前言
作为日志服务的采集 agent,Logtail 一般位于业务数据链路的前段,为链路中的后续部分输送数据,因此,它的正常运行显得至关重要。经过多年的实战打磨,Logtail 在稳定性和性能上都已经比较出色,在机器、网络等环境不变的情况下,配置完成后基本不再需要进行任何运维。但随着时间变化,环境不变基本是个伪命题,因此,对于一些敏感业务,仍旧存在着对 Logtail 进行状态监控和异常告警的需求。
本文将介绍如何通过日志服务提供的服务日志、告警以及 API 等功能来实现此需求。
Logtail 状态
总的来说,Logtail 状态分为以下三种:
-
Logtail 自身状态,包括:
- 是否正在运行?
- 心跳是否正常?
- 是否发生过重启?
- CPU、内存、网络流量?
- ...
-
Logtail 采集状态,包括:
- 当前应用的配置数量
- 当前打开的文件数量
- 原始数据的读取速率
- 解析成功和解析失败的日志量
- ...
-
Logtail 错误信息,所有非正常状态的汇总,包括:
- 读取文件失败
- 解析日志失败
- 发送失败
- ...
Logtail 会对以上所述的三类状态进行记录和上报(不包含用户数据,仅记录错误诊断所需要的内容),对于一些量比较大的状态,它会在发送前进行聚合,比如时间窗口内同种类型的错误信息将被聚合。
服务日志
为了获取之前提及的 Logtail 状态信息,需要先开通服务日志功能,具体的开通步骤可以参考此文档。在开通时,需要注意所选择的存储位置,后续操作需要在该位置对应的 project 内进行操作。 在开通时只要不勾选操作日志,则此功能完全免费。
在开通此功能后,存储位置对应的 project 下会增加一个名为 internal-diagnostic_log 的 logstore,日志服务会将相关的 Logtail 状态信息分发到该 logstore,其中包含了多种类型的日志,为了避免混淆,不同类型的日志具有不同的主题(__topic__ 字段)。在本文中,我们仅关注其中的三种数据,它们的主题分别是 logtail_status、logtail_profile 以及 logtail_alarm。
除了 logstore 以外,对应 project 下还会创建两个名为 Logtail采集统计 和 Logtail运行监控 的仪表盘,其中包含一些预先创建的图表,能够帮助我们了解当前的全局状态。
状态监控及告警配置
在简单地介绍了服务日志后,我们接下来将对如何使用服务日志进行讲解。从性质上来看,服务日志和用户日志没有区别,因此,基于服务日志进行监控及告警也需要通过日志服务的 日志查询 和 告警 两个功能实现:先通过日志查询功能编写查询语句,从服务日志中分析提取我们需要的信息,然后对查询语句配置告警。
基于预设仪表盘配置告警
我们知道,仪表盘上的每个图表都关联了对应的查询语句,因此,如果预设的采集统计和运行监控两个仪表盘中已经有符合你要求的图表,你完全可以基于它关联的查询语句进行告警配置。
以下我们以 Logtail运行监控 仪表盘为例,介绍一下相关的操作步骤。如下图所示,该仪表盘整体上分为基础信息、采集错误以及资源占用三部分。


