一、异构计算ABC
简单的介绍几个概念,同道中人可以忽略这一段。云计算取代传统IT基础设施已经基本成为业界共识和不可阻挡的趋势。云计算离不开数据中心,数据中心离不开服务器,而服务器则离不开CPU。当然,世事无绝对,上述三个“离不开”自然是针对当下以及并不久远的未来而言。而异构计算的“异构”指的是“不同于”CPU的指令集。
异构计算听起来是一个高大上兼不明觉厉的概念,实际上,我们大致可以用“加速协处理器”的概念来替代异构计算,这样理解起来也许就容易多了。云计算在最开始指的就是基于CPU的计算,异构计算异军突起之后,云计算就分成了基于CPU的通用计算和基于CPU + FPGA、CPU + GPU的异构计算。
可能有的读者说:CPU + ASIC难道不是异构计算么?当然算,只不过,抛开ASIC的优点(高性能、大批量前提下的低成本)不说,ASIC的高开发成本(进入10nm工艺时代,流一次片可能动辄几百万乃至数千万美元)和长上市时间(从立项到上市最少也要一到两年的时间)是两个非常不利的因素。因为目前异构计算所针对的垂直行业都具有快速变化、快速迭代的特点,是ASIC完全没有办法满足的。所以到目前为止,基于ASIC的异构计算占比极少,基本可以忽略不计。
本文聚焦于讨论基于FPGA的异构计算,为了行文方便起见,下文中提到异构计算就是指FPGA异构计算。
下面的图、表对CPU、GPU、FPGA和ASIC各自的优劣势进行了简单的比较:
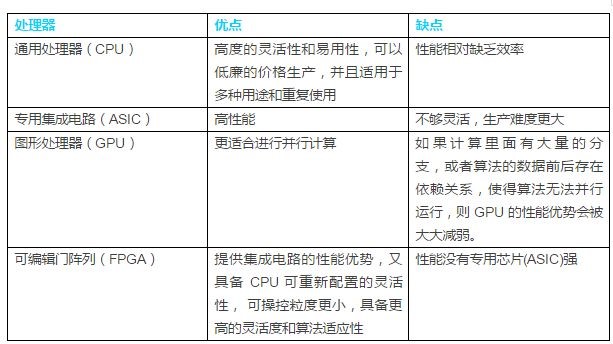
表1:CPU、ASIC、GPU、FPGA特性简单对比
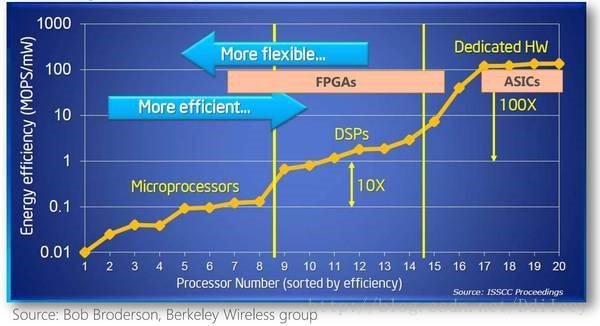
图1:CPU、ASIC、GPU、FPGA能效与灵活性对比

图2:计算密集型任务,CPU、GPU、FPGA、ASIC 的数量级比较(16 位整数乘法)
二、为什么要异构计算
异构计算为什么会异军突起?其实假如CPU一直很牛很牛,可以完全满足客户对于“计算”的海量需求,那就没有FPGA什么事儿了。当然了,CPU一直在摩尔定律的驱动下变的越来越牛,可是一来客户的需求变的比CPU的能力更牛,二来随着芯片工艺的推进,摩尔定律渐有失效的迹象,CPU越来越需要一位具备“专业”加速能力的伙伴了。
纵观CPU的演进历史,我们可以看到为了跟上摩尔定律的步伐,业界可谓是出了浑身解数。第一板斧就是通过不断的提升工作的主时钟频率来提高效率:时钟频率越高,意味着单位时间内可以执行的指令越多,从而提升了效率。但是时钟频率不可能无限提高,因为CPU本质上也是一种ASIC,也是由一个个的晶体管、一个个的逻辑门组成的,而晶体管、逻辑门都需要特定的充放电时间来完成“0”、“1”状态的转换。这个特定的充放电时间就决定了CPU工作时钟的时钟周期,也就决定了时钟频率。
提升时钟频率遇到了天花板,业界又想出了第二板斧:“多任务、多线程”,让CPU可以“同时”做两件乃至更多件事情,如同周伯通的“一心二用”,从而可以“左右互搏”,这当然是神话。CPU终究是一个“分时复用”的东东,再牛叉的CPU,同一时刻也只能跑一条指令。多任务多线程的实质不过是充分利用CPU执行某个任务时的“空闲”时间来干点别的活儿,假如某个任务长期100%霸占CPU,那么再多的任务和线程也没什么用,只能乖乖等着。
