一文快速了解MaxCompute
很多刚初次接触MaxCompute的用户,面对繁多的产品文档内容以及社区文章,往往很难快速、全面了解MaxCompute产品全貌。同时,很多拥有大数据开发经验的开发者,也希望能够结合自身的背景知识,将MaxCompute产品能力与开源项目、商业软件之间建立某种关联和映射,以快速寻找或判断MaxCompute是否满足自身的需要,并结合相关经验更轻松地学习和使用产品。
本文将站在一个更宏观的视角来分主题地介绍MaxCompute产品,以期读者能够通过本文快速获取对MaxCompute产品的认识。
概念篇
产品名称:大数据计算服务(英文名:MaxCompute)
产品说明:MaxCompute(原ODPS)是一项大数据计算服务,它能提供快速、完全托管的PB级数据仓库解决方案,使您可以经济并高效的分析处理海量数据。
产品说明的前半部分,将MaxCompute定义为大数据计算服务,可以理解为它的功能定位于支持大数据计算,同时是一款基于云的服务化的产品。后半部分,说明了它的适用场景:大规模数据仓库、海量数据处理、分析。
单从这里还不能了解到大数据计算服务提供了哪些的计算能力,具备怎样的服务化?产品定义中出现了数据仓库字眼,我们能够了解到MaxCompute能够处理较大规模(这里提到了PB级别)结构化数据。而“海量数据处理”除了数据规模大之外,对于非结构化数据的处理有待验证,同时”分析”是否在常见的SQL分析能力之外,提供了其他复杂分析的能力。
带着这样的问题,我们继续开始介绍,希望在后面的内容中能够清晰地回答这些问题。
架构篇
在介绍功能前,先提纲挈领从产品整体逻辑结构开始,让读者有个全貌了解。
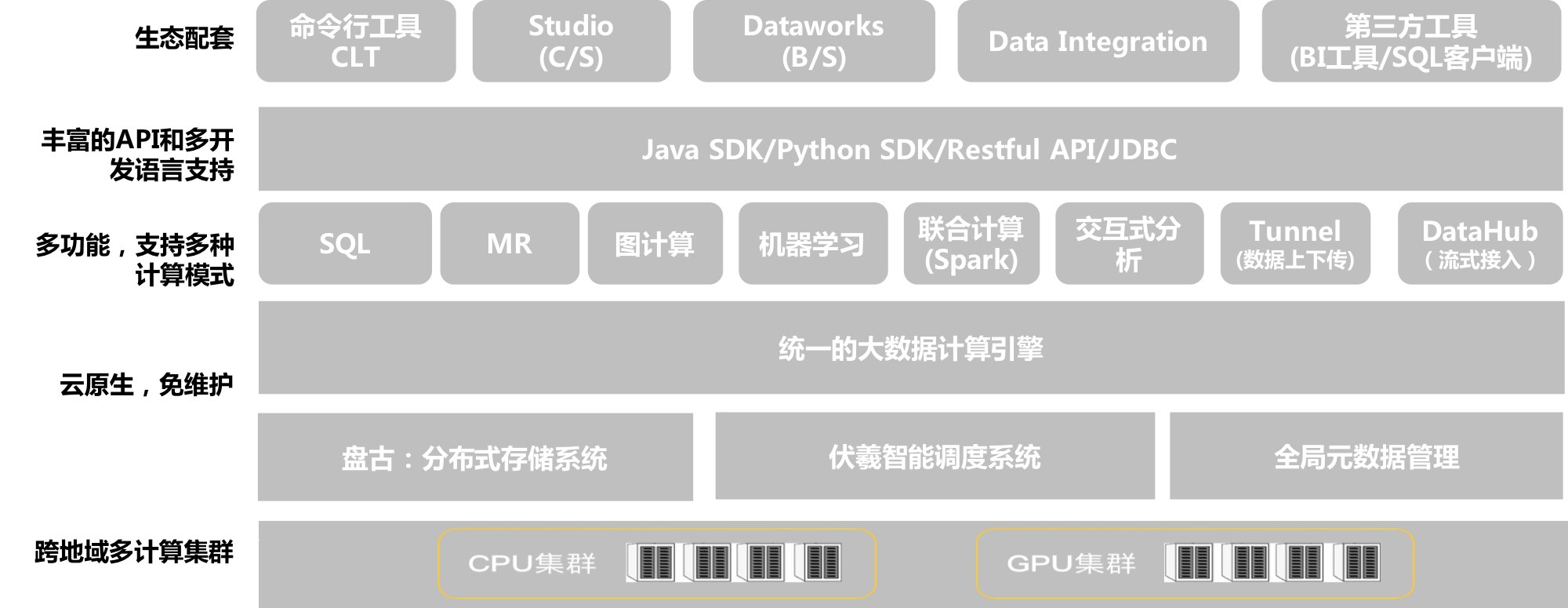
MaxCompute提供了云原生、多租户的服务架构,在底层大规模计算、存储资源之上预先构建好了MaxCompute计算服务、服务接口,提供了配套的安全管控手段和开发工具管理工具,产品开箱即用。
用户可以在阿里云控制台,在几分钟内完成服务开通并创建MaxCompute项目,无需进行底层资源开通、软件部署、基础设施运维,系统自动进行(由阿里云专业团队)版本升级、问题修复。
功能篇
数据存储
- 支持大规模计算存储,适用于TB以上规模的存储及计算需求,最大可达EB级别。同一个MaxCompute项目支持企业从创业团队发展到独角兽的数据规模需求;
- 数据分布式存储,多副本冗余,数据存储对外仅开放表的操作接口,不提供文件系统访问接口
- 自研数据存储结构,表数据列式存储,默认高度压缩,后续将提供兼容ORC的Ali-ORC存储格式
- 支持外表,将存储在OSS对象存储、OTS表格存储的数据映射为二维表
- 支持Partition、Bucket的分区、分桶存储
- 更底层不是HDFS,是阿里自研的盘古文件系统,但可借助HDFS理解对应的表之下文件的体系结构、任务并发机制
- 使用时,存储与计算解耦,不需要仅仅为了存储扩大不必要的计算资源
多种计算模型
需要说明的是,传统数据仓库场景下,实践中有大部分的数据分析需求可以通过SQL+UDF来完成。但随着企业对数据价值的重视以及更多不同的角色开始使用数据时,企业也会要求有更丰富的计算功能来满足不同场景、不同用户的需求。
MaxCompute不仅仅提供SQL数据分析语言,它在统一的数据存储和权限体系之上,支持了多种计算类型。
MaxCompute SQL:
TPC-DS 100% 支持,同时语法高度兼容Hive,有Hive背景开发者直接上手,特别在大数据规模下性能强大。
- 完全自主开发的compiler,语言功能开发更灵活,迭代快,语法语义检查更加灵活高效
- 基于代价的优化器,更智能,更强大,更适合复杂的查询
- 基于LLVM的代码生成,让执行过程更高效
- 支持复杂数据类型(array,map,struct)
- 支持Java、Python语言的UDF/UDAF/UDTF
- 语法:Values、CTE、SEMIJOIN、FROM倒装、Subquery Operations、Set Operations(UNION /INTERSECT /MINUS)、SELECT TRANSFORM 、User Defined Type、GROUPING SET(CUBE/rollup/GROUPING SET)、脚本运行模式、参数化视图