原始数据流量监控
在实际情况中,很多业务的流量都具有很明显的周期性,从而在正常情况下,其关联的日志或数据量也具有相应的周期性。基于这一特点,同比同一时段,突增或者突减的流量都可以在一定程度上视为异常。
仪表盘中预设了「原始数据流量」这一项,我们可以基于它配置告警对该指标进行监控,操作步骤如下:
- 鼠标悬停到该项数值上方,接着悬停在右上角出现的省略号上,点击弹出菜单的「查看分析详情」跳转到查询页面。
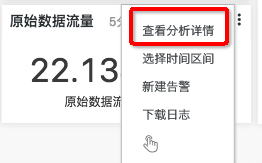
- 查询页面中给出了该图表对应的查询语句,可以看到,该查询利用了同比函数对 logtail_status 日志中的 send-bytes-ps 字段进行了分析。并且,查询范围选择了 5 分钟,同比为 86400(一天),即比较一天前同一时间范围内的查询结果。
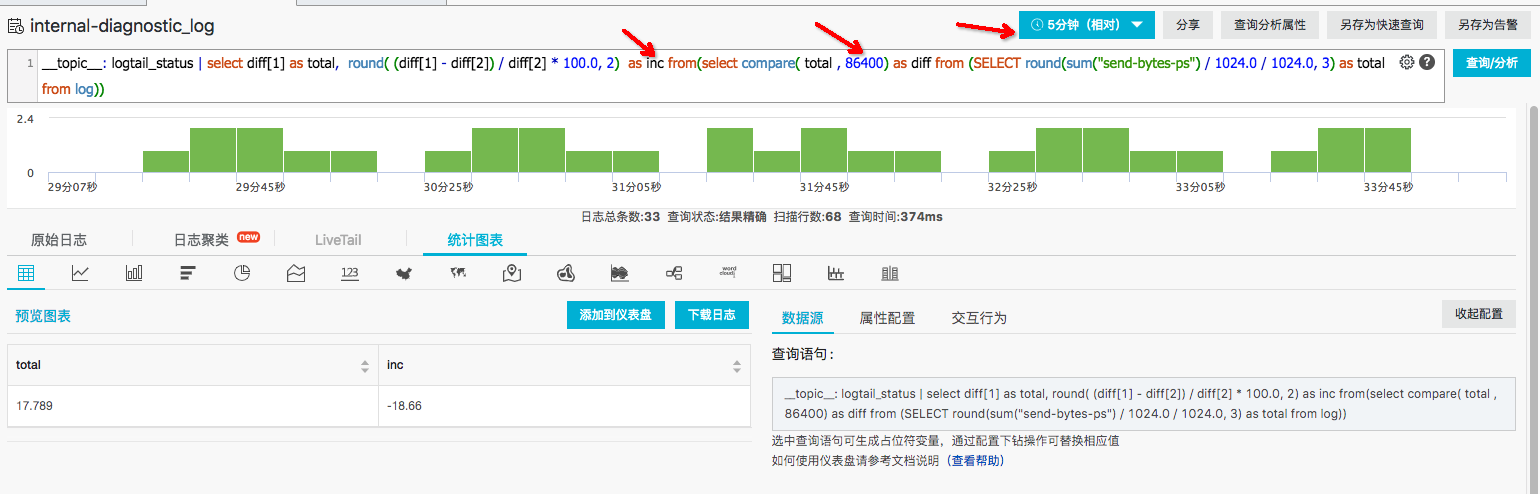
- 查询结果返回的 inc 字段表示同比发生的变化,我们可以对其设置告警,当流量同比增长超过某个阈值时,进行告警。
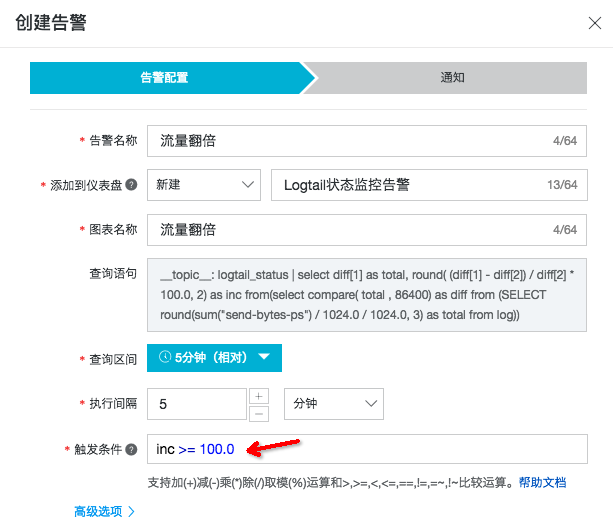
除此之外,我们还可以根据业务的实际情况,修改查询语句中的一些参数,包括查询范围、同比时间、告警阈值等。
采集延迟监控
接下来我们看看对采集延迟的监控,这对于延迟敏感的业务很有帮助。通过类似地步骤,查看「采集延迟」这一图表对应的查询语句,如下图所示。

可以看到,此处该语句对 logtail_alarm 日志进行了分析,当采集进度落后并持续一段时间后,Logtail 会向服务端发送 READ_LOG_DELAY_ALARM 警告,因此,通过统计该警告的数量,即可得知当前是否有采集延迟的情况。查询语句中使用了 COALESCE 和 approx_distinct 函数以加快运算。
类似地,我们可以为该查询语句创建告警,当出现采集延迟警告时进行告警,如下图所示。

关于采集延迟,还可以借助 Logtail采集统计 仪表盘中的「采集延迟」和「平均采集延迟」两个图表来查看具体延迟的数据量大小。

CPU 监控
为了避免 Logtail 占用过多资源影响业务,我们有时候需要对它的 CPU 利用率进行监控。预设的仪表盘中提供了「平均CPU」这一图表,我们可以基于它来实现此监控需求,它的查询语句如下。