紧接着第三板斧又来了:多核。就是在一个package里面封装多个物理核,理论上多核CPU就相当于之前同等数量的单核CPU。但是这些核之间是需要通信协同的,这就导致了性能的降低,比如一颗双核CPU的效能大致等同于1.8颗单核CPU。而且由于散热、封装等因素的限制,也不可能在一个package里塞下几百上千个核,尽管Intel已经推出了96核的CPU。多核还面临Dark Silicon的问题,依靠增加核数来提升CPU性能之路已经走到尽头。关于什么是Dark Silicon,简单的说就是由于功耗的限制,多核CPU中可以同时以最高性能工作的核数是非常有限的,其他的核都处于闲置状态。如果想进一步了解可以参考如下网页:https://zhuanlan.zhihu.com/p/20833753。
除了上述三板斧,业界暂时没有再找到可以大幅提升CPU计算力的办法,而在某些特定领域,对CPU算力的需求简直是贪得无厌、无穷无尽的,比如深度学习、图像和视频转码等,这时候FPGA的“空间”计算力就可以大显身手了。
其实异构计算的兴起要感谢AI和GPU。AI离不开各种xNN,也就是神经网络,CPU算起来真是力不从心,而GPU则似乎天生适合干这个活儿(训练)。因此,随着过去两三年AI的炙手可热,GPU异构计算也风生水起,nVidia的股价居然在一年时间内暴涨三倍(当然不全是异构计算导致的显卡需求暴增,还有数字货币带动的挖矿产业)。
所以,归纳起来,异构计算之所以会兴起,就是因为在某些特定行业或者特定应用场景,采用CPU作为算力解决方案的性价比是不高的。而根据这些不同的行业或者场景来选用CPU + GPU或者CPU + FPGA做解决方案的性价比则是很高的。CPU、GPU和FPGA各自“天生”的特性决定了它们都有各自最擅长(或者说性价比最高)的应用领域,在这些领域里,CPU+GPU或者CPU+FPGA的组合而不是纯CPU组合,是最优的解决方案。从纯技术的角度来争论CPU、GPU和FPGA孰优孰劣不是一件很有意义的事情,一定要从解决方案和商业的角度来做对比才更有说服力。
三、FPGA异构计算的钱景
马老师说了,每天做着可以改变世界的事情,就会打满鸡血,充满激情。我斗胆替马老师接一句:做好了这些改变世界的事情,whole bunch of money就是自然而然的结果。我一直的观点是:技术是为商业服务的,技术只是手段,商业成功才是目的。因此见客户一定要先谈钱:使用阿里云的FPGA加速解决方案,既能帮您挣钱,又能帮您省钱,这样客户才会开开心心的掏钱。然后再谈情怀,谈诗和远方,光跟客户谈诗和远方,会被客户轰出来的。
基于上面的分析,我们来看看FPGA异构计算的钱景如何。先看下图(预测数据来自前瞻产业研究院):
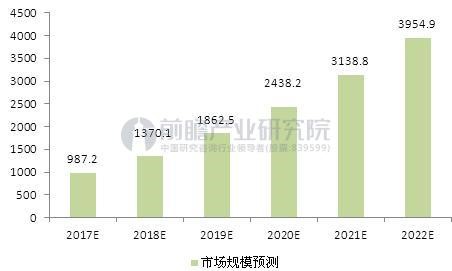
图3:2017-2022年中国数据中心市场规模预测(单位:亿元)
可以看到2020年中国数据中心市场规模可达近2500亿元人民币,约400亿美元。按照阿里云占据一半市场份额来计算,则为200亿美元。根据Intel发布的白皮书预测,到2020年,通用计算市场与异构计算市场会是一个7:3的比例,至于这三成的异构计算市场里面GPU和FPGA的占比如何,要看各自所适合的垂直行业的发展情况。我们姑且认为GPU和FPGA各占15%,那么FPGA异构计算市场规模为30亿美元,对比整个阿里云2017年全年营收133亿人民币(预计2020年超800亿,届时异构计算可能占比三成,达到240亿人民币),可见FPGA异构计算的市场钱景是相当可观的。