- 支持外表(外部数据源+StorageHandler 支持非结构化数据)
MapReduce:
- 支持MapReduce编程接口(提供优化增强的MaxCompute MapReduce,也提供高度兼容Hadoop的MapReduce版本)
- 不暴露文件系统,输入输出都是表
- 通过MaxCompute客户端工具、Dataworks提交作业
MaxCompute Graph图模型:
- MaxCompute Graph是一套面向迭代的图计算处理框架。图计算作业使用图进行建模,图由点(Vertex)和边(Edge)组成,点和边包含权值(Value)。
- 通过迭代对图进行编辑、演化,最终求解出结果
- 典型应用有:PageRank,单源最短距离算法,K-均值聚类算法等
- 使用MaxCompute Graph提供的接口Java SDK编写图计算程序并通过MaxCompute客户端工具通过jar命令提交任务
PyODPS:
用熟悉的Python利用MaxCompute大规模计算能力处理MaxCompute数据。
PyODPS是MaxCompute 的 Python SDK,同时也提供 DataFrame 框架,提供类似 pandas 的语法,能利用 MaxCompute 强大的处理能力来处理超大规模数据。
- PyODPS 提供了对 ODPS 对象比如 表 、资源 、函数 等的访问。
- 支持通过 run_sql/execute_sql 的方式来提交 SQL。
- 支持通过 open_writer 和 open_reader 或者原生 tunnel API 的方式来上传下载数据
- PyODPS 提供了 DataFrame API,它提供了类似 pandas 的接口,能充分利用 MaxCompute 的计算能力进行DataFrame的计算。
- PyODPS DataFrame 提供了很多 pandas-like 的接口,但扩展了它的语法,比如增加了 MapReduce API 来扩展以适应大数据环境。
- 利用map 、apply 、map_reduce 等方便在客户端写函数、调用函数的方法,用户可在这些函数里调用三方库,如pandas、scipy、scikit-learn、nltk
Spark:
MaxCompute提供了Spark on MaxCompute的解决方案,使MaxCompute提供的兼容开源的Spark计算服务,让它在统一的计算资源和数据集权限体系之上,提供Spark计算框架,支持用户以熟悉的开发使用方式提交运行Spark作业。
- 支持原生多版本Spark作业:Spark1.x/Spark2.x作业都可运行;
- 开源系统的使用体验:Spark-submit提交方式(暂不支持spark-shell/spark-sql的交互式),提供原生的Spark WebUI供用户查看;
- 通过访问OSS、OTS、database等外部数据源,实现更复杂的ETL处理,支持对OSS非结构化进行处理;
- 使用Spark面向MaxCompute内外部数据开展机器学习,扩展应用场景;
交互式分析(Lightning)
MaxCompute产品的交互式查询服务,特性如下:
- 兼容PostgreSQL:兼容PostgreSQL协议的JDBC/ODBC接口,所有支持PostgreSQL数据库的工具或应用使用默认驱动都可以轻松地连接到MaxCompute项目。支持主流BI及SQL客户端工具的连接访问,如Tableau、帆软BI、Navicat、SQL Workbench/J等。
- 显著提升的查询性能:提升了一定数据规模下的查询性能,查询结果秒级可见,支持BI分析、Ad-hoc、在线服务等场景;
机器学习:
- MaxCompute内建支持的上百种机器学习算法,目前MaxCompute的机器学习能力由PAI产品进行统一提供服务,同时PAI提供了深度学习框架、Notebook开发环境、GPU计算资源、模型在线部署的弹性预测服务。PAI产品与MaxCompute在项目和数据方面无缝集成。
对比篇
为便于读者,特别是有开源社区经验的读者快速建立对MaxCompute主要功能的了解,这里做简单地映射说明。
| 项目 |
MaxCompute产品 |
