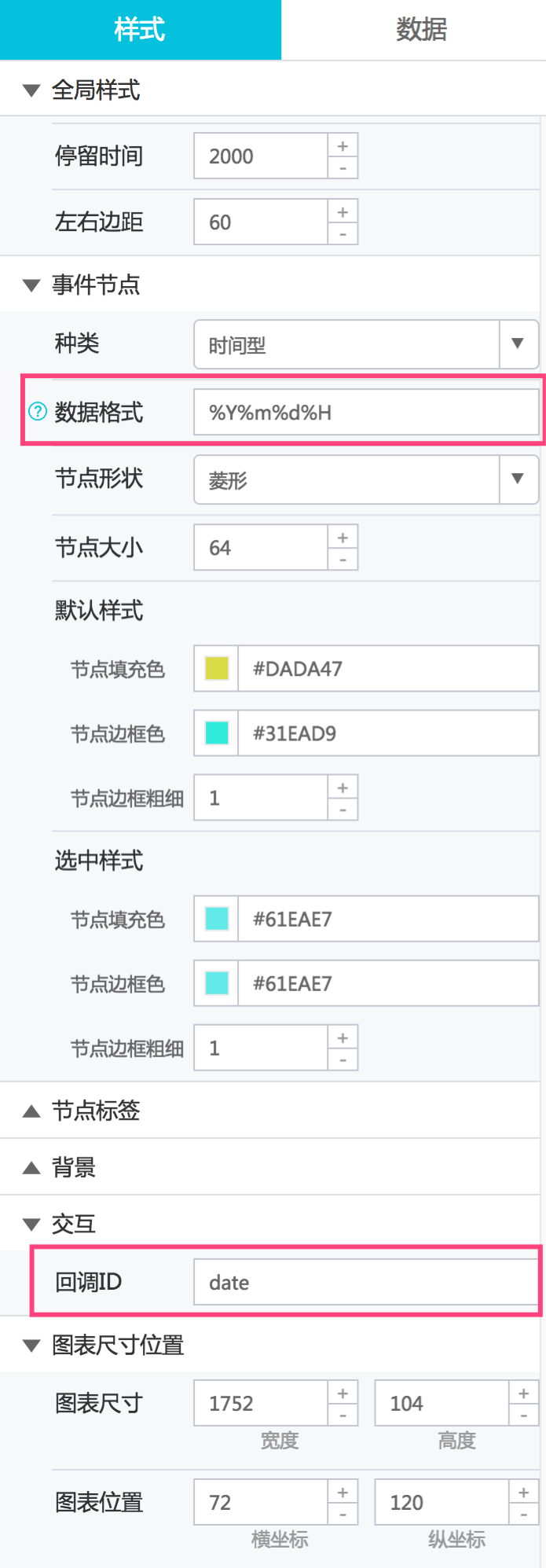
将上面数据替换时间轴数据面板的静态数据,再参照下图配置(主要是回调ID和数据格式选项的填写),我们再来看看此时的时间轴长什么样。
这里的数据格式按照上面的数据填写%Y%m%d%H,回调ID填写date。

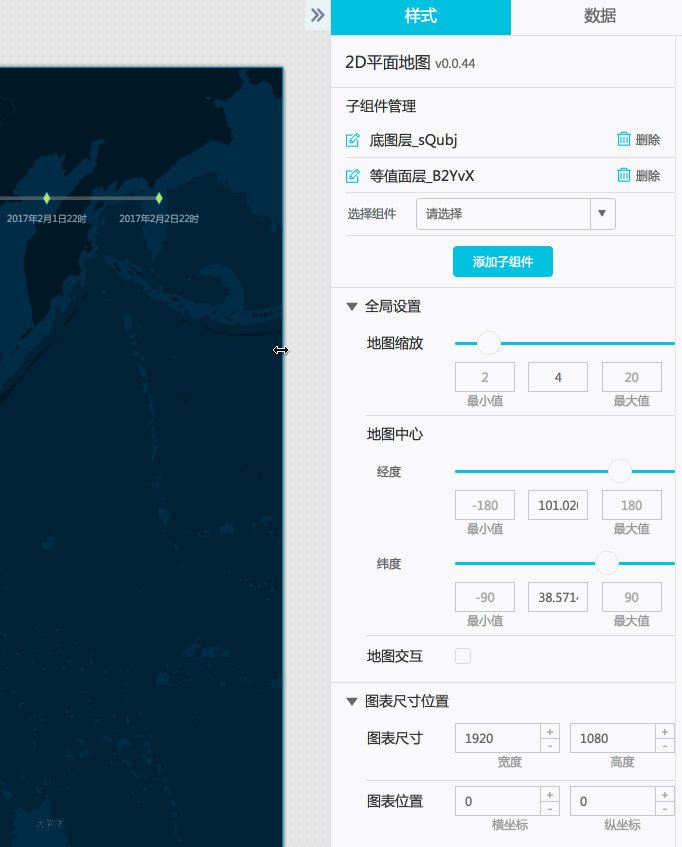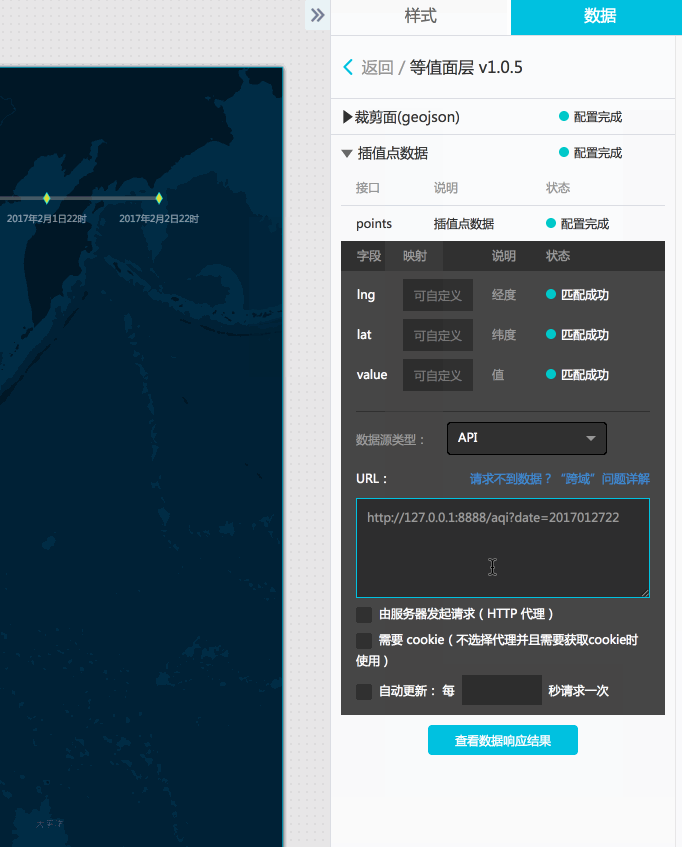