我个人坚定的看好FPGA异构计算的未来(学习博士当年坚持搞阿里云的精神和不达目的不罢休的劲头:not to believe because I see but to see because I believe)。随着云计算逐步变成和水电煤气一样的基础设施,整个市场容量要以万亿乃至数十万亿美元来计算。FPGA异构计算即使只占10%,那也是千亿美元的大市场。
在未来的云计算、数据中心市场,纯CPU、CPU + GPU和CPU + FPGA的解决方案将长期并存下去,中、短期看,是一个CPU + GPU / CPU + FPGA方案不断蚕食纯CPU方案的过程。在这个过程中,CPU厂商、FPGA厂商也会为了巩固自己的地盘兼抢夺别人的地盘,基于各自的优势,选择提供一揽子芯片解决方案。比如CPU厂商会推出内嵌FPGA/GPU的超级CPU;而可编程逻辑器件厂商则会在FPGA器件中嵌入CPU和GPU硬核。
对于提供FPGA as a Service(FaaS)的云服务提供商来说,FPGA异构计算能否成功的关键则在于IP生态的建设。IP解决方案齐全的云服务提供商,未来可以像搭乐高积木一样,迅速的为客户“量身定做”出性价比最高的解决方案,并通过自己的FaaS平台向客户输出,而缺乏IP生态的厂商则很难得到客户的青睐。
四、HLS与RTL—从菜刀到小李飞刀
在FPGA设计领域,HLS是High Level Synthesis(高层次综合)的缩写,RTL是Register Transfer Level(寄存器传输级)的缩写。顺便吐槽一下,从事ICT行业,就要不断的面对各种各样的缩写,很烦人,但是呢,表达效率确实很高。汉语也有类似缩写:比如喜大普奔、不明觉厉、男默女泪、火钳刘明,等等,等等。
1998年,作为新鲜出炉的大菜鸟一只,我加入了一家通信公司,职责是开发一块单板。就是画PCB、写单板软件、设计FPGA乃至到最后的焊板子等等全部自己搞定。那时候根本不知道硬件描述语言为何物,只能向当时的老鸟学习使用74系列集成电路来做FPGA设计。虽说不是一个逻辑门一个逻辑门的来搭电路,其实也差不多了。可想而知,这样做的效率能高到哪里去。但是这样做也有好处:你对整个电路了然于胸,可以清楚的知道到哪个时钟节拍哪个门该反转、哪个三八译码器该输出什么码、哪个移位寄存器的输出应该是什么。况且,那时候的FPGA和CPLD的容量都小,所以这么做效率上也没啥违和感。
等到了1999、2000年左右,XILINX开始推出Virtex系列时,这个办法就不太灵了:FPGA的电路规模已经太大,再画图设计的话,周期可能要两年乃至三年,完全抹杀了FPGA灵活可编程、上市时间短的优势。被逼无奈之下,自己开始学习Verilog HDL,摸索如何使用第三方综合工具来综合(那时候XILINX的ISE和Altera的Quartus综合和仿真功能都很弱)、使用第三方工具来做仿真。也要感谢当时同一个小团队的另一只老鸟(老鸟姓鲁,对我真是倾囊相授),给了我很多指点,非常无私的那种。我朴素的认为一花独放不是春、大家好才是真的好,于是就开始写各种教程、制定大规模FPGA的整套开发流程、写课件给同事讲课。事情越闹腾越大,引起了上层的注意,就把我跟另一个部门做FPGA的几个老鸟给抓到了一起,封闭了半年之久,整天啃各种各样的“工程类”的书籍。最终我们输出了“XX公司逻辑设计LCMM流程1.0”。LCMM就是Logic CMM,因为当时CMM很流行,各家软件公司都标榜自己是CMM3/4/5,我们就无耻的蹭了一下CMM的流量。