对开源社区的一些比较说明 |
| SQL |
MaxCompute SQL |
阿里自研SQL引擎,语法兼容Hive,功能和性能更优 |
| MapReduce |
MaxCompute MR |
阿里自研,类似并支持Hadoop MapReduce,MaxCompute Open MR做了优化和提升 |
| 交互式 |
MaxCompute Lightning |
Serverless的交互式查询服务,功能类似开源生态的Presto、Hawk等 |
| Spark |
Spark on MaxCompute |
支持原生Spark运行在MaxCompute上,类似Spark on Yarn形态 |
| 机器学习 |
PAI |
不同于开源社区的算法库,PAI有更丰富的算法,超大规模处理能力,更是覆盖了ML/DL全流程需求的平台服务。 |
| 存储 |
Pangu |
阿里自研分布式存储服务,类似HDFS。MaxCompute对外目前只暴露表接口,不能直接访问文件系统。 |
| 资源调度 |
Fuxi |
阿里自研的资源调度系统,类似Yarn。 |
| 数据上传下载 |
Tunnel |
不暴露文件系统,通过Tunnel进行批量数据上传下载。 |
| 流式接入 |
Datahub |
MaxCompute配套的流式数据接入服务,粗略地类似kafka,能够通过简单配置归档topic数据到MaxCompute表 |
| 用户接口 |
CLT/SDK |
统一的命令行工具和JAVA/PYTHON SDK |
| 开发&诊断 |
Dataworks/Studio/Logview |
配套的数据同步、作业开发、工作流编排调度、作业运维及诊断工具。开源社区常见的Sqoop、Kettle、Ozzie等实现数据同步和调度。 |
| 整体 |
不是孤立的功能,完整的企业服务 |
不需要多组件集成、调优、定制,开箱即用。 |
问题篇
dataworks和MaxCompute之间的关系与区别?
这是2个产品,MaxCompute做数据存储和数据分析处理,Dataworks是集成了数据集成、数据开发调试、作业编排及运维、元数据管理、数据质量管理、数据API服务等等功能的大数据开发IDE套件。类似Spark和HUE的关系,不知道这个对比是否准确。
想测试、体验MaxCompute,成本费用高吗?
不高,应该说很低。MaxCompute提供了按作业付费的模式,其中单个作业的费用有和作业处理的数据大小密切相关。开通按量付费服务,并创建1项目。利用MaxCompute客户端工具(ODPSCMD)或者在dataworks里,创建表并上传测试数据,就可以开始测试体验了。数据不大的话,10元钱可以用很长一段时间。
当然,MaxCompute还有独占资源的模式,出于费用可控的考虑,也选择了预付费的模式。
另外,MaxCompute马上推出”开发者版”,每个月为开发者赠送一定的免费额度用于开发、学习。
MaxCompute存储目前只暴露表,能处理非结构化数据吗?
可以,非结构化数据可以存放在OSS上,一种方式是通过外表方式,通过自定义Extractor来实现非结构化处理为结构化数据的逻辑。另外,也可以用Spark on MaxCompute对OSS进行访问,通过Spark程序对OSS目录下的文件进行抽取转换,结果写入MaxCompute表。
支持哪些数据源接入到MaxCompute
通过Dataworks数据集成服务或者自己使用DataX,可以实现阿里云上的各种离线数据源如数据库、HDFS、FTP等数据源的接入;
也可以用MaxCompute Tunnel工具/SDK,通过命令或SDK批量进行数据上传、下载;
流式数据,可以利用MaxCompute提供的Flume/logstash插件,将流式数据写入Datahub,然后归档到MaxCompute表;
支持阿里云SLS、DTS服务数据写入MaxCompute表;
总结
本文简要介绍了MaxCompute这个产品基本概念和功能,并和大家熟悉的开源社区服务进行了对比映射,希望对大家快速了解阿里云大数据计算服务。
更多的内容见MaxCompute产品官方地址:https://www.aliyun.com/product/odps
想了解更多阿里巴巴大数据计算服务MaxCompute,可以加入社群一起交流。