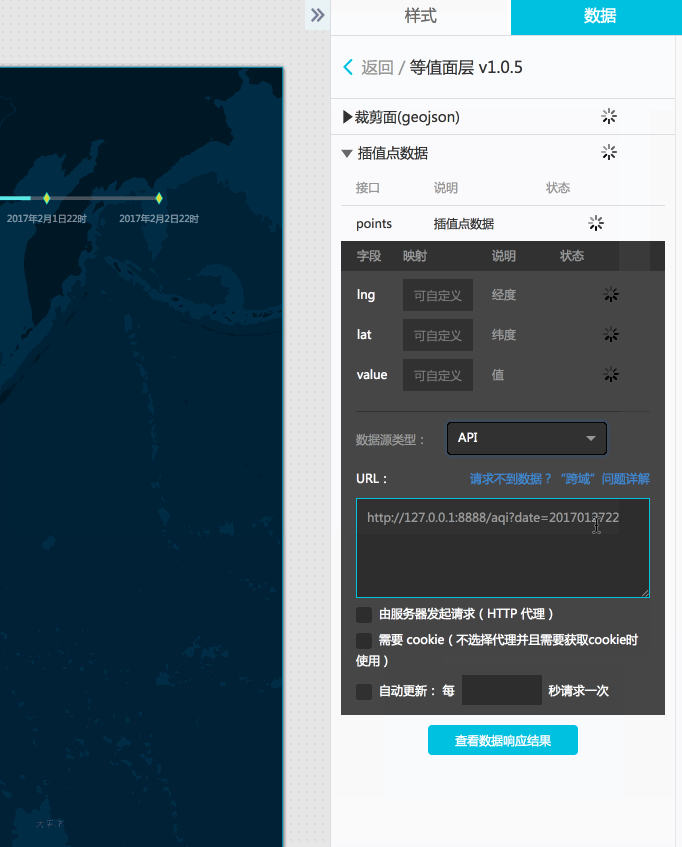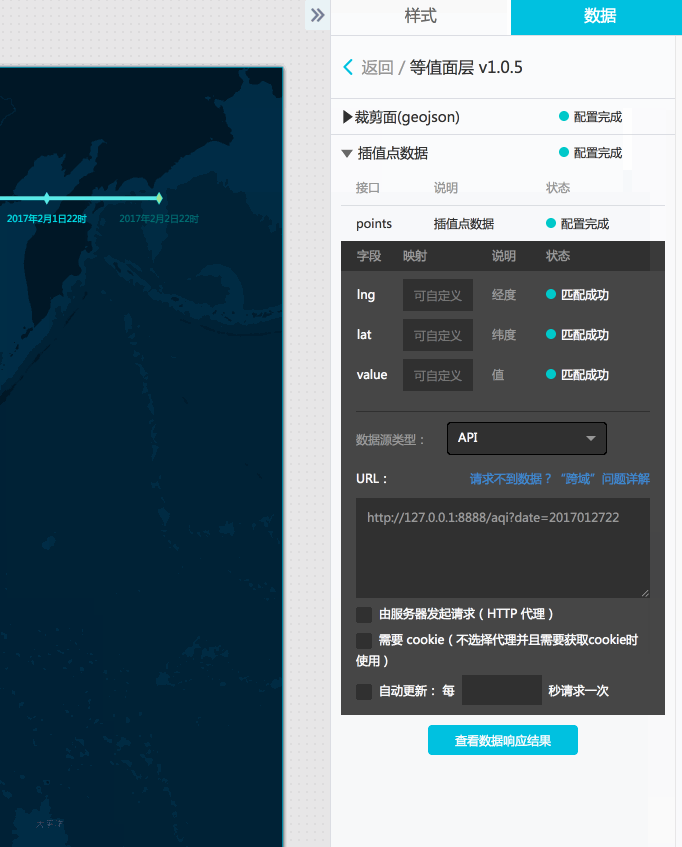
- 再来配置下我们的等值面组件,由于示例的数据区域也是全国范围,这里的裁剪面的数据可以不动,有需要的同学可以根据自己需要修改这里的裁剪面数据。
我们主要看下这个矢量插值点的数据配置:
由于前面已经写好了对应的api,也已经测试了一下数据获取,我们修改等值面组件的插值点的数据源类型成API,然后填写前面接口测试的那个地址(这里测试http://127.0.0.1:8888/aqi?date=2017012722)。

点击查看数据响应结果,可以看到已经得到了正确的响应结果并匹配成功。
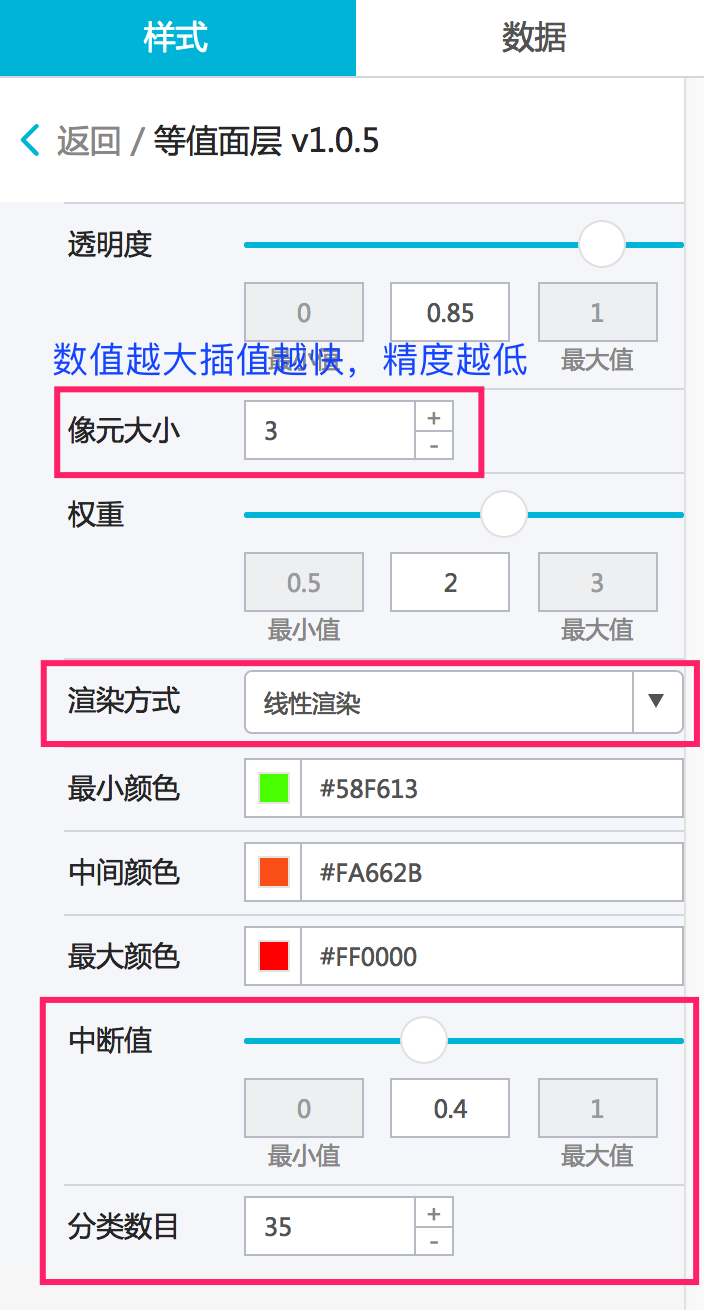
- 等值面数据配置成功我们再来修改下等值面的样式,由于需要轮播全国范围的数据,为了保证计算效率,我们需