Verilog和VDHL都是基于RTL层级的硬件描述语言(HDL)。相对而言,Verilog灵活性高一些,而VHDL语法更严谨一些。综合工具很容易把HDL的描述映射成相应的硬件电路,所以综合工具把精力放在如何更高效上:比如综合时间尽可能短、综合效率尽量高(占用面积低、时钟运行频率高)。HDL相比画电路图,在“电路”效率上可能要低一些,因为毕竟多了一层抽象;但是在开发效率上,那可是高了不止一个数量级。而且随着综合工具的进步,“电路效率”的差异逐渐被抹平了。
HDL已经如此之“完美”,为什么又会冒出HLS呢?一方面,人类追求真善美是无止境的(这是一句鸡汤,不喜欢的就不用看了),真正重要的是:随着FPGA规模的增大,验证FPGA的功能仿真阶段在整个开发过程中的占比越来越高。2000年之前,可能设计电路和验证功能(功能仿真)时间占比可能是8比2,到后来逐渐的7比3,再到现在差不多4比6了。也就是说,超过一多半的时间花在了功能验证上了。这一多半时间中的一半又花在哪里了呢?设计和编写test bench了。test bench是个神马东东呢?讲白了就是一个数据发生器兼接收器兼鉴别器:把数据(不管是否合法)灌进FPGA、从FPGA接收反馈、然后根据预设的需求规格来判定FPGA反馈的对还是不对。
用HDL做设计,必须要考虑功能、可综合、效率、时钟树、功耗、IO、布局布线等等N多因素。可是用HDL写test bench完全没必要考虑那么多。一个显而易见的推论就是:使用更高层次的抽象语言显然可以大幅度提高test bench的建模和设计效率,从而就从整体上大幅缩短了FPGA的开发周期。在经历了System Verilog、System C、C、C++、OpenCL等诸多尝试之后,使用更高抽象层次的设计语言来设计FPGA就变成了众望所归(用中文来说就是变成了刚需),就有了今天的HLS。
那么问题来了:HDL和HLS相比,到底哪个更好?Well,回答这个问题还是需要一定的水平的,不然结局要么友谊的小船说翻就翻,要么就跳进人家给你挖的坑里了。如同前面介绍通用计算和异构计算时比较CPU、GPU和FPGA,要看面对的具体应用场景。回答这个问题也要看针对FPGA设计的哪个方面说。从电路效率角度,HDL肯定秒杀HLS;而从仿真建模效率角度,HLS肯定秒杀HDL。HLS当下最大的短板就是“电路效率”太低。简单说:同样一个功能,用HLS不但会占用面积大,而且能跑的时钟频率低。这个短板完全是HLS的高度抽象所带来的,也就是说,高度抽象既是HLS仿真建模的最大优势,又是设计综合的最大劣势。举个简单的例子(例子不一定实际可以验证,只是为了更简洁的说明问题):用HLS写了一段代码(不管是C/C++还是OpenCL),你期望综合出的电路就是一块可以做异步FIFO的RAM。但是由于HLS的高度抽象,对于(智商令人捉急的)综合工具来说,可以综合成RAM,也可以综合成组合逻辑,或许还有第三、第四种解读…也就是说,综合工具暂时没能力综合一个最高效的电路出来。
