案例与解决方案汇总页:
阿里云实时计算产品案例&解决方案汇总
本文全面总结了大数据项目组在亲听项目以及全链路debug项目上进行的实时流处理需求梳理,架构选型,以及达成效果
一、背景介绍
1.1亲听项目
亲听项目专注于帮助用户收集、展示、监控和处理用户体验问题,是保证产品的主观评价质量的利器,关于其具体功能可参考在ata搜索"亲听"查看系列文章。目前亲听项目的实时流处理需求来自算法效果监控,算法效果监控需要对上游TimeTunnel日志进行解析后经过处理得到一些关键指标,亲听通过对这些指标的前端展示和阈值监控报警达到算法效果监控目的。
需求要点可以总结如下:
- 上游需要处理的TimeTunnel日志的实时数据量大约在日常峰值每秒数万条记录,大促峰值每秒几十万条记录
- 从用户搜索行为到亲听系统得到搜索行为指标数据秒级的低延时
- 数据的处理逻辑较为复杂且会随着算法迭代需要发生变化
1.2全链路debug
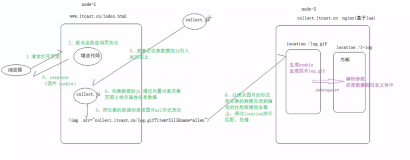
全链路debug专注于帮助用户在线上搜索结果出现异常和问题时帮助开发者复现搜索后端各子系统的中间结果,定位并解决子系统存在的问题,是系统层级质量保证和测试的有力工具。关于其具体功能可参考在ata搜索"全链路debug"查看系列文章。全链路debug的实时流处理需求是实时从TimeTunnel日志中提取出帮助排除搜索线上问题的关键内容,全链路debug利用这些内容帮助进行问题排查。全链路debug的实时流处理需求模型可以用下图描述:
需求要点可以总结如下:
- 上游需要处理的TimeTunnel日志的实时数据量大约在日常峰值每秒数万条记录,大促峰值每秒几十万条记录
- 需要保存的单条记录较大,平均达到几K左右
- 对上游TimeTunnel日志解析逻辑大部分为字段提取和透传且不会频繁变化
二、解决方案
2.1整体架构
应对以上需求,亲听以及全拉链路debug的实时流处理系统的最终架构如下:
亲听:
全链路debug:
对于亲听和全链路debug的实时流处理需求最终选择上述架构主要出于实时性和扩展性两方面考虑
2.2实时性
亲听和全链路debug的实时流处理需求在实时性要求上是类似的,即要对接tt日志,在tt日志记录写入到对于亲听和全链路debug的使用方可见延时要控制在秒级,这种实时性的需求可以分解为两个部分,第一是对实时流数据的处理,而是对实时流数据处理结果的存储和查询服务。对于实时流数据的处理,目前公司内的中间件产品blink能很好满足我们的需求,blink提供对接TimeTunnel的api接口,同时具备很好的实时流处理性能和运维体验;对于实时流处理结果的存储和查询,需要支持几万到几十万qps的写压力以及在每天累计几十T数据量情况下毫秒级延时的读性能,hbase能够基本满足对读写的需求,但是druid和drill能够在满足读写性能的同时提供更好的数据查询体验和实时流处理逻辑的可扩展性,所以对于实时流数据处理结果的存储和查询服务我们是优先考虑druid和drill的,但是全链路debug的实时流处理结果有一个特点就是单条记录数据大小平均为几K左右,这么大的单条记录的大小将导致druid需要的内存量过大且查询性能低下而不可用,所以对于全链路debug的实时流处理结果的存储和查询服务选择了hbase。
2.3扩展性
在亲听实时流处理系统的下游引入tt->druid,然后使用drill查询druid提供查询服务,是出于对扩展性的考虑。druid是一种支持实时流处理和查询的olap系统(ATA),对接druid使得可以把一部分实时流数据的处理逻辑交给druid,这样当实时流处理逻辑需要修改时,很多情况下就可以通过修改查询逻辑(只要修改一个请求druid时的json配置文件)而不需要修改blink任务(需要修改代码、打包、编译、调参、上线)实现,大幅提升实时流处理系统的扩展性,而亲听实时流处理需求频繁变化的业务特点非常需要这种扩展性;drill是高性能的SQL查询引擎,通过drill对接druid提供查询服务不但使查询语法从druid的json文件变为sql可读性大幅增强,同时drill对druid查询结果具有的二次处理能力也进一步增强了通过修改查询逻辑可以满足的实时流处理逻辑变化,进一步增强系统可扩展性。
在blink和druid之间增加了TimeTunnel进行数据中转以保证blink产出流数据被转化为下游druid支持的流数据源形式。
2.4经验总结
使用table api编写
stream api作为blink的底层api,具有较高的灵活性,但是可读性很不好,进而非常影响代码的可维护性和扩展性,当要在实时任务中加入新需求时经常要改动很多地方并且很容易出错,所有实时任务我们选择使用table api编写,table api使用类sql语法描述实时流处理逻辑,使得数据流处理逻辑变得非常清晰,可读性大幅增强,进而节约代码的维护和扩展成本。
进行字段归类合并
我们通过梳理业务方最终需要使用的字段内容,将blink任务输出到TimeTunnel中记录的字段进行了分类合并,除了出于druid查询性能考虑将若干需要进行group by以及count distinct查询的原有字段保留,其余全部按照诸如搜索请求相关信息、用户相关信息、搜索返回宝贝相关信息这样的概念将原有字段分组后合并为多值字段,而每个合并后的多值字段又会在blink代码中用一个udtf函数统一处理。这样做的好处在于代码逻辑上变得更清晰,当实时流处理需求发生变化,需要产出新的内容或修改现有内容产出逻辑时,只需找到新增内容或待修改内容对应的多值字段,修改对应udtf逻辑并重新上线blink任务即可,下游的druid build无需进行任何修改;同时用有限的几个udtf对整个实时流输出记录的处理逻辑进行归类,避免了记录处理逻辑频繁变化可能导致的代码中过时字段和udf泛滥,可读性下降,修改易出错的问题。
drill处理逻辑前移
请看下面这个sql:
select * from druid.sqa_wireless_search_pv where INSTR(auction_tag, '15')这个sql drill的处理逻辑是从druid表中召回druid.sqa_wireless_search_pv表中全部记录后逐条进行auction_tag字段的比对,过滤出包含‘15’字符串的记录,这种召回全部记录进行处理的操作对于drill来说会造成很大的性能问题,占用集群资源急剧上升,查询延时大幅提高,甚至导致集群oom使查询服务中断服务。在使用drill进行查询时应尽量避免执行类似召回大量记录进行处理的sql,我们对亲听算法效果监控现有sql进行了梳理,找到召回记录数目可能会过高的sql,通过将处理逻辑前移到blink任务阶段大幅优化drill查询性能(例如上面的sql只要将比对auction_tag字段是否含有‘15’的逻辑交给blink处理,并让blink任务新增产出一个tag字段,这样druid就可以针对tag字段建索引,通过where tag==‘true’这样的语句就可以直接召回需要的记录)
三、成果总结
目前tt->blink->hbase和tt->blink->tt->druid是在公司内使用非常广泛的两种实时流处理架构,能以秒级延时完成线上实时日志处理,这两种实时流处理架构比较好地满足了亲听和全链路debug项目的实时数据处理需求,极大提升了项目价值
四、作者简介
鸷鸟,来自搜索事业部-工程效率&技术质量-算法工程平台-实时大数据平台
15年加入阿里,主要从事电商体系实时数据研发以及实时大数据平台研发