要适当将精度调低,也就是像元大小调大一些,这样可以保证快速得到插值结果。
如图调整像元大小为3,分类数目为35类,颜色保持默认色使用线性渲染方式。

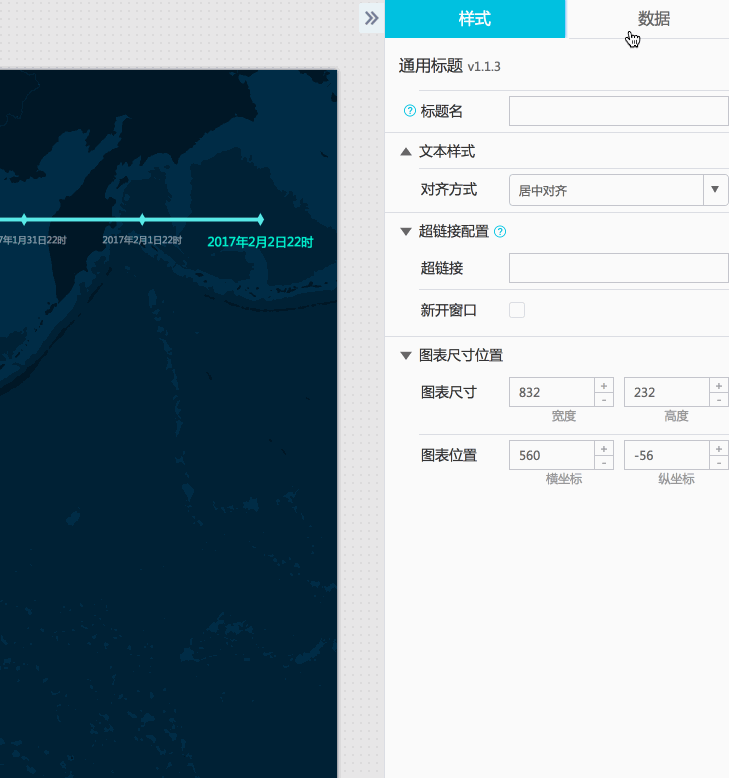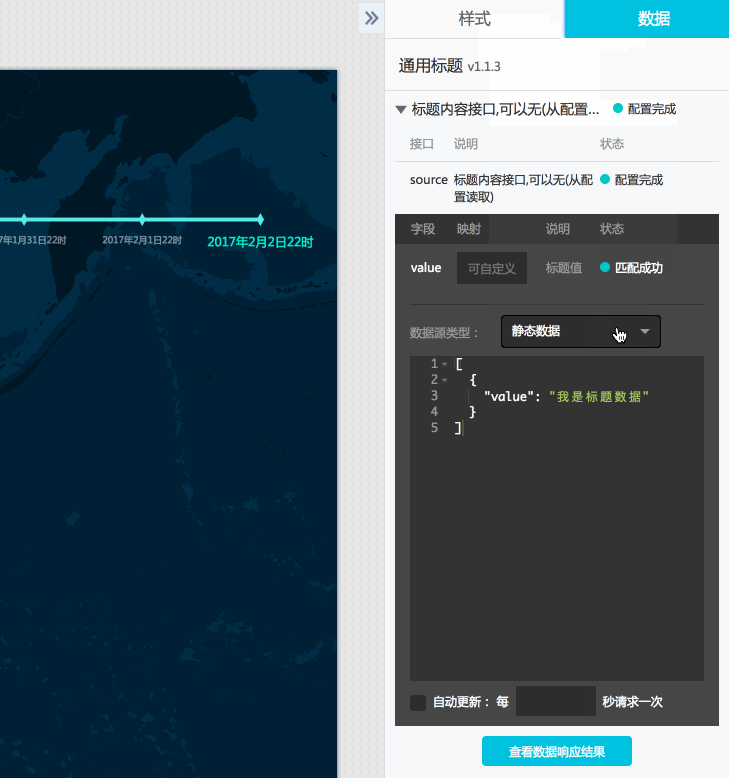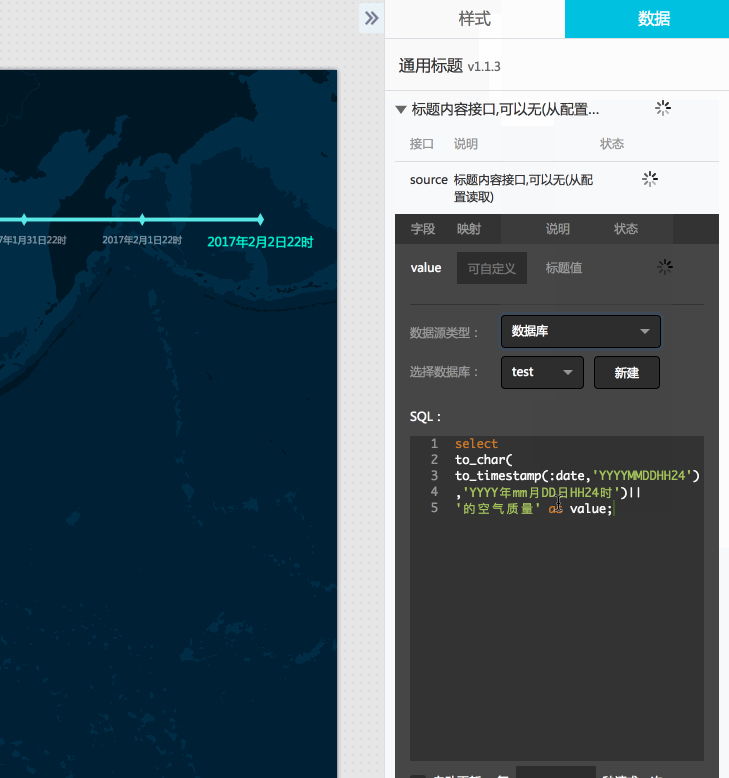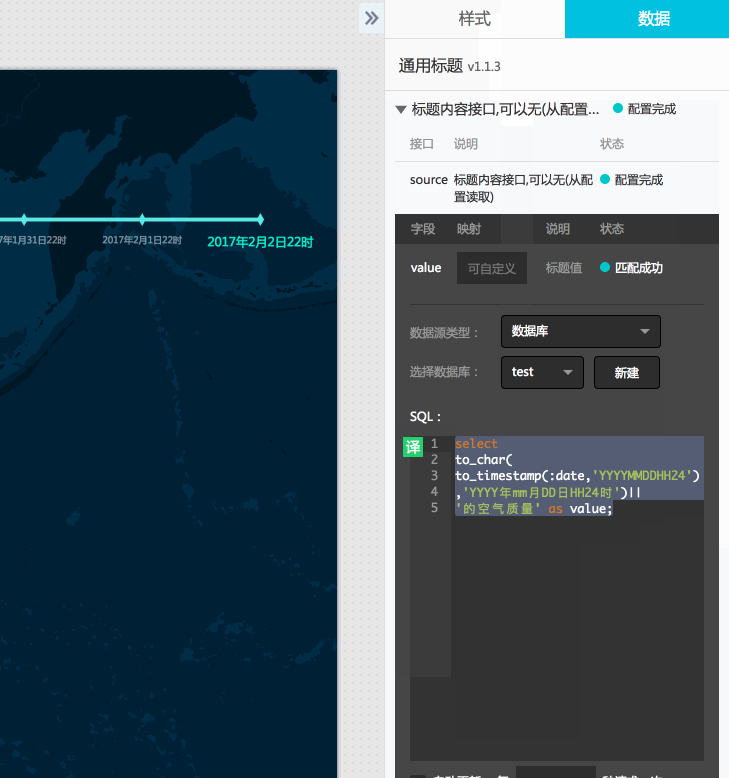
- 其实到这里已经可以预览出播放效果了,我们再增加一个标题组件吧,顺便介绍下SQL语句中回调参数的用法。
这里连接一个postgresql数据库,然后我们修改数据源类型为数据库,选择配置好的数据库,如果没有可以点击新建按钮新建一个数据库连接,这里就不再赘述。
相关sql语句(:date在实际浏览时会传入回调ID对应的值):
select to_char(to_timestamp(:date,'YYYYMMDDHH24'),'YYYY年mm月DD日HH24时')||'空气质量' as value;
- 最后再添加一下图例,我们就大功告成了。
我们再预览一下看看效果:

结语
这里简单利用DataV的两个组件——时间轴和等值面组件制作了这样一个春节期间的空气质量回顾大屏。
DataV还提供其他很多丰富的组件去帮助大家制作属于自己的数据大屏。
带上你的数据,借助DataV丰富的可视化组件,一起为数据赋能。