简而言之,在当下以及不那么久远的将来,使用HDL进行设计而使用HLS进行建模和验证,将是最佳的设计模式:取得了电路效率和验证效率的最佳平衡。随着EDA工具的不断进步(智商余额不断提高),将来我们可以期待HLS既可以设计代码,也可以建模验证。菜刀也就终于进化成了无坚不摧的小李飞刀。
图4:同样的功能,使用HLS和使用RTL分别来描述的对比
(图片来源:《从算法到FPGA的神器--HLS技术在蚂蚁密码加速项目中的运用》,作者:吾安)
五、FaaS的典型应用场景—姚明与C罗
在特定的应用场景,FPGA的加速能力已经毋庸置疑。我们要做的就是找准这些场景,让FPGA在这些场景中充分发挥强大的加速能力。
从目前看,FPGA在图片和视频转码、数据库加速、深度学习推理、安全、基因测序等领域都展示了无与伦比的加速能力。
1、图片转码与视频转码
移动终端的普及以及电子商务的兴起产生了海量的图片,文艺一点的说法是:一张图胜过千言万语;接地气的说法是:没图说个锤子。同时,人民对于美好生活的进一步向往催生了大量的娱乐需求,从而产生了海量的视频。海量的图片和视频给网络传输和存储都带来了巨大的压力,也带来了巨大的传输和存储成本。因此业界都在努力开发压缩率更高、压缩速度更快的编码算法,当然,只谈压缩率和压缩速度而不谈画质就是耍流氓,因此当我们比较压缩率和压缩速度的时候,一定有个前提就是同等画质条件下。
这些海量图片中的绝大多数(超过90%,拍脑袋得出的数字,不见得严谨)都是JPEG,相对于新的图片格式,比如webp、HEIF(这两个都是google主推的)、lepton,我司自研的APG格式、鹅厂自研的TPG格式等,JPEG真的已经out了。因此,从节约TCO成本的角度,将这些海量JPEG图片转换为webp/HEIF格式是非常有必要的。我们简单对比一下CPU和FPGA处理JPEG转码的原理,来秀一下FPGA干这个活的巨大优势。CPU的处理是串行的,当然,靠多核可以实现“并行”,而FPGA的处理是并行的。比如我们设定一个时间段:让CPU和FPGA各自读入100张JPEG图片,那CPU就是处理完一张再处理下一张,而FPGA是一次性处理完这100张。我们很容易得出一个结论:图片越多,FPGA的加速优势就越明显。
和图片相比,视频无非是“动态的图片”,其处理过程当然要复杂得多,可基本的原理都是差不多的。必须要说明的一点是:在视频转码领域,FPGA的竞争对手更多的是GPU而非CPU。并且FPGA的加速威力一定要建立在很好的算法和很好的FPGA设计、实现的前提下才能充分的发挥出来。如果算法本身很糟糕或者算法很优秀但是FPGA设计、实现很糟糕,那么FPGA的优势可能体现的就不是那么明显乃至没什么优势了。
阿里云FaaS舜天平台可以提供给客户的价值在于:如果你想充分利用FPGA在图片和视频转码领域的超强计算力而又不使用FaaS,那就要自己设计板卡、自己设计FPGA,然后在FPGA上跑自己的算法。其成本之高、开发周期之长,会让绝大多数中小公司打消这个念头。有了FaaS,客户所需要做的只是设计自己的算法,然后在FaaS上跑出结果来就可以了。更进一步,客户甚至都无需自己设计算法,因为FaaS的核心目标之一就是建立一个健康的生态,这里面有大量的IP Vendor,也有大量的客户,客户只要找到适合自己的算法IP或者找到能够设计这个算法IP的Vendor,然后交给FaaS舜天平台跑出结果就好了。