可以看到,其中使用了 avg 来计算平均值,类似地,我们可以根据需要把 avg 替换成 max/min 等其他聚合函数,在设置告警时,对 total 设置所需的比较阈值即可。
自定义查询语句
除了基于预设仪表盘以外,我们也可以通过自行编写查询语句来实现所需的目标。在此之前,我们需要先了解 logtail_status、logtail_alarm 以及 logtail_profile 这三类日志中各个字段的含义。
以下我们简单地举一些使用这些日志字段的例子。
使用 project/logstore 字段
这三类日志都拥有一个 project 字段,因此,我们可以利用它来筛选出所关注的 project,比如说一个 Logtail 节点同时采集了多个 project 下的配置,如果有些 project 下的数据重要程度并不是特别高,则可以使用 not project:xxx 这样的查询语句将它们过滤掉。类似地,有些日志提供了 logstore 字段,能够帮助我们进一步地缩小关注范围。
使用 alarm_count 字段
在 logtail_alarm 日志中,有一个 alarm_count 字段,它表示在时间窗口(即相邻两次上报之间)内该类型错误的数量,我们可以基于它进行一些监控。
以 SEND_QUOTA_EXCEED_ALARM 为例,它表示当前日志写入流量超出限制。对于正常业务来说,偶尔的流量突增可能会带来少量的此错误,因此可以忽略,但是一旦短时间内此错误数量(alarm_count)超过了一定阈值,则说明当前可能存在其他的问题,比如:
- 业务出现问题,大量错误日志引起写入流量激增,需要排查问题。
- 其他业务和此业务共享 project,占用了 project 整体的 quota,需要上调 project 级别的 quota。
- ...
机器组状态监控(Logtail 心跳)
Logtail 上报服务日志采用的是匿名方式,无需鉴权,只要网络正常即可上报,但网络正常的情况下依旧可能因为鉴权等原因导致心跳失败,因此,我们无法通过服务日志来判断 Logtail 的心跳是否正常。
对于此需求,目前比较好的办法是通过机器组状态 API 来实现,该方法的基本思路是周期性地调用机器组状态 API,获取所监控的机器组下各个机器的最近心跳时间,然后与当前时间进行比较,当超过一定范围时,判定心跳超时。
以下是基于 CLI 的 Python 实现(出于篇幅,错误处理已省略)。
import commands
import time
import json
def ListMachines(projectName, machineGroupName):
cliCmd = 'aliyunlog log list_machines --project_name={} --group_name={}'.format(
projectName, machineGroupName)
status, result = commands.getstatusoutput(cliCmd)
return json.loads(result)
def AssertLogtailHeartbeat(projectName, machineGroupName, threshold):
machines = ListMachines(projectName, machineGroupName).get('machines', None)
if machines is None:
return []
currentTimestamp = int(time.time())
print 'Current timestamp', currentTimestamp
failedMachines = []
for machine in machines:
if currentTimestamp - machine['lastHeartbeatTime'] > threshold:
failedMachines.append(machine)
return failedMachines
if __name__ == '__main__':
"""
Usage: python monitor.py <project_name> <machine_group_name> <threshold_in_seconds>
"""
import sys
failedMachines = AssertLogtailHeartbeat(sys.argv[1], sys.argv[2], int(sys.argv[3]))
print 'Failed machines count: {}'.format(len(failedMachines))
for m in failedMachines:
print 'IP: {}, last heartbeat time: {}'.format(m['ip'], m['lastHeartbeatTime'])参考以上代码,根据需要配置合理的阈值(公有云上 Logtail 默认心跳周期为 30s 左右,可适当增大阈值至 1-3 分钟),然后定期执行即可实现对机器组状态的监控。对于定期执行的环境,可以使用函数计算的定时触发进行构建。
除了检查以外,我们还需要在发现失败机器时进行告警。对于这个需求,我们无需自行构建一套告警系统和通知渠道,可直接通过以下步骤复用日志服务的告警功能:
- 创建一个专门用于告警的 logstore。
- 当检查发现失败机器时,利用 CLI/SDK/API 向该 logstore 中写入一条日志(CLI 可以参考 put_logs 命令)。
- 为该 logstore 配置告警,当发现日志时(查询语句
* | select count(*) as c,告警表达式c > 0),进行告警。
至此,我们完成了一个通过 CLI 访问日志服务 API 来实现对机器组状态监控的示例,你可以进一步地修改这个示例来实现对多个机器组乃至特定机器状态的监控。
小结
在本文中,我们首先简要介绍了服务日志中与 Logtail 状态相关的一些日志类型,然后从操作步骤上讲解了如何基于预设仪表盘以及自定义查询语句实现对 Logtail 的状态监控并设置异常告警,最后,我们补充了通过机器组状态 API 实现对 Logtail 心跳进行检查的示例。
更多阅读
- 服务日志功能简介
- Logtail 日志采集错误类型
- 日志服务 CLI 使用文档
- 欢迎加入钉钉群进行讨论交流