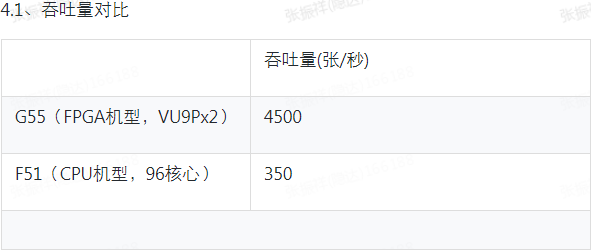
图5:FPGA与CPU对于APG图片格式的转码效率对比,原始格式为JPEG(512X512)
(图片来源:《助推双十一:APG图片编码FPGA加速项目总结》,作者:开橙)
2、数据库
数据库应用大致可以分为两类:OLTP和OLAP,也即所谓的“联机事务处理”和“联机分析处理”。OLTP主要是执行基本的、日常的事务处理,比如数据库记录的增、删、改、查。比如在银行取一笔款项,就是一个事务交易。OLAP则是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态的报表系统。因此OLAP是CPU密集型操作,而OLTP是IO密集型操作。FPGA的“并行”或者说“空间”计算优势在OLAP类操作中是大有用武之地的。必须要说明的是,不是所有数据库操作都是FPGA所擅长的。我们利用FPGA的优势就要努力找出到底哪些操作是FPGA最擅长的,然后让CPU去完成那些FPGA所不擅长的操作,古人教导我们说:“男女搭配,干活不累”,CPU和FPGA配合起来才能取得最高的性价比。
之所以要一直强调FPGA和CPU的“合理分工”,是因为我担心读者老爷们看到我一直在鼓吹FPGA如何如何牛叉,保不齐来一句:FPGA这么厉害,咋不上天呢?所以,有必要时刻申明:FPGA再厉害,再牛叉,目前看终究是一个co-processor的角色,在发挥作用时是离不开CPU的(即使是FPGA内嵌了CPU,从功能上来讲,仍然是FPGA部分和CPU部分要合理分工)。或者说,即便使用FPGA可以完成任何功能、满足任何需求,还有一个性价比的问题。FPGA必须有所为也有所不为。打个比方:姚明打篮球水平那是杠杠的,C罗踢足球水平那也是杠杠的。可是要是给俩人换一下呢?姚明踢足球也许还不如我呢,C罗打篮球也许还不如初中生呢。FPGA的加速能力要用对地方:让姚明去打篮球,让C罗去踢足球。
对于特定的数据库操作,目前大量的测试数据(不论是公司外部还是公司内部)都证实了FPGA在提高吞吐率和减少延时两个关键指标上,相对CPU都有巨大的优势。
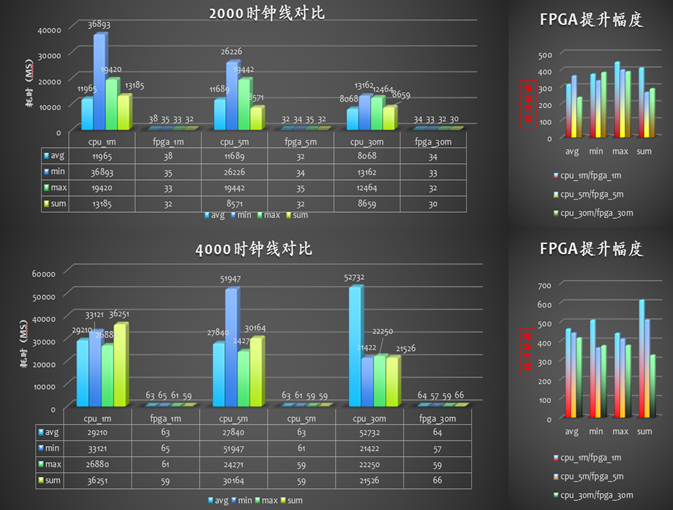
图6:左侧为使用CPU查询的耗时,右侧为FPGA查询耗时
(图片来源:《HITSDB数据库硬件加速业务落地总结篇》,作者:谋翼)
可以看到FPGA比CPU的平均查询响应速度快2个量级,查询的数据量越大,提升效果越明显。
3、AI
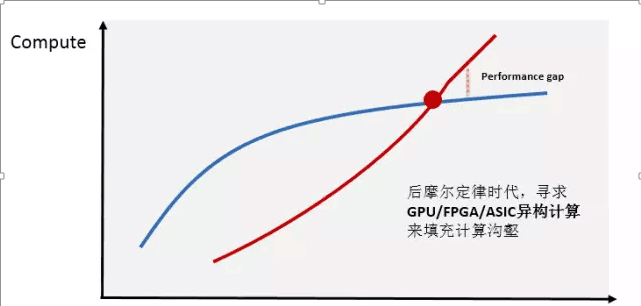
人工智能目前大热的概念就是深度学习,深度学习离不开各种xNN,也就是各种神经网络算法。神经网络是需要训练的,一般来说,神经网络节点越多、层次越深,需要的训练样本就越多、训练时间就越长。在训练领域,FPGA是拼不过GPU的,可是在推断领域,FPGA就可以大显身手了。在深度学习领域,只有大概5%~10%是训练场景,超过90%的是推断场景,尤其是各种移动终端的需求则几乎全部都是推断而非训练,因此FPGA相对于GPU所具有的的低功耗、低延时优势在移动端将体现的更加明显。最为关键的,目前AI的各种算法都处在一个高速迭代的阶段,FPGA的可编程灵活性的优势就更加明显。当然CPU也可以编程、也非常灵活,但是在各种xNN所需要的大量并行计算面前是力不从心的。下图简要表明了AI所需要的算力和CPU所能提供的算力之间出现的巨大Gap。
Data + Algorithm
图7:AI所需的巨大算力与CPU所能提供的算力之间的差距
以下这段借鉴(抄袭)微软Azure的Catapult V2的宣传材料,比较全面的罗列(鼓吹)了AI领域采用FPGA加速的各种好处:
Flexibility:可编程性天然适配正在快速演进的ML算法
- DNN、CNN、LSTM、MLP、reinforcement learning以及决策树等等
- 任意精度动态支持
- 模型压缩、稀疏网络、更快更好的网络
Performance:构建实时性AI服务能力
- 相较于GPU/CPU数量级提升的低延时预测能力(小样本batch情况下,帮微软严谨一下下)
- 相较于GPU/CPU数量级提升的单瓦特性能能力
Scale
- 板卡间高速互联IO
简而言之,FPGA是干xNN这活的绝佳选择。作为佐证,业界有公司设计出了CNN(卷积神经网络)的FPGA加速器,最终的结果和使用CPU比较,性能提升了16倍,延时降低了63倍,TCO降低了十倍,FPGA加速的价值已经无需赘言。
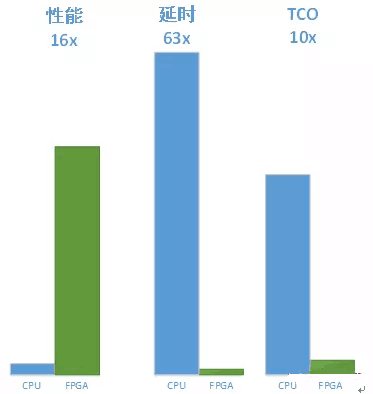
图8:CPU与FPGA分别实现googlenet v1模型性能对比
其他适合FPGA发挥加速能力的领域还有很多,就不一一列举了。
阿里集团相当多的业务,可以落入上面所说的五个类别。这些业务目前在CPU上运行的也很好。可是,恐怕多多少少已经遇到了瓶颈:需要堆叠越来越多的server(CPU)、客户开始抱怨产生一个结果需要越来越多的时间、成本的压力也越来越大,并且数据中心的功耗也越来越大,电费都够喝一壶的了。这些症状无一不说明:仗剑行走了多年江湖,该换换刀了,因为再不换刀,武林盟主的宝座就要易主了。FaaS平台就是名刀铸造厂,针对不同垂直行业的加速IP就是各种名刀。各路业务大佬,走过路过不要错过,到FaaS舜天平台来瞧一瞧,看一看,总有一款适合你。选好了,用好了,武林盟主的宝座妥妥的还是您的。FaaS则always默默地练着自己的内功,锤炼着更锋利的名刀,静静地right here waiting for you。当然,您也可以告诉FaaS您想要什么样的名刀,FaaS舜天平台给您量身定做,品质媲美男士西装界的Anderson-Sheppard。
六、针对典型应用场景FaaS舜天平台的设计特点—名刀为何是名刀
阿里云FaaS舜天平台的价值在于两点,一是通过建立完善的FPGA应用与开发生态,在IP Vendor和IP Consumer之间牵线搭桥,基于阿里云的强大能力,给客户提供性价比极高的算力;二是建立云上的FPGA开发环境与平台,降低FPGA设计、开发、验证的门槛,客户聚焦于设计本身,而无需考虑EDA工具、开发环境等对最终业务价值增值不多但又必须花费大量时间和成本去部署的事情。
针对上述价值,FaaS做了大量针对性的创新设计。
1、支持业界主流FPGA厂商
目前阿里云FaaS平台同时支持Intel和XILINX两家主流FPGA厂商的器件,阿里云也是全球FaaS产品线最齐全的公共云服务商。对于只想利用FPGA算力加速的客户来说,无需知道也不会知道底层提供加速的FPGA属于哪家厂商。但是对于使用FaaS进行设计、验证的客户来说,一般在设计之初就已经选定目标器件,设计也都是针对该器件进行优化,因此同时支持Intel和XILINX两家厂商的器件是非常有必要的。

图9:阿里云FaaS支持业界主流FPGA厂商
2、硬件设计创新
FaaS舜天平台的FPGA实例从F1、F2走到了F3。F3板卡采用了高密设计,PCB达到了26层,克服了信号完整性、布局布线和功耗散热等各种高难度挑战,单卡可以支持双VU9P芯片。业界大多都是单卡单芯片方案,从算力密度上是无法匹敌F3的。这种高密设计的好处是最高可以节省50%的物理机采购成本。
3、软件设计创新
阿里云FaaS舜天平台也有大量的软件创新:硬件抽象层支持Multi-boot烧写;支持用户逻辑功耗可监控;支持1/2/4片FPGA互联拓扑,且可动态配置拓扑形态;支持多种轻量级传输协议,传输效率高达95%;支持网络接口自适配;支持热升级;支持软硬件联合仿真。这些创新设计为用户提供了灵活、丰富的实例规格选择;大大简化了FPGA的高性价比算力输出的复杂度,同时极大的提升了FaaS服务的易用性。
4、安全设计创新
IP的安全是FaaS生态中的所有参与者都非常关心的首要问题之一。阿里云FaaS舜天平台从底层到上层、从硬件到软件做了大量的安全保障考虑和设计。首先,采取了强虚拟化隔离:IP源代码、发行包和部署环境对第三方是完全不可见的;其次,采用KMS加密实现用户IP的使用可审计、可计费,具体如下:
- 打好的AFU IP镜像,通过IP Agent加密并上传到IP Store
- IP Store的IP通过IP Agent传到NC宿主机,Host的Agent加载模块根据获取的秘钥解密并烧写进FPGA
FaaS还从软件、硬件和系统层面,针对目前已知的各种FPGA的攻击手段进行了防护,比如Hardware Trojan Insertion、Side Channel、PDN Attack、Voltage Drop-based Fault Attack等等。在最坏的情况下,F3也可以自行恢复初始工作状态,且从被攻击到自行恢复的整个过程都不会影响其他的FPGA和实例,确保了攻击的影响可消除、可恢复且严格控制在单芯片内。

图10:阿里云FaaS的安全设计
七、FaaS未来演进的一些思考—Think Wilder,Success Bigger
拉拉杂杂说了这么多,到了总结陈词的时间了。
FPGA从诞生到现在已有34年的历史,虽说应用的领域和场景极其广泛,从太空到深海,从军用到民用…但是直到2017年,全球市场容量也不过60亿美元。不知道有没有人算过具体的年复合增长率,但是用脚都可以想象肯定低的可怜。
异构计算实际上是FPGA发展历史长河里难得的机遇期,套用电影《张大民的幸福生活》里的一句台词来形容就是“春天终于到来了”。其强大的加速能力及其所能带来的业务和商业价值真的无须再多说,再说就成祥林嫂了。关键在于如何把这个加速能力便捷、快速、低成本的输出给客户,在短时间内给客户提供可观的价值,帮助客户以快打慢,从而形成自己的独特竞争优势。
阿里云的FaaS舜天平台基于为客户创造更多价值的理念,做了大量的努力和创新。未来也会在这个理念的指引下,继续完善和增强FaaS舜天平台的功能、可扩展性、稳定性和易用性;作为FPGA异构计算技术和商业的双重领导者,继续与业界IP伙伴和客户一起,努力打造健康的生态圈和产业链,携手共赢,共同拥抱FPGA异构计算的春天!
